Tag
LLMs
LLMs are the core engine behind modern generative AI, powering chat assistants, enterprise agents, ad systems, and content generation. This tag also covers bias, alignment, jailbreak resistance, and internal model behavior, all of which shape reliability in real deployments.
30 articles

RiVER trains LLMs without ground-truth answers
RiVER shows LLMs can improve from score-based tasks without ground-truth answers by calibrating rewards from execution feedback.
RevengeBench tests reverse-engineering game policies
RevengeBench tests whether LLMs can reconstruct hidden game policies from behavior and improve with custom probes.
LLMs work by predicting the next token
A clear guide to how LLMs are trained, tuned, and used, with 5 practical pieces of the model pipeline.
Can LLMs Write Correct TLA+ Specs?
A benchmark of 30 LLMs shows they rarely generate semantically correct TLA+ specs from natural language.

LLMs stumble on counterintuitive probability
A benchmark finds LLMs are strong on standard probability problems but falter on counterintuitive ones.

Why small businesses should use AI for admin, not everything
Small businesses should use AI for administrative work, not core judgment or customer trust.

Mistral AI’s rise from startup to $14B valuation
Mistral AI, founded in 2023, built open-weight models fast enough to reach a 2025 valuation above $14 billion.
StreamMA cuts multi-agent reasoning latency
StreamMA streams reasoning steps between agents to cut latency and improve accuracy in multi-agent systems.

STRIDE tracks training data influence faster
STRIDE turns training data attribution into sparse recovery from subset perturbations and cuts attribution cost by 13×.
Why RAG Beats Prompting for Private Data
RAG is the right architecture for answering questions over private, changing data.

AI Code Review Explained: Benefits and Limits
IBM explains how AI code review speeds up pull requests, catches bugs, and still needs human judgment for context.

How to Add AI Code Review to Pull Requests
Set up AI code review in pull requests to catch bugs earlier and speed up human review.

Prompt engineering turns vague asks into usable outputs
I break down prompt engineering into practical patterns, with a copy-ready template for better LLM outputs.
21 domain LLMs turn generic AI into specialists
I break down 21 specialty LLMs and turn that list into a copy-ready playbook for picking, tuning, and shipping one.

PEFT-Bench compares fine-tuning methods fairly
PEFT-Bench standardizes how to compare PEFT methods across 27 NLP datasets and 7 techniques.

Code Becomes the Agent Harness
This survey reframes code as the runtime layer that connects agent reasoning, actions, memory, and verification.
DashAttention makes sparse long-context attention differentiable
DashAttention uses adaptive sparse selection to keep hierarchical attention differentiable and improve long-context efficiency.

5 shifts in LLMs from the last six months
5 shifts explain why LLMs changed fast over six months: better coding agents, stronger open models, and new local workflows.

AutoTTS lets LLMs discover test-time scaling
AutoTTS turns test-time scaling into an environment search problem, letting LLMs discover cheaper reasoning strategies automatically.
Why small language models should replace LLM-first enterprise AI
Enterprise AI should default to small language models, not giant LLMs, because they are cheaper, faster, and safer for most workflows.
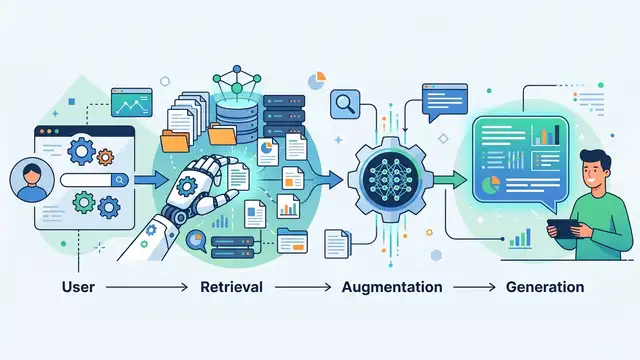
Retrieval-Augmented Generation, Explained Simply
RAG lets large language models pull fresh facts from documents before answering, which cuts hallucinations and adds citations.
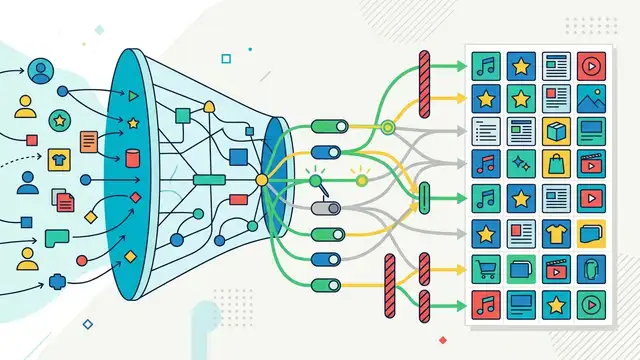
Selective LLM Regularization for Recommenders
A paper on using selective LLM-guided regularization to improve recommendation models without overhauling the recommender stack.

