AWS Bedrock Knowledge Bases 怎麼簡化 RAG
AWS Bedrock Knowledge Bases 把 RAG 的擷取、向量庫、重排序和引用整合成託管服務,適合要接企業內部資料的 AI 應用。
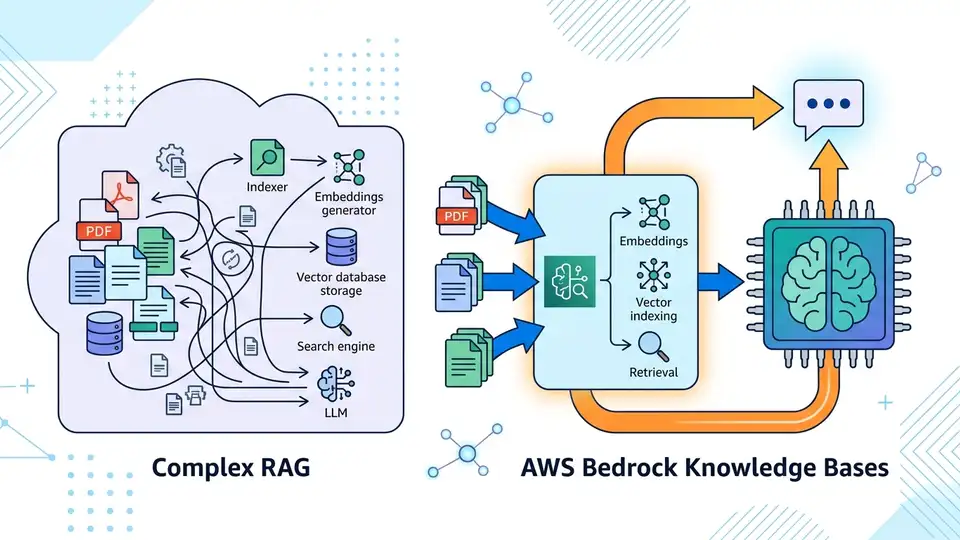
AWS Bedrock Knowledge Bases 把 RAG 的擷取、向量庫、重排序和引用整合成託管服務,讓團隊更快把企業內部資料接進 AI 應用。
說真的,這東西就是在救工程師的時間。AWS 把原本要自己串的流程,包成一個服務。你不用先搞 chunking、embeddings、向量資料庫、引用追蹤,再來才開始測答案品質。
這次 AWS 直接把 RAG 的麻煩事收進 Amazon Bedrock。它主打讓模型讀懂公司內部資料,還能附上來源。對台灣很多做企業軟體的人來說,這種設計很實際。
| 能力 | AWS 說法 | 意義 |
|---|---|---|
| 工作流程 | 端到端 RAG | 擷取、檢索、提示擴充集中在同一服務 |
| 資料來源 | S3、Confluence、Salesforce、SharePoint、Web Crawler 預覽 | 企業常見系統可直接接入 |
| 向量儲存 | Aurora、OpenSearch Serverless、Neptune Analytics、MongoDB、Pinecone、Redis Enterprise Cloud | 可沿用既有儲存選項 |
| 檢索 API | Retrieve 與 RetrieveAndGenerate | 可先看結果,再直接產生回答 |
| 來源標註 | 附 citations | 使用者知道答案從哪來 |
