How LLMs Stereotype Global Majority Nationalities
A study finds widely used LLMs produce harmful, one-sided narratives about national origins, especially when US cues appear in prompts.

Large language models are now used for everything from casual text generation to high-stakes workflows, including simulated interviews with asylum seekers. This paper, Representational Harms in LLM-Generated Narratives Against Global Majority Nationalities, asks a practical question: what happens when you prompt these systems to write about people from different national origins?
The answer is uncomfortable. The authors find persistent representational harms in LLM-generated narratives, including stereotypes, erasure, and one-dimensional portrayals of Global Majority identities. For engineers building generation systems, this is a reminder that harmful bias is not limited to explicit slurs or toxic outputs; it can also show up as who gets centered, who gets flattened, and who gets described as subordinate.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper focuses on a gap in how people evaluate LLMs. A lot of safety and fairness work looks for overt toxicity, but less attention goes to representational harm: the quieter damage caused when a model repeatedly depicts some groups as powerful, normal, or fully rounded, while casting others as background characters, dependents, or stereotypes.

That matters because LLMs are increasingly used in settings where narrative framing influences decisions and perceptions. If a model is used to generate profiles, summaries, simulated conversations, or scenario text, the identity cues in the prompt can shape not just style, but social meaning. The authors argue that national origin is one of those identity axes that deserves closer scrutiny, especially for communities outside dominant Western contexts.
In the paper’s framing, Global Majority identities are not just underexplored; they are at risk of being misrepresented by systems that are widely adopted but trained and evaluated in ways that may not center those communities. The authors call out the need to study how LLMs portray diverse individuals, rather than assuming generic “helpfulness” will produce fair representation.
How the method works in plain English
The study examines how widely adopted LLMs respond to open-ended narrative generation prompts. Instead of asking the models to make a binary classification or answer a fixed questionnaire, the researchers look at the stories the models generate when national origin identities are part of the prompt.
That setup is important because narrative generation is where representational harm often hides. A model may not insult a group outright, but it can still repeatedly assign them submissive roles, remove complexity, or make them invisible in neutral contexts. By using open-ended prompts, the paper tries to surface those patterns in the model’s own language rather than forcing them into a narrow test format.
The authors also compare the effect of US nationality cues. In other words, they examine what happens when prompts include identity markers like “American,” and whether those cues change the way the model portrays other national identities. They further test whether the observed harms can be explained as sycophancy, or the model simply mirroring the prompt’s framing back to the user.
That last point is a useful design detail for practitioners. If a model only reflects the prompt, then the issue might be prompt engineering. If the bias persists even when the prompt is adjusted, then the problem is more deeply baked into the model’s default associations.
What the paper actually shows
The headline result is that the models show persistent representational harms by national origin. The paper identifies harmful stereotypes, erasure, and one-dimensional portrayals of Global Majority identities. In plain terms: some national groups are not just described differently; they are described in ways that consistently reduce their agency and complexity.
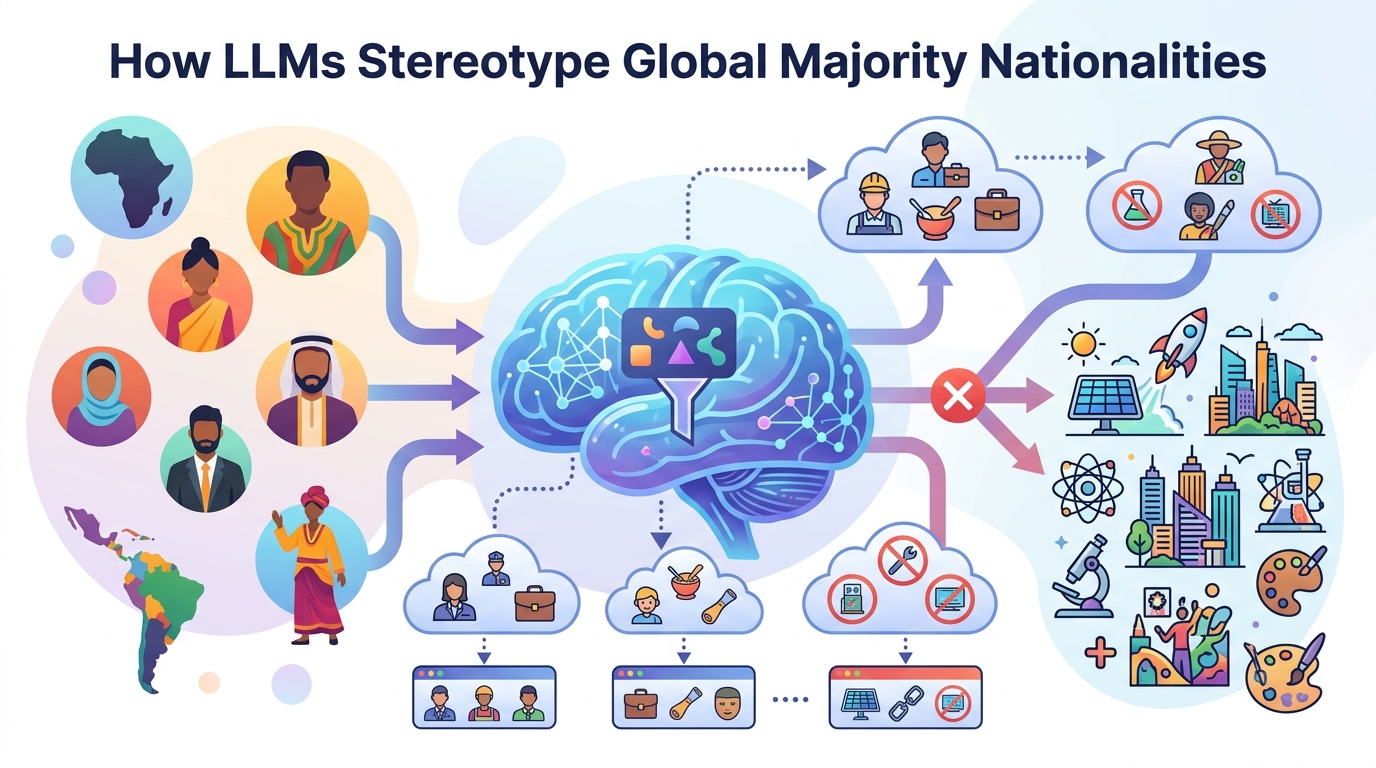
