複材力學的多保真模型怎麼省算力
這篇綜述整理 co-kriging、深度高斯過程與多保真神經網路,說明如何用低成本資料搭配少量高精度資料,降低複合材料力學預測的計算與實驗成本。
這篇綜述在講,怎麼用多保真模型把複合材料力學預測做得更省成本。
複合材料不好算,原因不是只有材料本身複雜,而是它的行為是分層的、各向異性的,還會被多種耦合機制一起影響。從 constituent、ply、laminate 到結構層級,再加上製程歷史,任何一層沒抓好,預測就可能偏掉。
對工程團隊來說,這代表一件很現實的事:如果你想把設計空間掃得夠廣,就得做很多實驗,或跑很多高精度模擬。但這兩件事都貴。當你還在找材料組合、參數範圍,或是在做反向設計時,這個成本很快就會變成瓶頸。
這篇論文是 Multi-fidelity surrogates for mechanics of composites: from co-kriging to multi-fidelity neural networks。它不是提出一個全新的單一模型,而是回顧這個領域怎麼演進,重點放在 co-kriging、各種 Gaussian process 延伸、以及多保真神經網路,看看它們各自怎麼把便宜資料和昂貴資料接起來。
這篇想解的痛點是什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
核心痛點很直接:你想知道系統行為,但每次取樣都太貴。對複材力學來說,昂貴不只來自幾何或材料參數多,而是你還得處理非線性損傷、跨尺度互動,以及製程留下的歷史效應。這些因素會一起改變材料表現,而且常常不是線性關係。
在這種情況下,低保真資料通常比較多,但它不一定真的貼近真實系統。高保真資料比較可信,但數量有限。多保真 surrogate 的目的,就是學會「低保真和高保真之間到底差在哪」,再把這個關係用在新樣本上,讓你不用每次都付最高成本。
這種方法特別適合幾種工作流。像是設計探索、反問題、參數辨識,或是要把模擬和實驗資料一起放進同一個流程時,都很需要這種「用少量高精度資料撐住整體預測」的能力。這篇綜述就是在幫讀者把這個工具箱整理清楚。
方法到底怎麼運作
這篇文獻把多保真方法分成幾個家族。高斯過程這一側,包含 Kriging、co-Kriging、coregionalization models、autoregressive formulations、nonlinear autoregressive Gaussian processes,以及 multi-fidelity deep Gaussian processes。另一側則是 multi-fidelity neural networks。
