MoRight tackles motion control and causality
MoRight separates camera and object motion, and models active vs. passive actions so video generation can react more plausibly to user input.

Motion-controlled video generation sounds simple until you try to make it work: the user wants to move an object, change the camera, and still get a scene that behaves like the world has rules. MoRight: Motion Control Done Right argues that most current methods fail because they mix camera and object motion together and treat motion as pure displacement instead of a chain of causes and effects.
The practical goal here is straightforward. If you are building generative video tools, robotics simulators, interactive scene editors, or any system where user actions should trigger believable reactions, you need motion control that is both editable and coherent. MoRight is aimed at exactly that gap.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper focuses on motion-controlled videos: videos where a user specifies actions and the model generates physically plausible scene dynamics from a chosen viewpoint. The authors say this requires two things at once. First, the system needs disentangled motion control, so camera changes do not get tangled up with object motion. Second, it needs motion causality, so one object’s action can trigger a sensible response from other objects instead of just shifting pixels around.

According to the abstract, existing methods fall short on both fronts. They tend to collapse camera motion and object motion into one tracking signal. That makes editing awkward because changing the viewpoint can interfere with the motion you wanted to control. They also treat motion as kinematic displacement, which means they can move things around but do not explicitly model how one action causes another event in the scene.
For engineers, this is the difference between a video generator that can “follow instructions” and one that can actually support interactive scene behavior. If the model cannot separate viewpoint from action, control becomes brittle. If it cannot model interaction, the output may look animated but not causally grounded.
How MoRight works in plain English
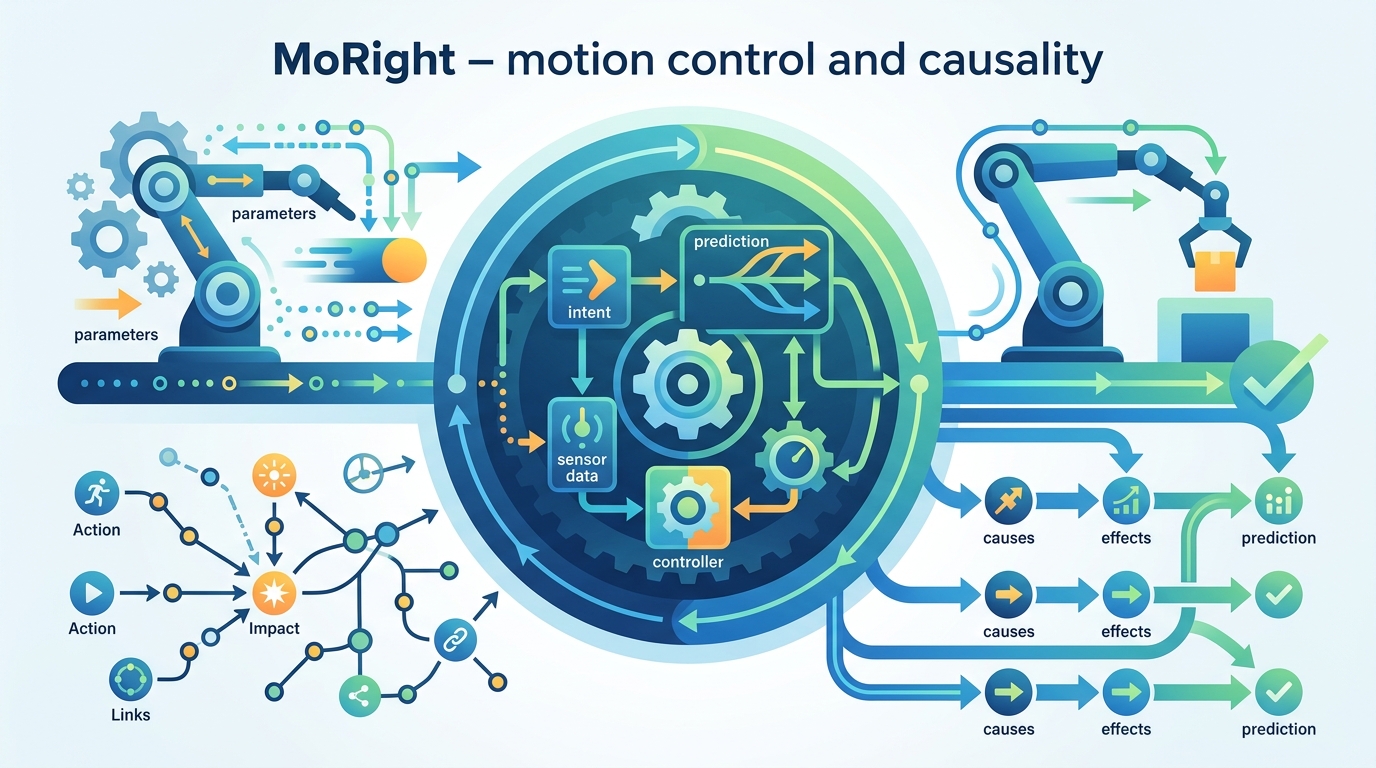
MoRight is described as a unified framework that addresses both limitations through disentangled motion modeling. The key idea is to represent object motion in a canonical static view first, then transfer that motion to whatever camera viewpoint the user chooses. The transfer happens through temporal cross-view attention, which the abstract says enables separate control over camera and object motion.
