DashAttention 讓稀疏長上下文可微
DashAttention 把長上下文的分層稀疏注意力改成可微、可自適應的選擇機制,讓模型在 75% 稀疏下仍能維持接近全注意力的表現。
DashAttention 把長上下文分層注意力做成可微、可自適應的稀疏選擇,讓模型在高稀疏下仍能保住效能。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:75% sparsity
- 突破點:α-entmax 自適應選塊
長上下文注意力一直有個老問題:你可以看得很廣,但成本高;你也可以先砍掉一大半內容,但很容易把關鍵資訊一起丟掉。這篇論文要處理的,就是這個「省算力」和「保品質」之間的拉扯。
作者認為,現有的分層式稀疏注意力,像是先粗選 KV block、再做細粒度 softmax 的流程,最大的問題不在於「不夠快」,而在於「太硬」。因為它通常靠 top-k 做離散選擇,等於預先假設每個 query 都只需要固定數量的相關區塊。實際上,不同 query 對上下文的需求差很多,這種固定門檻會限制模型表現。
這篇論文提出的 DashAttention: Differentiable and Adaptive Sparse Hierarchical Attention,就是想把這個流程改成更靈活的版本。它保留分層注意力的效率優勢,但把第一階段改成可自適應、可微分的稀疏選擇,讓 sparse 和 dense 兩段可以一起訓練,而不是像兩個彼此切開的模組。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
先講白話版。長上下文模型最怕的不是「沒有注意力」,而是「注意力太分散」。如果前面那層粗選做得不準,後面的精細注意力就只能在錯的候選集合裡找答案。這時候模型看起來還在運作,但其實已經偏掉了。

傳統 top-k 分層注意力有兩個結構性限制。第一,它不會因為 query 不同就改變保留數量。第二,top-k 是離散操作,梯度沒辦法順暢穿過 sparse selection 與 dense attention 的邊界。結果就是,模型雖然有「先篩再算」的設計,卻不一定學得到真正適合自己的篩法。
DashAttention 的出發點,就是把這個硬切的流程改成可學習的流程。它不是單純把 token 砍少,而是讓模型自己決定該保留多少個 KV block,並且維持整條路徑都能反向傳播。
方法怎麼運作
DashAttention 的核心是兩階段結構。第一階段不是固定 top-k,而是用 α-entmax 來做稀疏選擇。這個轉換的重點在於,它可以產生稀疏輸出,但保留的 block 數量可以隨 query 而變,不需要每次都死守同一個 k。
換句話說,有些 query 需要更多上下文,系統就能保留更多 block;有些 query 只需要少量資訊,就能更果斷地稀疏化。這讓第一階段不再只是粗暴過濾,而是變成一個依照內容調整的 prior。
第二階段則是在被選出的區塊上做更細的 softmax attention。因為前面的稀疏選擇本身是可微的,所以 sparse 與 dense 不再是互相獨立的兩段式流程,而是可以一起優化的整體。這就是 DashAttention 跟傳統 top-k pipeline 最大的差別。
論文用的不是「更少 token」這種單一目標,而是「可變數量的 block 選擇 + 可微分的分層注意力」。這也解釋了為什麼作者會特別強調它是 adaptive、differentiable,而且還是 hierarchical。
論文實際證明了什麼
根據摘要,作者主張 DashAttention 具有 non-dispersive 的特性,也就是注意力不會過度發散。這點被用來解釋它在長上下文建模上的表現會更穩。
