Why Observability Is Critical for Cloud-Native Systems
Observability is the operating requirement for cloud-native systems, not a nice-to-have.

Observability is the operating requirement for cloud-native systems, not a nice-to-have.
Observability is not a support function for cloud-native systems; it is the control plane that keeps them usable, secure, and economically sane.
In a world of containers that appear and disappear in seconds, services that fan out across clusters, and workloads that autoscale with demand, static dashboards cannot explain what is happening. Traditional monitoring can tell you that a metric crossed a threshold. It cannot tell you why a checkout failed after a service mesh rerouted traffic, or why latency rose only for users on one region and one browser version. That gap is exactly where observability belongs.
Cloud-native complexity has outgrown monitoring
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The first reason observability matters is simple: cloud-native systems are too dynamic for fixed assumptions. Monitoring was built for a predictable environment where you knew the important failure modes in advance. Modern platforms are the opposite. They are made of microservices, ephemeral infrastructure, and dependencies that shift every time a deployment lands. The article is right to call this the era of the “unknown unknowns.”

Distributed tracing shows why this matters in practice. A single user request can cross an API gateway, authentication service, cache, database, and front-end script before it fails. If you only watch one layer, you will guess. If you instrument the full path, you can identify whether the issue is a slow query, a bad release, a network hop, or a client-side regression. That is not an incremental improvement over monitoring. It is a different operating model.
Observability is the only way to control cost and response time
The second reason is economic. Cloud-native observability creates a huge telemetry burden, and that burden is now part of the infrastructure bill. Gartner has warned that the cost of cloud-native applications is rising with telemetry volume, and that warning should be taken literally. More data does not automatically mean more insight. Without sampling, filtering, and retention rules, observability becomes a firehose that stores noise at premium prices.
This is why the article’s emphasis on telemetry pipelines is important. A mature observability program does not collect everything forever. It decides what deserves high-fidelity storage, what can be sampled, and what can be discarded after it serves its immediate diagnostic purpose. That discipline directly reduces mean time to detect and mean time to resolve, because teams spend less time hunting and more time fixing. In cloud-native systems, faster diagnosis is not just an engineering win; it protects revenue when a degraded checkout, login, or API path would otherwise linger for hours.
AI makes observability more valuable, not less
Observability becomes even more important when AI enters operations. The article is correct to frame observability as the foundation of AIOps, because AI cannot invent signal that was never captured. Machine learning can correlate logs, metrics, traces, and topology at a scale humans cannot manage, but only if the system is instrumented well enough to feed it useful data. AI is not a replacement for observability. It is a force multiplier for it.
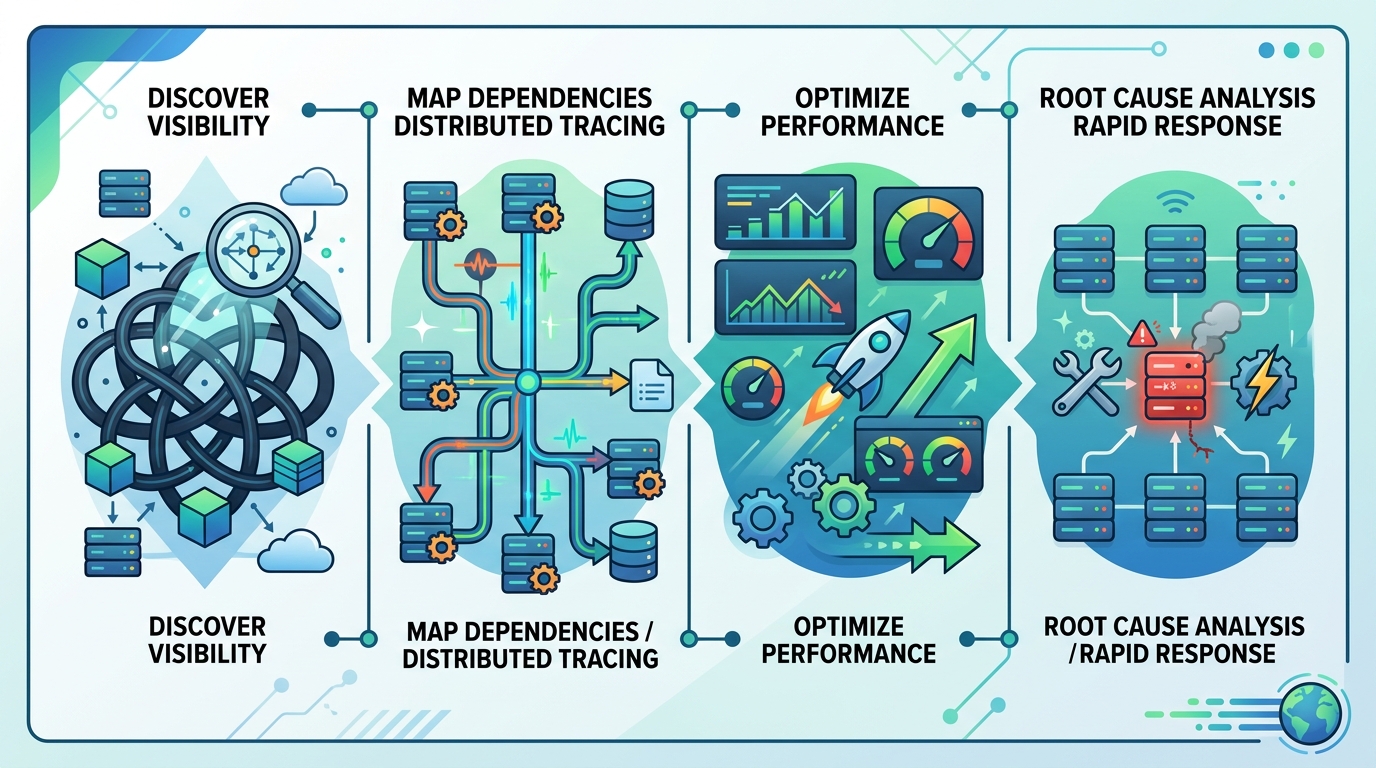
The practical payoff is predictive operations. If telemetry shows a memory leak pattern, a saturation trend, or a repeated error signature, AI can surface the issue before it becomes an outage. That is the real promise of modern observability: not just faster firefighting, but fewer fires. The CNCF’s focus on AI and predictive analytics points in the right direction because cloud-native reliability now depends on automation that sees patterns early enough to act.
The counter-argument
The strongest objection is that observability can become expensive, noisy, and organizationally bloated. That criticism is valid. Many teams buy multiple tools, ingest every log line, and create dashboards no one trusts. In that version of the story, observability becomes another layer of complexity added to an already complex stack. Skeptics are right to resist a vague “collect more data” strategy.
But that is not an argument against observability. It is an argument against undisciplined observability. The answer is not to retreat to basic monitoring; it is to standardize on OpenTelemetry, centralize strategy, and enforce smart sampling and retention. Those are not optional best practices. They are the difference between an observability program that creates clarity and one that creates budget waste. The limit is real: if an organization refuses governance, observability will fail. The conclusion is also real: the failure is operational, not conceptual.
What to do with this
If you are an engineer, instrument services for questions you do not know how to ask yet, not just for the dashboards you already have. If you are a PM, treat observability as product infrastructure because it protects customer experience and release confidence. If you are a founder, fund the platform work that reduces MTTR, standardizes telemetry, and prevents tool sprawl. Cloud-native systems reward teams that can see across layers, correlate quickly, and act before small faults become business incidents.
Observability is the right foundation for cloud-native operations because it turns system complexity into actionable knowledge.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production