雖然名字很多,但它們的共同點很一致:都在學不同 fidelity 之間的關係。有些方法重點是 cross-fidelity correlation,也就是直接捕捉不同資料來源之間怎麼一起變化。有些方法則偏向 discrepancy modeling,重點不是把兩個資料源當成一樣,而是把低保真和高保真之間的落差學出來。
這個差別很重要。因為在工程問題裡,低保真模型不一定只是「比較吵」,它可能是系統性偏差。比如製程效應沒建進去,或某個損傷機制被簡化掉。這時候,模型要做的不是把誤差抹平,而是把差異明確學出來。
另一個反覆被提到的主題是 uncertainty quantification。工程上,surrogate 不只是要給答案,還要知道自己有多不確定。尤其當模型要拿去做設計決策、篩選候選方案,或是接到後續最佳化流程時,不確定度就不是附加功能,而是核心需求。
如果把整個流程拆開看,大概就是這樣:
- 先蒐集大量便宜、近似的低保真資料;
- 再蒐集少量昂貴、準確的高保真資料;
- 學習兩種 fidelity 的對應關係;
- 用這個關係去推估新的高保真行為。
這篇綜述的重點不是告訴你某個演算法怎麼寫,而是幫你看懂不同模型家族的設計邏輯。換句話說,它在畫地圖,不是在交付單一套件。
論文實際證明了什麼
先講清楚:這是一篇 review,不是單一實驗論文。摘要裡也沒有公開完整 benchmark 細節,所以沒有可直接引用的數字結果,例如準確率提升、速度加成或資料集規模。
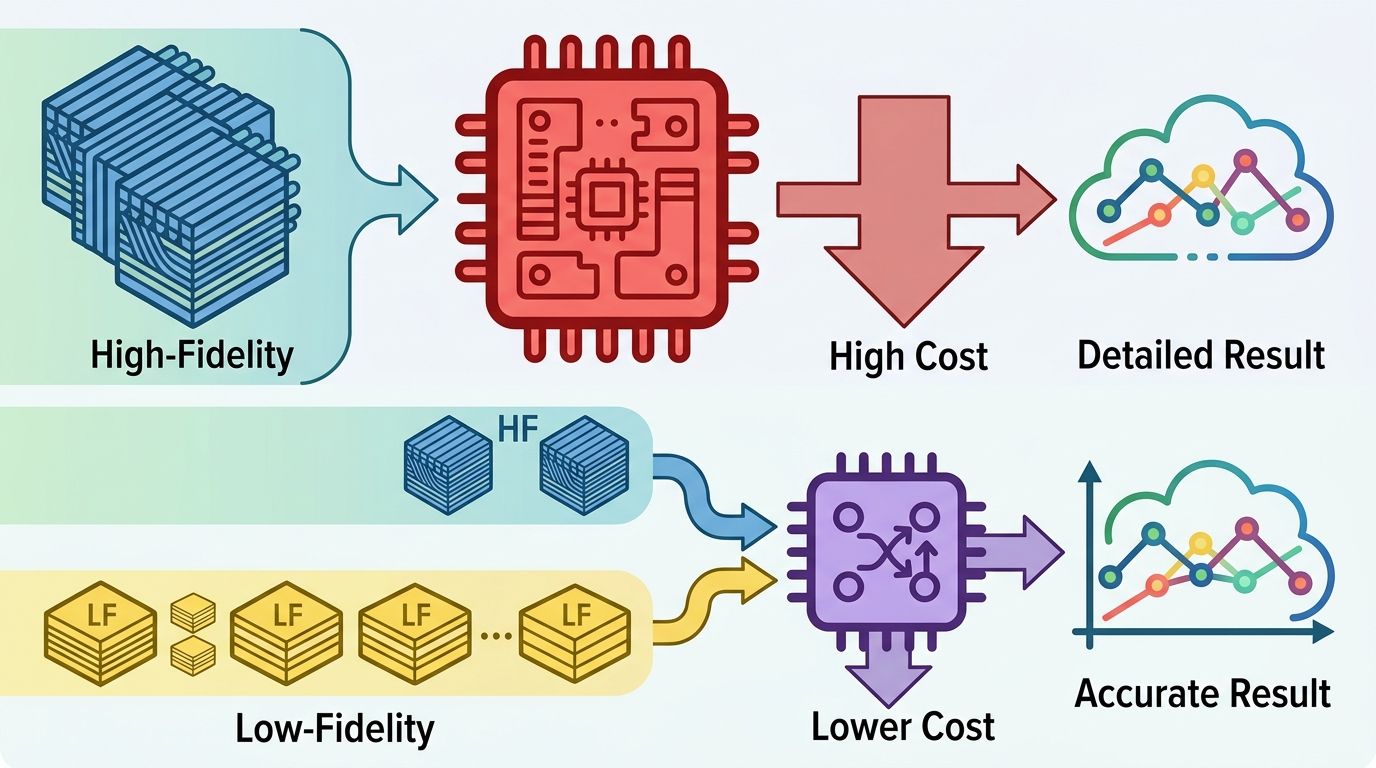
但這不代表它沒有產出有用結論。它真正做的事,是把主要方法家族放在同一個框架下比較,並且從幾個維度去看它們的差異:cross-fidelity correlation、discrepancy representation、uncertainty handling,以及 scalability。這些面向在實務上往往比單次 benchmark 更重要,因為你真正面對的是資料型態、算力預算和工作流限制,而不是單一分數。
綜述也把應用場景分得很清楚。multi-fidelity surrogate 可以拿來做 forward prediction,也可以用在 inverse optimization,還能放進 workflow integration。這三個角色的需求不一樣:前者重視快速掃描設計空間,後者重視在資料有限時做參數識別或設計搜尋,第三種則是在模擬與實驗資料混合時,維持流程一致性與驗證條件。
這種分類方式的價值在於,它提醒讀者不要把多保真模型想成單一萬用解法。能做 screening,不代表就適合閉迴路最佳化;能處理不確定度,也不代表就能輕鬆擴到更大資料量。這篇文章把這些 trade-off 擺在桌上。
對開發者和工程師有什麼影響
如果你在做模擬、最佳化,或材料設計工具,這篇綜述最實用的訊息是:多保真建模的重點不是取代物理,而是把昂貴的模擬預算用得更聰明。你不一定要在每個候選設計上都跑最精細的模型,但你需要知道哪些地方值得花高保真成本。