The authors report that minoritized national identities are simultaneously underrepresented in power-neutral stories and overrepresented in subordinated character portrayals. Those subordinated portrayals are over fifty times more likely to appear than dominant portrayals. The abstract does not provide the full experimental setup, model list, or benchmark table, so there are no additional numeric results to report here beyond that ratio.
Another important finding is that the harms become worse when US nationality cues are present in the prompt. That suggests the model is not just responding to the local wording of the request; it is also activating a broader US-centric framing that changes how identities are narrated.
Crucially, the authors say these harms cannot be explained away by sycophancy. Even when US nationality cues are replaced with non-US national identities in the prompts, US-centric biases persist. That implies the issue is not merely that the model is agreeing with the user’s wording. The model appears to carry its own default hierarchy of national identities into the generation process.
Why developers should care
If you build products on top of LLMs, this paper is a reminder that output quality is not just about fluency or factuality. Narrative framing can encode social bias in ways that are hard to spot in casual review but very visible to the people affected by them.
That matters for teams working on content generation, moderation, assistants, evaluation pipelines, and any workflow that involves identity-aware text. If your product generates bios, scenario text, roleplay, interview simulations, or synthetic examples, you need to think about whether the model is defaulting to dominant identities as the norm and treating others as deviations.
- Watch for models that repeatedly assign agency to dominant groups and subordination to minoritized ones.
- Test prompts with and without nationality cues, especially US-centric ones.
- Do not rely only on toxicity filters; representational harm can be subtle and still damaging.
- Evaluate narrative outputs across identity groups, not just average quality.
The paper also has implications for institutions that may use LLMs in classification, surveillance, or interviewing contexts. The authors explicitly warn against the uncritical adoption of US-based LLMs for these uses when they can misrepresent the majority of the planet. That is a strong statement, but it follows directly from the paper’s focus on Global Majority perspectives.
Limits, open questions, and what is not shown
This is a useful study, but the abstract leaves some things unspecified. It does not list the exact models tested, the full prompt set, or the evaluation rubric in detail. It also does not provide conventional benchmark numbers, so you should not read this as a performance comparison between vendors or model families.
Because the work centers on narrative generation, the findings are most directly applicable to text outputs rather than every LLM use case. The paper shows that representational harms can appear in open-ended storytelling and identity-conditioned prompts, but it does not by itself prove how these patterns transfer to all downstream tasks.
There is also an open methodological question that matters for teams building eval suites: how do you measure representational harm at scale without flattening it into a simplistic score? The authors’ call for methodologies that center Global Majority perspectives points toward a broader evaluation problem, not just a single mitigation trick.
Still, the practical takeaway is clear. If your product depends on LLM-generated narratives, you should treat national-origin representation as a first-class safety concern. The paper shows that bias can be structured, persistent, and amplified by prompt context, even when the model is not being explicitly asked to be biased.
For developers, that means fairness work cannot stop at “don’t generate toxic content.” It has to include who gets portrayed as fully human, who gets sidelined, and which identities the model treats as default. This paper adds a concrete example of why that broader lens is necessary.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10