DashAttention makes sparse long-context attention differentiable
DashAttention uses adaptive sparse selection to keep hierarchical attention differentiable and improve long-context efficiency.
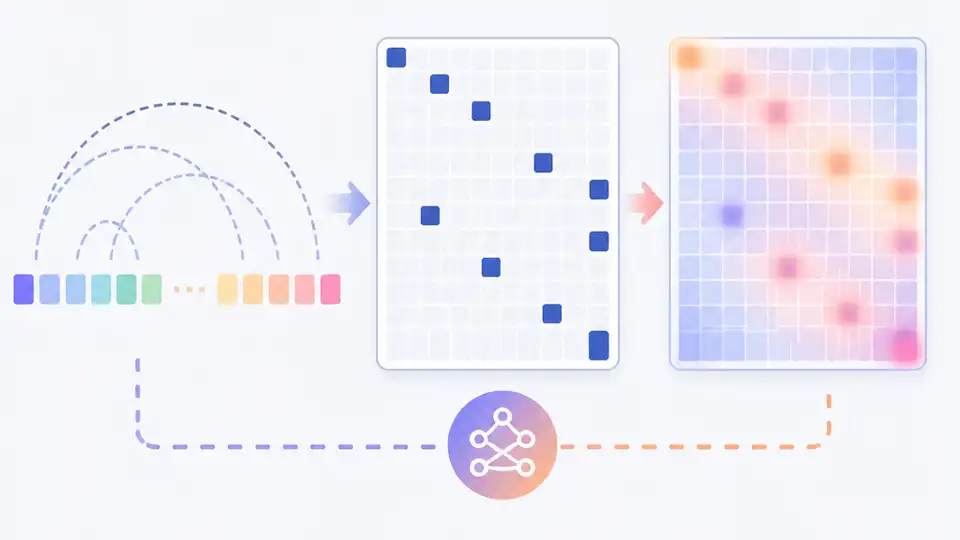
DashAttention makes hierarchical long-context attention adaptive, differentiable, and more efficient.
- Research org: Unspecified in arXiv abstract
- Core data: 75% sparsity
- Breakthrough: Uses α-entmax to choose a variable number of KV blocks
Long-context attention has a familiar tradeoff: you can look at everything, or you can prune aggressively and hope you kept the right tokens. This paper argues that the usual top-k hierarchical approach is too rigid for that job, because it assumes every query needs the same number of relevant blocks and it blocks gradient flow between sparse selection and dense attention.
To address that, the authors introduce DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention, a two-stage attention scheme that makes the first stage adapt to the current query instead of forcing a fixed top-k cutoff. The result is a hierarchy that stays fully differentiable, while still being sparse enough to reduce cost.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Modern hierarchical attention methods such as NSA and InfLLMv2 work in two steps. First, they score key-value blocks coarsely and pick the top-k candidates. Then they run fine-grained softmax attention over the selected tokens. That sounds reasonable, but it has two structural problems.
First, top-k is rigid. It assumes the same number of relevant tokens for every query, even though real queries vary a lot in how much context they need. Second, the top-k choice is discrete, so it prevents gradient flow between the sparse stage and the dense stage. In practice, that makes the hierarchy less flexible than it could be.
The paper’s core claim is that this matters for long-context modeling. If the sparse stage is too blunt, the model can become dispersive, meaning attention gets spread in a way that hurts the ability to focus on the right information over long ranges.
How DashAttention works in plain English
DashAttention replaces fixed top-k block selection with the adaptively sparse α-entmax transformation. In plain terms, α-entmax can produce sparse outputs while still allowing the number of selected blocks to vary with the query. Some queries may need more blocks, others fewer, and the method can express that directly.
That sparse first stage then serves as a prior for the second stage, where softmax attention is applied more finely. Because the whole hierarchy remains differentiable, the sparse and dense parts can train together instead of behaving like two disconnected systems.
Compared with a standard top-k pipeline, this is the important shift: the model is not just “choosing fewer tokens.” It is learning how many blocks to keep, based on the query, while preserving a gradient path through the entire attention hierarchy.
What the paper actually shows
The abstract reports that DashAttention is non-dispersive, and that this translates into better long-context modeling ability. The authors say this is one reason it compares well to existing hierarchical attention methods.