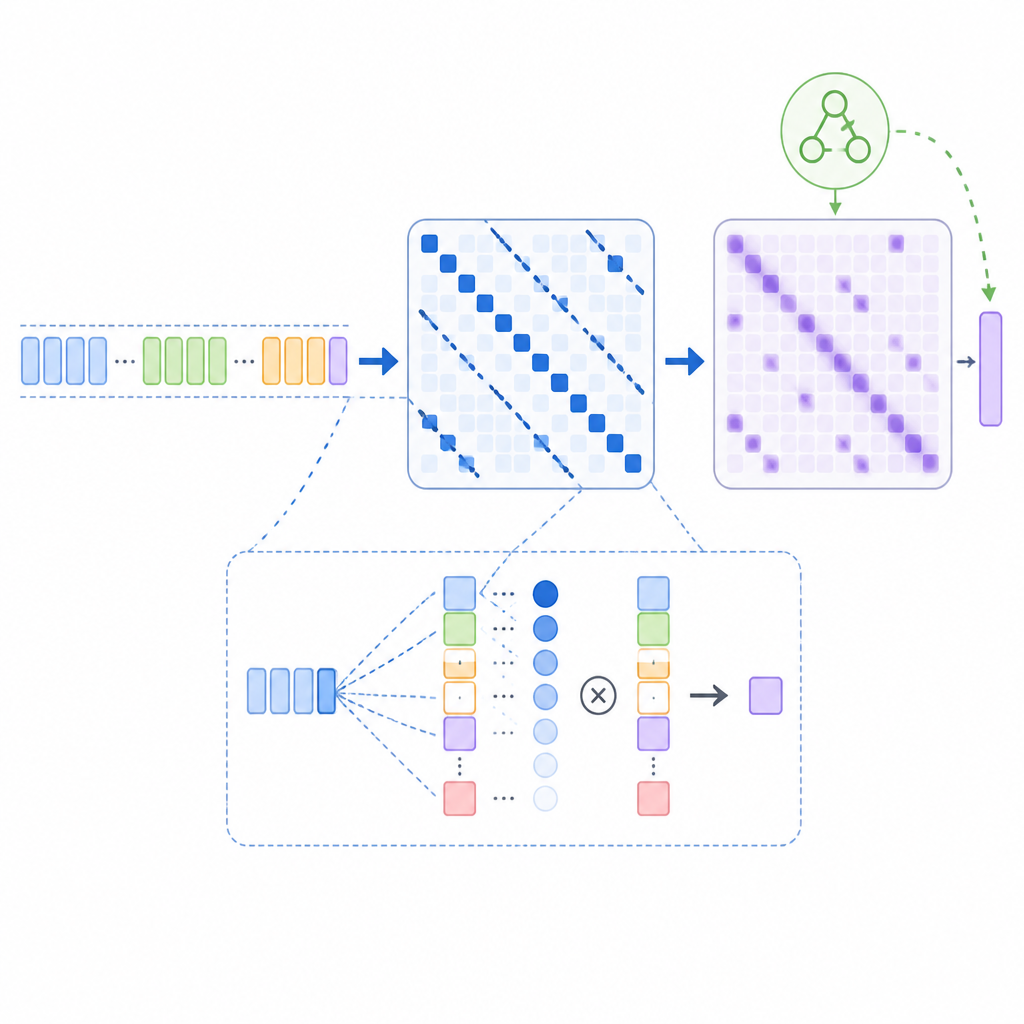
在大語言模型實驗中,摘要寫到 DashAttention 在 75% sparsity 下,能做到和 full attention 相近的準確度。它也比 NSA 和 InfLLMv2 有更好的 Pareto frontier,尤其是在高稀疏區間。這代表它不是只在「省算力」這一端有優勢,而是能把效能與效率的平衡往更好的方向推。
不過,這裡也要講清楚限制:摘要沒有公開完整 benchmark 細節。它沒有列出完整測試集、任務名稱、模型尺寸,也沒有把精確 accuracy 數字全部攤開。所以從摘要能確定的是趨勢,不是完整的實驗圖表。
另外,作者還提供了 GPU-aware 的 Triton 實作。摘要指出,這個實作在 inference 時的速度表現,甚至能優於 FlashAttention-3。不過摘要沒有給出確切倍率,所以我們只能說它有速度優勢,不能替它補上沒寫出的數字。
對開發者代表什麼
如果你在做長上下文 LLM 系統,真正的問題從來不是「能不能稀疏」,而是「稀疏會不會把品質砍壞」。DashAttention 的價值,在於它試圖把這兩件事一起解,而不是先犧牲一邊再補另一邊。
這對調整 attention 層的成本曲線很有意義。75% sparsity 還能維持接近 full attention 的結果,至少在論文摘要的描述裡,已經顯示它不是那種單純靠剪枝換速度、最後品質掉一大截的方法。對需要長上下文推理、又受限於記憶體頻寬與延遲的場景,這種設計方向很有吸引力。
更實際的一點是,作者把 GPU-aware Triton implementation 一起端出來。對開發者來說,這通常比單純的算法概念更重要。因為 attention 類方法最後能不能落地,常常不是看論文圖畫得漂不漂亮,而是看 kernel、硬體和序列長度能不能配合。
還有哪些限制與問題沒回答
摘要也留下不少工程師會想追問的空白。首先是 benchmark 資訊不足。你看不到完整數據集、模型規模、測試條件,也不知道它在不同任務上的表現是否一致。這讓它很難直接被拿來和其他方法做嚴格對照。
其次,分層稀疏注意力的實際收益很吃系統條件。kernel 寫得好不好、GPU 架構、序列長度、部署方式,都會影響最後的速度和成本。摘要雖然說 Triton 實作很有效率,但沒有說明這些優勢在不同環境下能不能穩定重現。
還有一個問題是泛化性。摘要只提到 large language models 的實驗結果,但沒有說跨架構、跨任務,這套 adaptive sparse selection 是否都能維持同樣的 Pareto 改善。這些都需要看完整論文或後續實作驗證。
即便如此,這篇的方向還是很清楚:它想把 sparse attention 從固定規則,推向可學習、可變動、端到端可訓練的機制。對長上下文模型來說,這不是小修小補,而是把稀疏化從「硬切」改成「會判斷的選擇」。
總結
DashAttention 證明了一件事:長上下文注意力不一定要在「全看」和「硬砍」之間二選一。它可以在保留分層效率的同時,讓稀疏選擇變成可微、可自適應的流程。
從摘要能看到的結果是,這種設計在 75% sparsity 下仍能維持接近 full attention 的表現,並且在高稀疏區間比 NSA 和 InfLLMv2 更有優勢。對開發者來說,這代表稀疏注意力還有繼續往「更聰明」方向演進的空間,而不只是單純把 token 砍少。
- DashAttention 把固定 top-k 改成 α-entmax 自適應選塊。
- 它讓 sparse 與 dense attention 保持可微分,方便端到端訓練。
- 摘要只公開了趨勢與 75% sparsity,沒有完整 benchmark 表格。