對複材力學來說,這件事尤其重要,因為 fidelity gap 常常是跟 regime 綁在一起的。摘要特別提到 nonlinear damage 和 manufacturing history 這兩個來源,意思是低保真和高保真之間的差距,可能會隨著工況改變。模型在一個區域表現好,不代表到了另一個區域還能沿用。
這也表示,fidelity alignment 本身就是一個建模問題。若低保真模擬系統性漏掉某個製程效應,surrogate 就要學會那個 mismatch,而不是假設它只是雜訊。若實驗和模擬不一致,模型也不能直接把兩者當成同一個真相的不同版本。
對做研究軟體或設計自動化流程的人來說,這篇文章的價值更像一份領域地圖。它沒有直接給你可複製的程式碼,但它把方法類型、適用情境和限制列得很清楚,能幫你先判斷該走 Gaussian process 路線,還是 neural network 路線,或是先處理不確定度與資料對齊問題。
限制、風險和還沒解完的題目
這篇綜述也很明白地點出,複合材料力學不是所有多保真方法都能輕鬆吃下來的場景。第一個難題就是 regime-dependent fidelity gaps。當非線性損傷、製程歷史或多尺度互動改變了資料關係,原本有效的低高保真對應可能就失效。
第二個問題是 simulation 和 experiment 的 mismatch。很多 surrogate 方法默認不同 fidelity 只是同一個底層過程的不同近似,但在複材領域,這個假設可能不成立。這也是為什麼這篇文章會把 discrepancy modeling 拉出來談,因為差異本身就是訊號,不是只該被消掉的誤差。
第三個問題是 scalability。某些方法在不確定度處理上很漂亮,但資料一大就不容易擴;另一些方法比較能擴展,但對 discrepancy 或 uncertainty 的表達可能沒那麼完整。這篇綜述沒有宣稱哪一類方法全面勝出,反而是在提醒讀者:你要先知道自己最在意的是哪個 trade-off。
所以,這篇論文的實際結論不是「用了多保真,一切就解決」。比較準確的說法是:如果你手上有混合品質資料,而且高成本評估次數有限,多保真 surrogate 提供了一個有原理的整合方式;但你還是得認真看 fidelity gap、驗證方式,以及你要處理的工程 regime。
對台灣開發者或研究團隊來說,這種方法特別適合會碰到模擬昂貴、資料稀缺、又需要保留不確定度資訊的場景。它不是一個現成產品方案,但它提供了一套很實際的思考框架:先分清楚資料品質,再決定怎麼把高保真預算花在最有價值的地方。
如果你只想抓一句話,這篇綜述的重點就是:複合材料力學很貴,多保真模型的價值在於把便宜資料和昂貴資料接起來,讓預測、最佳化和工作流整合都更可行,但前提是你得正視 fidelity gap、uncertainty 和 scalability 這三個現實問題。