Multi-fidelity models for composite mechanics
A review of co-kriging, deep Gaussian processes, and neural nets for cheaper composite-mechanics prediction.
This review explains how multi-fidelity surrogates cut the cost of composite-mechanics prediction.
Composite materials are hard to model because their behavior is hierarchical, anisotropic, and shaped by multiple coupled mechanisms across constituents, plies, laminates, structures, and manufacturing history. In practice, that means accurate prediction often requires repeated experiments or expensive high-fidelity simulations, which quickly becomes a bottleneck when engineers need to search a large design space.
This paper, Multi-fidelity surrogates for mechanics of composites: from co-kriging to multi-fidelity neural networks, is a review of the main surrogate modeling approaches used to reduce that cost. The core idea is simple: mix abundant low-cost data with limited high-accuracy data so you can still recover useful high-fidelity predictions without paying the full price everywhere.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper is aimed at a familiar engineering problem: the system you want to understand is too expensive to sample densely. For composites, that expense comes from the need to capture not just geometry, but also manufacturing history, nonlinear damage, and multiscale interactions that affect performance in different regimes.
That creates a practical gap. Low-fidelity data may be plentiful, but it is not always aligned with the real system. High-fidelity data is more trustworthy, but it is limited. Multi-fidelity surrogate modeling tries to bridge that gap by learning how the cheaper data relates to the expensive data, then using that relationship to make better predictions than either source could provide alone.
The review is especially relevant for engineers working on design exploration, inverse problems, or simulation workflows where you cannot afford to run the most accurate model for every candidate. It frames multi-fidelity methods as a way to spend high-fidelity budget more strategically.
How the method works in plain English
The paper organizes the field around several model families. On the Gaussian-process side, it covers Kriging-based methods, including co-Kriging, coregionalization models, autoregressive formulations, nonlinear autoregressive Gaussian processes, and multi-fidelity deep Gaussian processes. It also covers multi-fidelity neural networks.
Although these methods differ in implementation, they all try to learn a relationship between fidelity levels. Some focus on cross-fidelity correlation, where the model directly captures how one data source tracks another. Others emphasize discrepancy representation, meaning they model the gap between low- and high-fidelity outputs instead of assuming the two are identical.
Uncertainty quantification is another major theme. In engineering, a surrogate is only useful if it can say how confident it is, especially when it is being used to guide design decisions. The review treats this as one of the key distinctions between model classes, along with scalability, since some approaches are better suited to larger datasets or more complex architectures than others.
In plain terms, the workflow looks like this:
- collect lots of cheap, approximate data;
- collect a smaller amount of expensive, accurate data;
- learn how the two fidelities are related;
- use that relationship to predict high-fidelity behavior in new cases.
The paper does not present a single new algorithm. Instead, it maps out the design space so readers can understand which family of methods fits which kind of composite-mechanics problem.
What the paper actually shows
This is a review paper, so it is not trying to report one benchmark or one winner-takes-all result. The abstract does not provide benchmark numbers, so there are no quoted accuracy gains, speedups, or dataset sizes to report here.
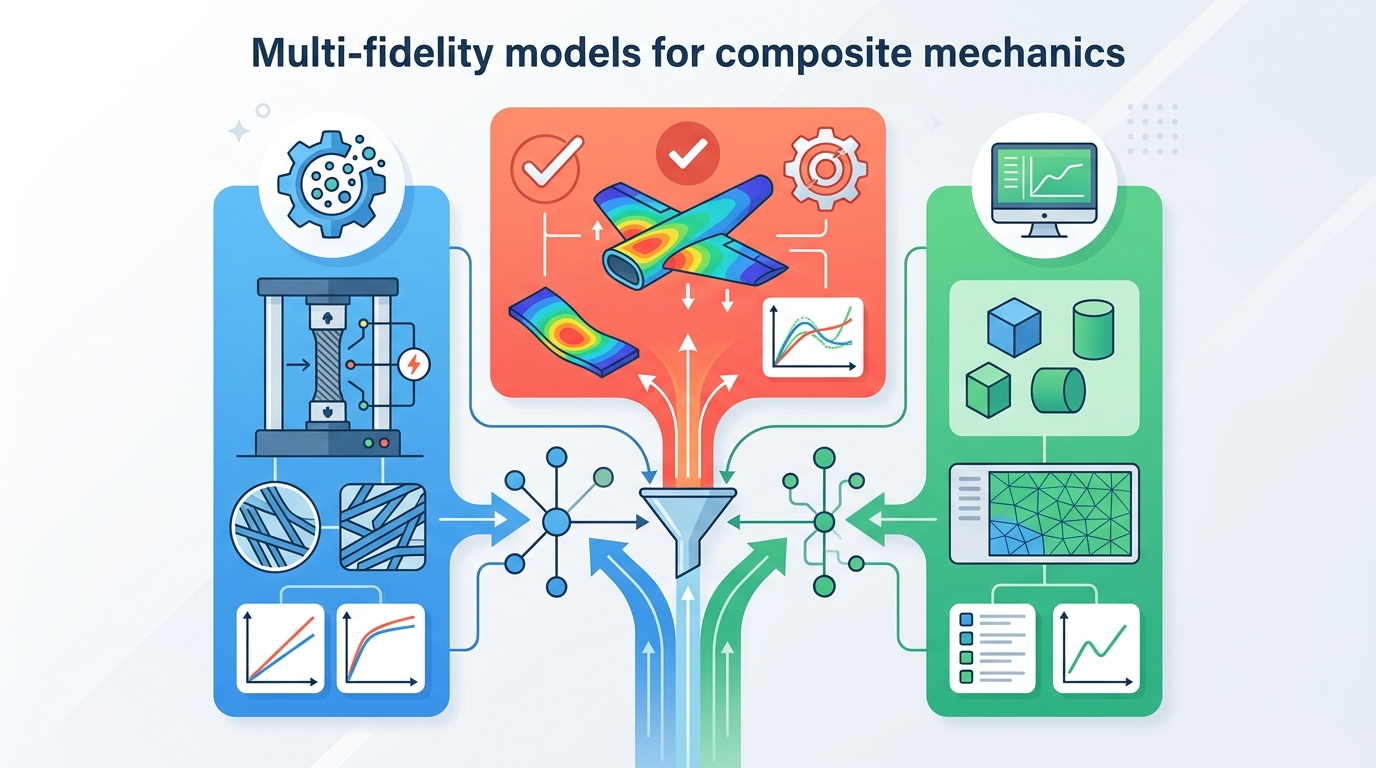