AWS 到底交付了什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Amazon Bedrock Knowledge Bases 是 Amazon Bedrock 裡的託管 RAG 功能。AWS 說,它可以接 Amazon S3、Confluence、Salesforce、SharePoint。另外,Web Crawler 還在預覽。
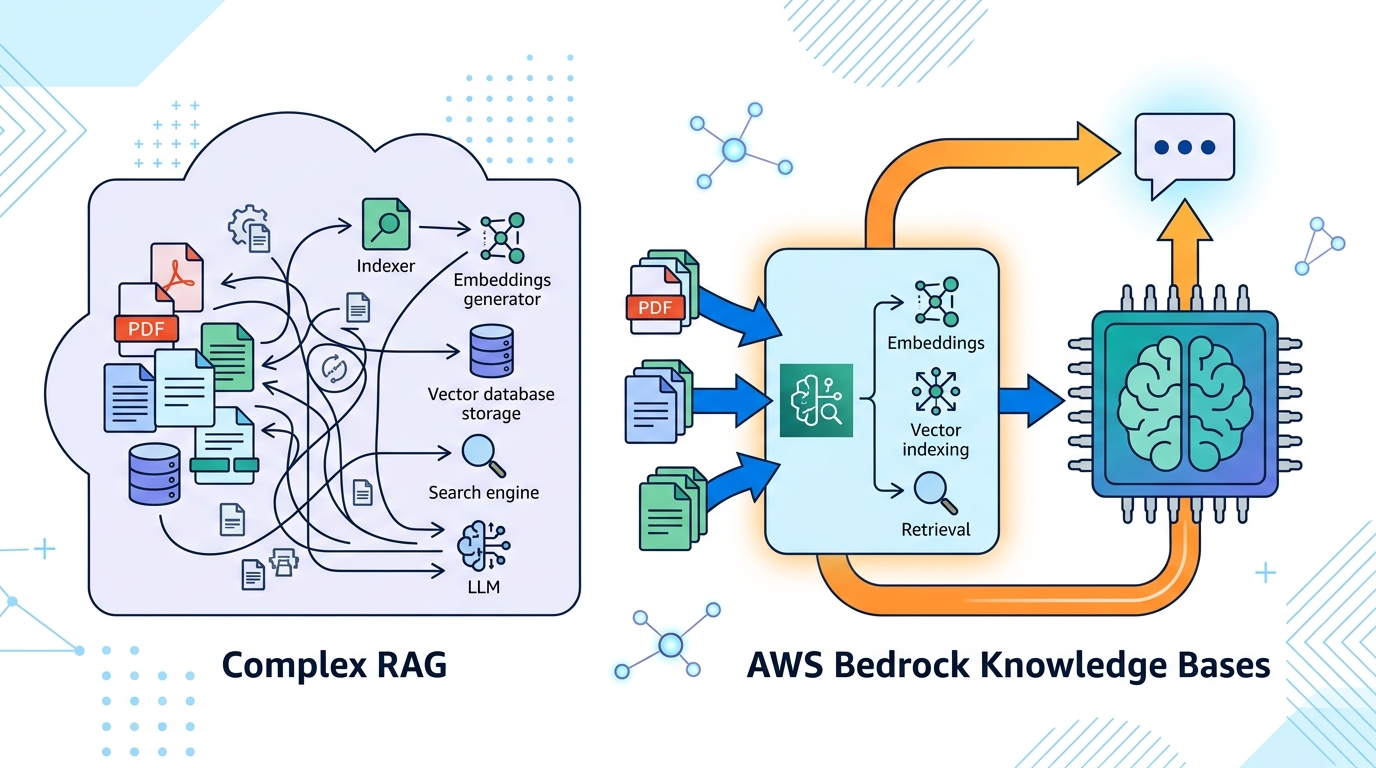
這很重要。很多團隊卡住,不是模型不行,是資料太亂。文件散在雲端硬碟、知識庫、CRM,還有一堆老舊系統。你要自己把這些東西接成一條資料管線,通常就先掉半條命。
Bedrock Knowledge Bases 也支援程式化匯入。這代表你不用只靠官方支援的來源。只要你的資料能進來,就能再做切塊、向量化、存進向量庫。對資料來源很雜的公司,這點很實用。
- 可接常見企業系統
- 可把內容轉成 embeddings
- 可用 Retrieve 或 RetrieveAndGenerate
- 回答會附來源引用
為什麼結構化資料這麼重要
我覺得最有料的部分,不是文件搜尋,而是結構化資料。AWS 說,它可以把自然語言轉成 SQL,直接去查資料表。這表示你不用先把資料庫內容複製到另一套系統。
講白了,很多企業問題根本不是「找文件」。而是「查訂單」、「看庫存」、「比月份營收」。這些問題都在表格裡,不在 PDF 裡。只靠向量索引,常常會答到一半就歪掉。
AWS 也說,某些情境甚至不用向量資料庫。你如果只是要問單一文件,或做小範圍問答,這樣就少掉一層架構。對早期驗證來說,這真的省事。