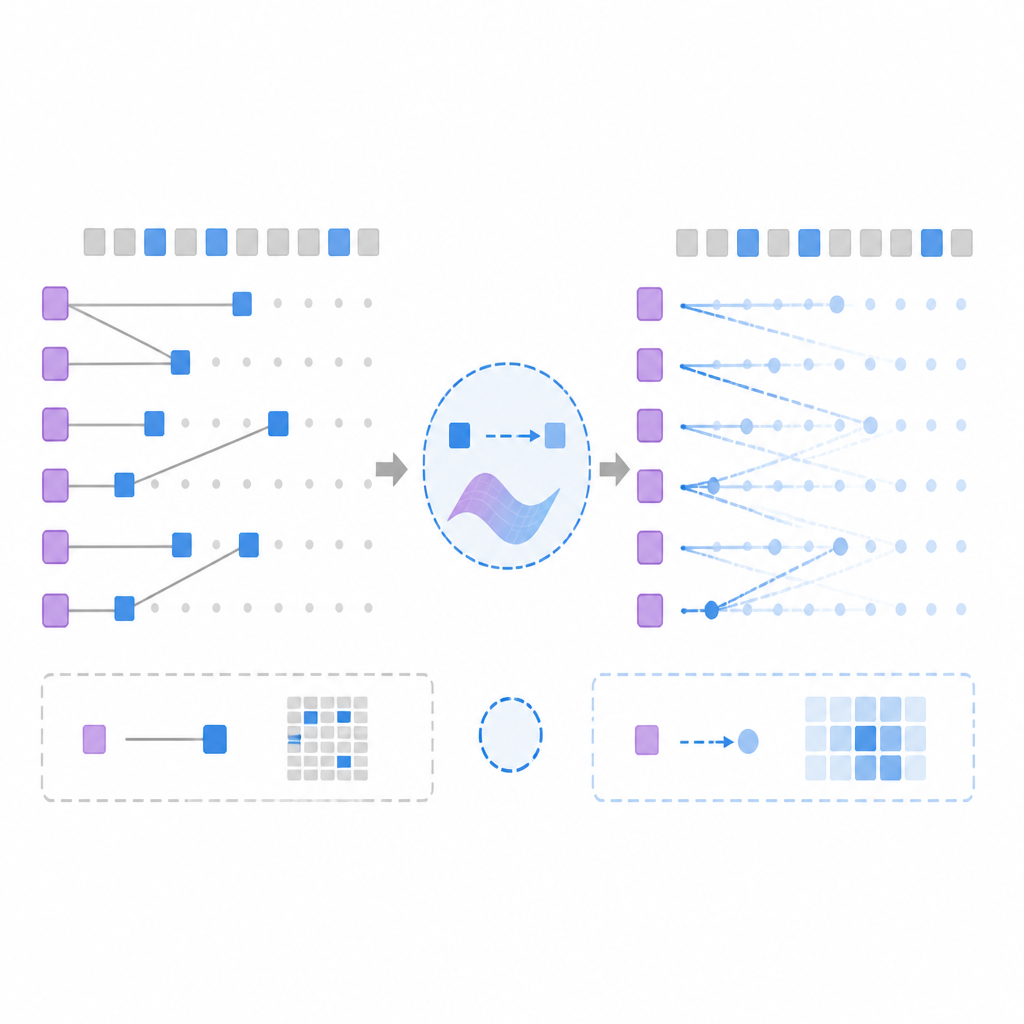
On experiments with large language models, DashAttention achieves comparable accuracy to full attention at 75% sparsity. It also shows a better Pareto frontier than NSA and InfLLMv2, especially in high-sparsity regimes. The abstract does not list the full benchmark suite, task names, or exact accuracy numbers, so those details are not available from the source text.
The implementation angle matters too. The authors provide an efficient GPU-aware Triton implementation, and they report that it achieves a speedup of up to over FlashAttention-3 at inference time. The abstract does not include the exact multiplier, so the precise speedup figure is not stated there.
Why developers should care
If you are building LLM systems that need long-context inference, the practical question is not just whether attention can be made sparse, but whether sparsity can be made smart enough to avoid breaking quality. DashAttention is interesting because it tries to solve that exact problem without giving up differentiability.
That makes it relevant for anyone tuning the cost-quality curve of attention layers. A method that can keep accuracy close to full attention while operating at 75% sparsity is the kind of thing that can matter in production settings where memory bandwidth, latency, and context length all compete.
The GPU-aware Triton implementation is also a useful signal. Research ideas are one thing; an implementation that is explicitly designed for the GPU path is more likely to be usable by practitioners who care about inference performance rather than just model design.
Limitations and open questions
The abstract leaves out a lot of details that engineers would want before adopting the method. We do not get the exact benchmark suite, the model sizes, the datasets, or the full latency numbers. We also do not know from the abstract how DashAttention behaves across different architectures or whether the gains hold outside the reported LLM experiments.
There is also a broader systems question: hierarchical sparse attention can reduce cost, but the real benefit depends on kernel quality, hardware, and sequence length. The paper says the Triton implementation is efficient and GPU-aware, but the extent to which that generalizes across deployments is not stated in the abstract.
Even so, the direction is clear. The paper is trying to move sparse attention from a fixed pruning heuristic toward a learned, query-dependent mechanism that stays trainable end to end. For long-context workloads, that is a meaningful design change, not just a minor optimization.
- DashAttention replaces fixed top-k selection with adaptive α-entmax sparsity.
- The method keeps sparse and dense attention stages fully differentiable.
- The abstract reports comparable full-attention accuracy at 75% sparsity, but no full benchmark table.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10