What the paper does provide is a structured comparison of the main method families and how they differ in practice. It examines them in terms of cross-fidelity correlation, discrepancy modeling, uncertainty handling, and scalability. That is useful because the right choice is not just about predictive accuracy; it is also about whether the model can handle the data regime and workflow constraints you actually have.
The review also groups applications by role. Multi-fidelity surrogates are presented as tools for forward prediction, inverse optimization, and workflow integration. In forward prediction, they help with rapid exploration of material design spaces. In inverse optimization, they support parameter identification and design search when access to high-fidelity data is limited. In workflow integration, they help combine heterogeneous data sources while respecting constraints and validation requirements.
That application framing matters because it shows where these models fit into engineering practice. A surrogate that is fine for screening candidate designs may not be appropriate for closed-loop optimization or for integrating simulation and experimental pipelines. The paper’s structure makes those tradeoffs explicit.
Why developers and engineers should care
If you build tools for simulation, optimization, or materials design, the main takeaway is that multi-fidelity modeling is less about replacing physics and more about spending simulation budget intelligently. The review suggests that the best surrogate is the one that matches your data availability, your fidelity gap, and your need for uncertainty estimates.
That is especially important in composite mechanics, where fidelity gaps can be regime-dependent. The paper calls out nonlinear damage and manufacturing history as recurring sources of trouble. In other words, a model that works in one regime may not transfer cleanly to another, even if both are technically “the same material.”
For practitioners, that means you should treat fidelity alignment as a modeling problem in its own right. If your low-fidelity simulation systematically misses a manufacturing effect, the surrogate has to learn that mismatch rather than smooth it away. If experiments and simulations disagree, the model must account for that mismatch instead of assuming one source is simply noisier than the other.
The review also highlights uncertainty propagation across multi-fidelity models as an open issue. That matters for deployment because engineering decisions often depend on downstream risk, not just point predictions. A surrogate that cannot carry uncertainty through the pipeline may be hard to trust in optimization or validation workflows.
Open questions and limitations
The paper is honest about the fact that composite mechanics introduces problems that are still not fully solved by current multi-fidelity methods. One challenge is regime-dependent fidelity gaps, especially when nonlinear damage or manufacturing history changes the relationship between low- and high-fidelity data.
Another issue is mismatch between simulations and experiments. The review flags this explicitly, which is important because many surrogate methods assume the fidelities are aligned versions of the same underlying process. In composites, that assumption can break down.
Scalability is also a concern. Some methods may handle uncertainty well but become harder to scale, while others may scale better but offer a weaker treatment of discrepancy or uncertainty. The review does not claim that any one family solves all of these tradeoffs.
So the practical message is not “use multi-fidelity and everything gets easier.” It is more specific than that: if you have mixed-quality data and limited access to expensive evaluations, multi-fidelity surrogates give you a principled way to combine them, but you still need to think carefully about fidelity gaps, validation, and the engineering regime you care about.
For developers building research software or design automation pipelines, this paper is a useful map of the field rather than a drop-in implementation guide. It tells you what kinds of models exist, what they are good at, and where the open problems still are.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10