Selective LLM Regularization for Recommenders
A paper on using selective LLM-guided regularization to improve recommendation models without overhauling the recommender stack.
Selective LLM-guided regularization aims to improve recommendation models.
This paper, Selective LLM-Guided Regularization for Enhancing Recommendation Models, looks at a practical question for recommender systems: how do you bring large language models into the loop without turning the whole pipeline into an expensive rewrite? The core idea is to use an LLM as a source of guidance for regularization, then apply that guidance selectively rather than everywhere.
That matters because recommendation stacks are often already tuned, brittle, and tightly coupled to production constraints. If a new technique can improve model behavior while staying selective, it has a better shot at fitting into real systems than a heavyweight redesign would.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The source material does not provide a full abstract or benchmark table, so the paper’s exact experimental setup and results are not visible here. What is clear from the title is the target: recommendation models that could benefit from extra signal, but only in a controlled way.
In practice, recommenders face a familiar tradeoff. Add more modeling power, and you may get better ranking or personalization, but you also add complexity, latency, and maintenance burden. LLMs can help because they can encode broad semantic knowledge, but naively plugging them into a recommender can be too costly or too noisy. A selective regularization approach is trying to get the upside while limiting the blast radius.
For engineers, that framing is useful. It suggests the paper is not about replacing the recommender with an LLM. It is about using the LLM as a teacher, constraint source, or auxiliary signal that nudges the existing model in better directions.
How the method works in plain English
The title points to two important ideas: “LLM-guided” and “selective regularization.” Regularization usually means adding a training-time penalty or constraint so a model learns more stable, more generalizable behavior. If the guidance comes from an LLM, then the LLM is likely providing some kind of semantic or preference-aware signal that shapes how the recommender learns.
The “selective” part is the practical twist. Instead of regularizing every example, every layer, or every prediction equally, the method appears to apply LLM guidance only where it is most useful. That could mean focusing on certain samples, certain user-item pairs, or certain parts of the training process. The source does not spell out which one, so we should not guess. But the general engineering idea is familiar: spend the expensive signal where it has the highest value.
That kind of design usually aims to reduce two common failure modes. First, over-regularization, where the model becomes too constrained and loses fit. Second, wasted compute, where expensive guidance is applied broadly even when only a subset of cases needs help. Selectivity is the mechanism that tries to balance both.
What the paper actually shows
The raw source provided here does not include benchmark numbers, dataset names, or concrete evaluation metrics. So there are no reported lifts, no comparison tables, and no claim we can responsibly summarize as a measured improvement.
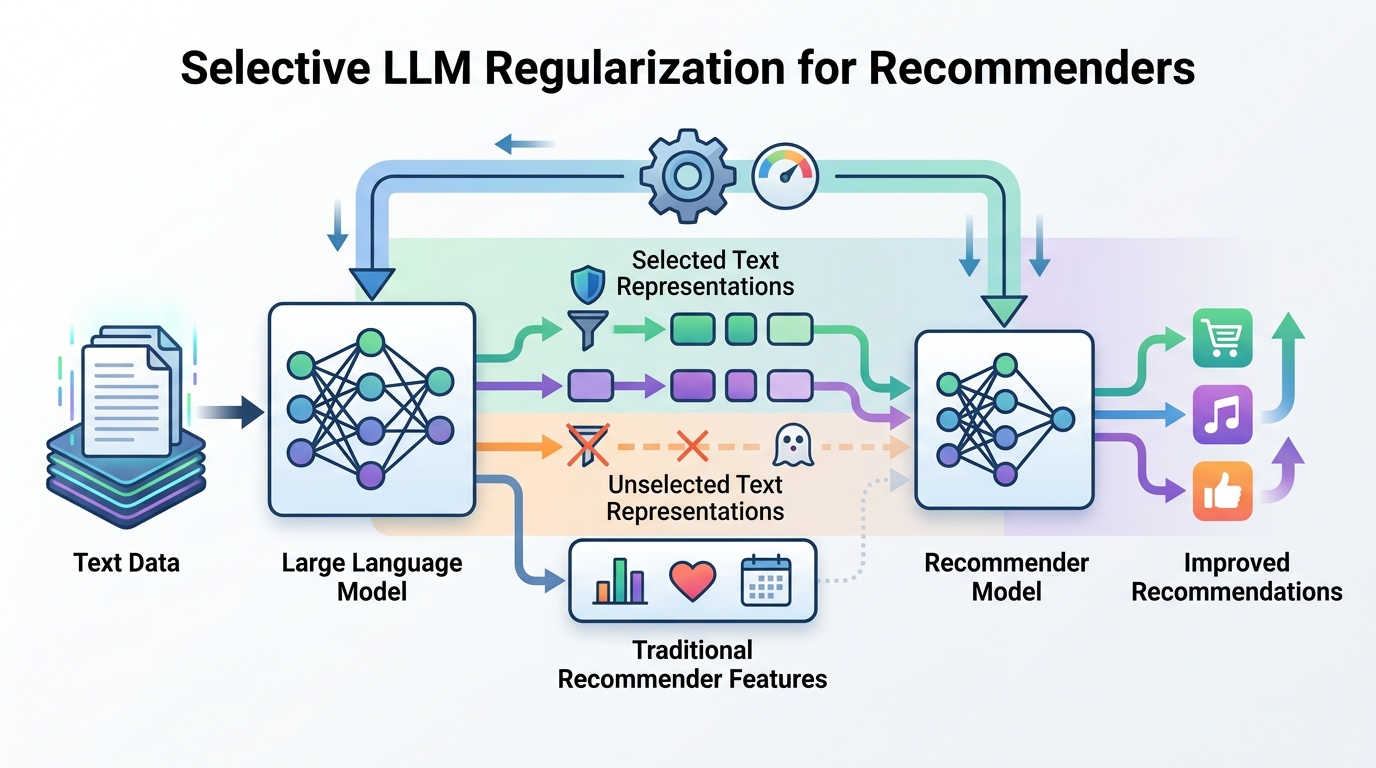