台灣很多軟體團隊會先做內部助理。像客服知識庫、法務文件、產品規格。這些場景常常先從單一資料源開始。等需求變大,再接資料庫和多來源檢索,會比較順。
- 可直接查結構化資料表
- 可降低資料複製成本
- 小型場景可不裝向量庫
- 適合先做內部問答
它怎麼處理亂七八糟的企業內容
AWS 這次也把多模態檢索放進來。它能解析文件裡的表格、圖表、圖像、音訊和影片。這不是裝飾。很多企業文件的重點,根本寫在圖上,不在段落裡。
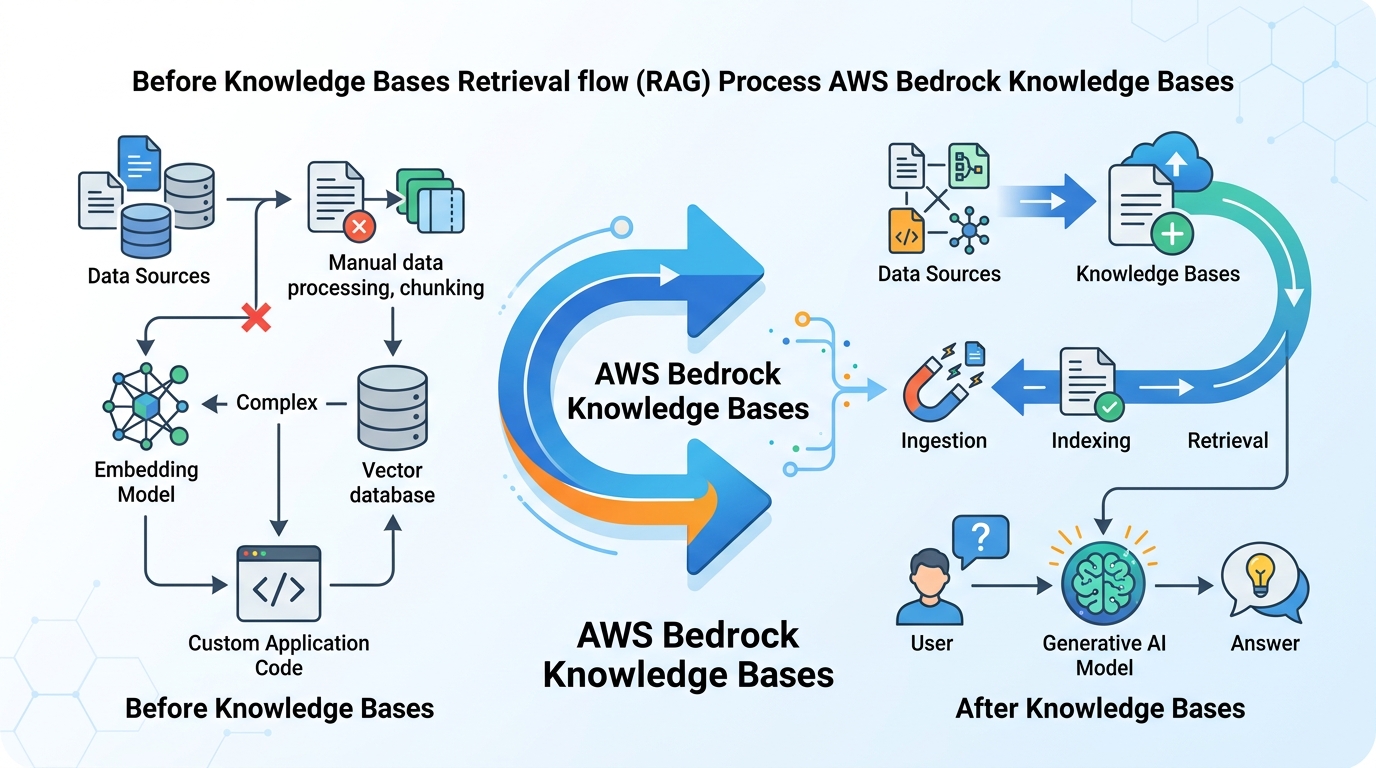
像合約、簡報、財報、技術手冊,都很吃版面。你如果只看純文字,很多資訊會消失。AWS 提到可以用 Bedrock Data Automation 或 foundation model 當 parser,這就是在處理這種情況。
chunking 方式也比一般做法多。AWS 列出 semantic chunking、hierarchical chunking、fixed-size chunking,還有透過 Lambda 的自訂 chunking。它也說可以接 LangChain 和 LlamaIndex。這代表它不是只想吃掉所有工具,而是把常見拼裝方式收進來。
“Retrieval augmented generation is a way to help a language model generate answers using information from outside its training data,” said Rohit Prasad, senior vice president and head scientist for Amazon Bedrock.