When LLMs Stop Following Procedural Steps
A diagnostic benchmark shows LLMs lose procedural fidelity as step counts grow, even when the arithmetic stays simple.

How LLMs Stereotype Global Majority Nationalities
A study finds widely used LLMs produce harmful, one-sided narratives about national origins, especially when US cues appear in prompts.

How LLMs encode harmful behavior internally
A pruning study suggests harmful output lives in a compact, shared weight set—helping explain jailbreak brittleness and emergent misalignment.

ChatGPT Ads Are Getting More Uniform
New data from 40,000 ad placements shows ChatGPT ads are becoming shorter, clearer, and more standardized as OpenAI optimizes for conversion.
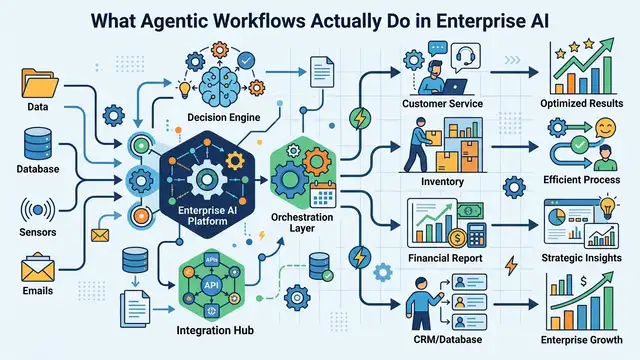
What Agentic Workflows Actually Do in Enterprise AI
Agentic workflows let AI agents plan, act, and adapt with little human input, changing how teams handle support, ops, and data work.

Duplicate Prompts Can Lift Accuracy Fast
A Google study found repeating prompts once improved 47 of 70 model-benchmark pairs, with one task jumping from 21% to 97%.
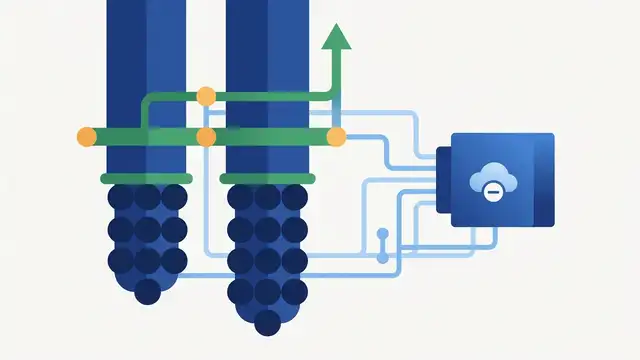
Universal YOCO aims to scale depth without cache bloat
YOCO-U mixes recursive computation with efficient attention to scale LLM depth while keeping inference overhead and KV cache growth in check.

What AI Agents Are and How They Work
AI agents combine LLMs, memory, tools, and planning. IBM says they can call APIs, search data, and coordinate tasks autonomously.