Why small language models should replace LLM-first enterprise AI
Enterprise AI should default to small language models, not giant LLMs, because they are cheaper, faster, and safer for most workflows.
Enterprise AI should default to small language models, not giant LLMs.
Enterprise AI architecture should stop treating large language models as the default and start with small, task-specific models for most workflows. The evidence is already visible in the economics: Info-Tech says high-volume, repetitive work does not justify trillion-parameter systems, and Gartner expects enterprise use of small, task-specific models to be three times higher than LLM use by 2027. That is not a niche trend. It is a correction to a bad design habit that wastes money, increases latency, and pushes sensitive data into places it does not need to go.
First argument: most enterprise work does not need a giant model
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most business tasks are narrow, repetitive, and predictable, which is exactly where small language models win. A help desk that classifies tickets into 200-plus categories, a legal team that identifies contract clauses, or a finance team that scans logs for fraud does not need broad internet-scale reasoning. It needs a model that can do one thing consistently, quickly, and at low cost.
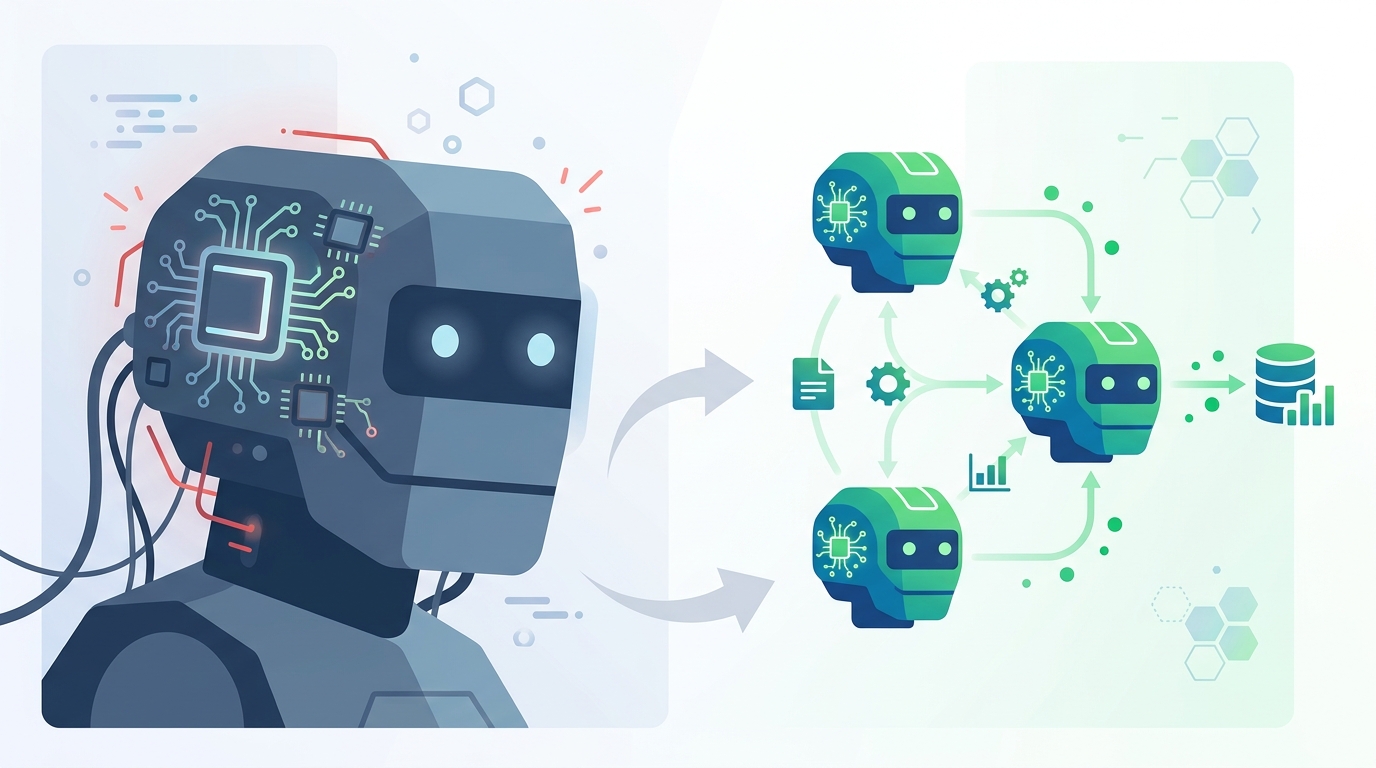
The architecture matters because routing the wrong task to a giant model is waste, not sophistication. Info-Tech’s Thomas Randall describes the better pattern as division of labor: a router sends simple queries to a specialized small model and reserves the large model for complex reasoning. That is the right enterprise stance because it turns AI from a monolith into a system. The result is lower cloud spend, faster response times, and fewer unnecessary calls to the most expensive component in the stack.
Second argument: privacy and deployment constraints favor SLMs
Enterprise AI is not only a cost problem. It is also a control problem. Small language models can run on-device, on-premises, or at the edge, which means sensitive telemetry, customer data, and regulated records do not need to leave the environment. For industries like healthcare, finance, and legal services, that is a decisive advantage, not a nice-to-have.
There is also a practical deployment benefit that the LLM-first crowd keeps ignoring: latency. Small models can deliver near-instant responses because they require far less compute. In real systems, that means better user experience for chatbots, faster triage for support teams, and offline capability for field devices. A model that responds in milliseconds and stays local is more useful than a larger model that is smarter in theory but slower, costlier, and harder to govern in production.
The counter-argument
The strongest case for LLMs is breadth. Large models handle open-ended reasoning, unfamiliar domains, and messy edge cases far better than small ones. They are also easier to adopt as a single platform because teams can point many use cases at one model instead of building a routing layer, data pipeline, and governance process for multiple models. For organizations that lack AI maturity, a general-purpose LLM looks simpler and faster to ship.
That argument is real, and it should be accepted in one respect: some workflows do need the broad reasoning and context handling only a large model can provide. But that does not justify making LLMs the default architecture. The better answer is orchestration. Use the large model where novelty, ambiguity, or long-context reasoning is unavoidable, and use SLMs everywhere else. Gartner’s own guidance points in that direction with composite approaches and better data preparation. In other words, the complexity belongs in the system design, not in every inference call.
What to do with this
If you are an engineer, build a routing layer that sends low-risk, high-volume, well-defined tasks to small models first, and escalate only when confidence drops or the task requires broader reasoning. If you are a PM, define success by latency, cost per task, and accuracy on the narrow workflow, not by model size. If you are a founder, stop selling “one model for everything” and design for a model portfolio instead. The winning enterprise AI stack is not bigger by default. It is smaller where it should be, larger where it must be, and disciplined everywhere else.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production