That design matters because it avoids forcing the model to infer motion and viewpoint as a single entangled signal. In practical terms, the user can define what moves, and independently decide how the scene is viewed. The model then maps the motion into the target view rather than baking the camera into the motion itself.
The second piece is causality. MoRight decomposes motion into active and passive components. Active motion is the user-driven action. Passive motion is the consequence that follows from it. The model is trained to learn motion causality from data, so it can represent not just that something moved, but that something moved because something else happened first.
At inference time, the paper says MoRight supports two modes. In forward reasoning, the user provides active motion and the model predicts the consequences. In inverse reasoning, the user specifies the desired passive outcome and the model recovers plausible driving actions. In both cases, the camera viewpoint can still be adjusted freely.
That combination is what makes the paper interesting from a systems perspective. The model is not just generating frames; it is trying to preserve a structured relationship between user intent, scene dynamics, and viewpoint control.
What the paper actually shows
The abstract says the authors evaluated MoRight on three benchmarks. They report state-of-the-art performance in generation quality, motion controllability, and interaction awareness. However, the abstract does not include the benchmark names, metric values, or any numerical improvements, so those details are not available from the source text provided here.
Even without numbers, the result claim is still meaningful because it spans three different axes that often trade off against each other. Generation quality asks whether the output looks good. Motion controllability asks whether the model follows the requested action. Interaction awareness asks whether the model understands that scene elements should respond to each other in a coherent way.
The fact that the paper claims gains across all three suggests MoRight is trying to avoid the usual compromise where a model looks decent but ignores control, or obeys control but breaks realism. The abstract does not tell us how large the gains are, how much compute the method needs, or how stable it is across different scene types.
That missing detail matters. Without the full paper, we do not know whether the approach generalizes broadly or whether the improvements depend on a narrow benchmark setup. We also do not know how sensitive it is to annotation quality, training data composition, or the complexity of the interactions being modeled.
- Evaluated on three benchmarks
- Claims state-of-the-art results
- Reported strengths: generation quality, motion controllability, interaction awareness
- No benchmark names or metric numbers are included in the abstract
Why developers should care
If you are building tools where users direct motion, the two design choices in MoRight are the useful part. Separating camera control from object motion makes editing more intuitive. Modeling active versus passive motion makes the output more useful for interactive scenarios, because the system can respond to actions rather than just replay movement.
This is especially relevant for applications where scene behavior matters more than isolated frame quality. Think of content creation tools, simulation-like interfaces, or any workflow where a user wants to ask “what happens if I do this?” rather than just “animate this object.” A model that can reason forward from an action or backward from a desired outcome gives you more control surface to expose in a product.
There are also clear limitations in what the abstract gives us. We do not know how MoRight handles long-range dependencies, crowded scenes, or rare interactions. We do not know whether the canonical static-view representation introduces its own failure modes. And because the abstract does not provide benchmark numbers, we cannot judge the size of the improvement from the summary alone.
Still, the conceptual move is strong: stop mixing viewpoint and motion, and stop pretending motion is only a displacement problem. For developers working on controllable generation, that is a useful framing even before you get to the implementation details.
Bottom line
MoRight is a motion-control paper that treats video generation as both a viewpoint problem and a causality problem. It tries to let users steer motion and camera independently while also making scene reactions more believable.
The abstract does not give us the full experimental picture, but it does make the direction clear. If your system needs controllable, interaction-aware motion rather than just animated pixels, this is the kind of architecture worth watching.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10