這句話很直白。RAG 的核心不是模型多會講,而是能不能把外部資料接進來。你如果做過企業 AI,就知道真正難的是資料對齊,不是模型聊天。
所以 AWS 把 parser、chunker、retriever、generator 放在一起。這樣做的好處,是少掉很多手工 glue code。壞處是,你也更依賴 AWS 的做法和限制。
- 支援圖像、表格、音訊、影片
- 支援 semantic 與 hierarchical chunking
- 可用 Lambda 自訂切塊
- 可接 LangChain 與 LlamaIndex
檢索層有什麼差別
Bedrock Knowledge Bases 不只是回傳幾段文字。AWS 說它還能做 reranking。這點很現實,因為檢索品質常常比模型選哪一顆更重要。
如果檢索抓錯資料,後面再強的 LLM 都會亂答。很多人以為換模型就會變準,其實常常只是把同樣的錯誤講得更順。這就是 RAG 工程最煩的地方。
另外,AWS 也把圖譜檢索放進來。若你選 Amazon Neptune Analytics 當向量庫,它說可以自動建立 embeddings 和 graph,把不同來源的關聯串起來,再用 GraphRAG 做檢索。
這種設計適合知識關聯很重的場景。像產品文件、維修手冊、內部政策、法規條文。你不只要找答案,還要知道答案跟哪幾份資料互相呼應。
- Retrieve 會回傳相關結果
- RetrieveAndGenerate 直接產生回答
- 可用明確或隱式 filters
- reranking 幫助排序更準
如果你在做客服助理,這些差異很有感。因為客服最怕答非所問。只要引用錯一條文件,使用者就會直接翻白眼。
所以我會把這個服務看成「少一層基礎建設」。它不是魔法。它是把幾個本來就要做的元件,打包成 AWS 幫你維運的版本。
跟自己架 RAG 有什麼差別
自己架 RAG 的好處,是控制力高。你可以自己決定 chunk 多大、向量庫怎麼選、檢索怎麼調、引用怎麼顯示。缺點也很明顯,就是每一段都要自己顧。
只要資料一變,整條鏈就可能出問題。文件格式改了、欄位多了、權限變了、來源換了,工程師就得重測。這種維運成本,常常比 demo 階段想像得高很多。
AWS 想解的,就是這個痛點。對已經在 AWS 上跑服務的團隊來說,接 Bedrock 比自己串一套完整 RAG 快很多。尤其是你本來就用 S3、Aurora、OpenSearch 的時候。
但也不是每個團隊都適合。你如果資料來源很怪,或想保留高度可攜性,自己架還是比較自由。說白了,這題就是速度換控制。
- 自架:控制力高,但維運重
- 託管:上線快,但依賴 AWS
- 既有 AWS 用戶最容易受益
- 特殊資料系統仍可能要自建
產業脈絡怎麼看
RAG 這幾年會紅,不是因為大家愛玩新名詞。是因為企業真的需要把私有資料接進 LLM。沒有這層,模型很會講,但不一定知道你公司的規則。
這也是為什麼幾乎每家雲端平台都在推自己的 RAG 工具。Google Cloud 有自己的生成式 AI 工具鏈,Microsoft 也把 Azure AI 和企業資料整合得很深。AWS 這次的做法,就是把它最擅長的雲端基建思維搬進 AI 應用層。
真正的競爭點,不是誰模型最會講。是誰能讓企業更快把資料接進去,還能管權限、來源、引用和維運。這些才是老闆會買單的地方。
對開發者來說,這類服務的價值很直接。你少寫很多膠水程式。你也少踩很多資料管線的坑。只是,少寫程式不代表少想架構,這點千萬別誤會。
接下來怎麼選
如果你的專案已經在 AWS 上,資料也多半放在 S3、Aurora 或 OpenSearch,我會先試 Bedrock Knowledge Bases。先做一個內部助理,測文件問答和來源引用,再決定要不要走更客製的路線。
如果你現在就在做 RAG,而且卡在資料接入和檢索品質,我會先看它能不能幫你少掉 30% 到 50% 的整合工時。這種服務最實際的價值,通常不是功能清單,而是讓團隊少熬幾週。
我自己的判斷很簡單。能用託管服務先跑,就先跑。等你真的碰到權限、延遲、成本或資料格式的極限,再回頭拆架構也不遲。你如果最近在評估企業 AI,這個服務值得先丟進 shortlist。
下一步最值得做的事,不是先挑模型,而是盤點你公司現在有哪些資料源,哪些可以直接接,哪些一定要自訂。這會比空想模型能力更有用。