That does not mean the work is unimportant. It means the only safe conclusion from the material available is about the paper’s direction, not its quantified performance. If you are reading this as an engineer, the key question to ask next is whether the paper demonstrates gains in ranking quality, calibration, diversity, robustness, or some other recommender metric, and under what compute cost.
Without those details, the best honest read is that the paper proposes a method class rather than a fully characterized production recipe. The value here is the formulation: LLMs are not being used as a replacement engine, but as a selective source of regularization for an existing recommendation model.
- We can confirm the paper is about recommendation models.
- We can confirm it uses LLM-guided regularization.
- We can confirm the guidance is selective, not blanket.
- We cannot confirm benchmarks or metrics from the provided source.
Why developers should care
Recommendation systems are one of those areas where incremental improvements matter, but so does operational realism. A technique that depends on a large model at inference time may be hard to deploy. A technique that only influences training can be much easier to absorb into an existing stack.
That is why the phrase “LLM-guided regularization” should catch a practitioner’s eye. It suggests a way to use LLM knowledge without paying the full runtime cost of an LLM-powered recommender. If the method works as intended, the LLM becomes a training-time assistant rather than a production dependency.
Selective application also hints at a systems-friendly design. In real pipelines, you often want to reserve expensive or high-variance signals for hard cases, tail items, sparse interactions, or ambiguous examples. A selective regularizer fits that mindset better than a blanket transformation of the model.
Limitations and open questions
The biggest limitation here is the source material itself: it does not expose the abstract, methodology details, or results section. That leaves several open questions unanswered.
For example, we do not know what “LLM-guided” means operationally. Is the LLM generating textual rationales, preference constraints, item similarities, or sample-level weights? We also do not know how the selective mechanism chooses where to apply the regularization, or how expensive that selection is.
There is also an important deployment question. If the method requires repeated LLM calls during training, the cost profile may still be significant. If it relies on cached LLM outputs, then freshness and domain drift become concerns. And if the LLM guidance is noisy, selective use may help, but it may also make the behavior harder to interpret.
So the practical takeaway is cautious but useful: this paper appears to explore a way to inject LLM knowledge into recommenders without fully restructuring the system. That is exactly the kind of direction many teams would want to test, but the missing benchmark details mean you should treat it as a research lead, not a proven drop-in upgrade.
If you are building recommendation infrastructure, the next step would be to read the full paper and look for the exact regularization target, the selection rule, the training overhead, and the reported gains relative to a standard recommender baseline. Those are the details that determine whether this is a clever idea or a deployable one.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10