更簡單的毫米波波束域去噪器
這篇論文提出一個低複雜度的毫米波 massive MIMO 波束域去噪方法,結合低解析度 ADC 雜訊模型與硬體友善設計,目標是讓演算法更適合 FPGA 落地。
這篇論文提出一個低複雜度的毫米波 massive MIMO 波束域去噪方法,目標是把低解析度 ADC 的失真一起處理掉,還能做成比較適合硬體落地的版本。
毫米波 massive MIMO 的通道估計本來就不輕鬆。天線數量大、通道又稀疏,再加上低解析度 ADC 會帶來額外量化雜訊,整個問題很容易從「估得準不準」變成「算得動算不動」。這篇論文就是在解這個組合拳。
它的重點不是再做一個更複雜的最佳化器,而是把去噪流程壓到更簡單。作者明確把方法朝硬體友善方向設計,還提到 VLSI 架構與 FPGA 實作。對做無線 DSP、baseband pipeline、或想把演算法放上 FPGA 的開發者來說,這種取向很直接:少一點理論上的華麗,多一點實際可部署性。
這篇論文想解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
論文鎖定的是使用低解析度 ADC 的 mmWave massive MIMO 系統。低解析度 ADC 的好處很現實:可以降低功耗,也能壓低硬體成本。但代價也很明顯,就是量化雜訊會讓通道估計更難做。
另一方面,毫米波通道在 beamspace 裡本來就有稀疏性。這代表大多數 beamspace 分量其實不是有用訊號,而是偏弱或接近雜訊的成分。問題就在於,如何把真正有意義的分量挑出來,同時不要付出太高的計算成本。
作者想處理的不是單一問題,而是兩個限制一起來:一是通道稀疏,二是 ADC 失真。這也是這篇工作的核心價值。它不是只針對理想通道做去噪,而是直接把低解析度硬體的現實一起納入模型。
方法到底怎麼運作
這個方法的核心想法,可以理解成一個 Bayesian binary hypothesis testing。白話一點,就是對每個 beamspace 分量判斷:它比較像是「有用訊號」還是「雜訊主導」。
為了支撐這個判斷,論文採用 Bernoulli-complex Gaussian prior。這種先驗的意思是,beamspace 通道大多是稀疏的,只有少數分量會真的活躍;而那些活躍分量則用複數高斯分布來描述。這和毫米波通道在 beamspace 裡的稀疏特性是對得上的。
另一個關鍵設計,是作者沒有把熱雜訊和量化雜訊拆開來複雜處理,而是把它們合併成一個 composite noise term。這樣做的好處很直接:模型比較簡潔,推導也比較好做,但仍然有把 ADC 造成的失真算進去。
基於這個模型,作者推導出 closed-form threshold,接著用 hard-thresholding 的方式做去噪。也就是說,每個分量不需要反覆迭代,也不需要在一堆參數裡搜尋最好的設定,而是可以直接做保留或丟棄的判斷。
這正是它強調低複雜度的原因。論文明講,這個方法避開了矩陣反矩陣、迭代最佳化、參數搜尋這些重操作,並且讓計算複雜度對天線數量呈現近線性成長。對實作端來說,這種設計會比很多「理論上很漂亮」的方法更容易往硬體搬。
如果把它拆成工程流程,可以粗略理解成下面這樣:
- 先把 beamspace 當成稀疏訊號來看。
- 把低解析度 ADC 的量化雜訊納入統一噪聲模型。
- 對每個分量做訊號/雜訊的二元判斷。
- 用閉式門檻做硬閾值去噪。
- 避免矩陣反演與迭代式求解。
論文實際證明了什麼
從摘要提供的資訊來看,作者主張這個算法能在維持接近既有高計算量方法表現的同時,把計算成本明顯壓低。也就是說,它要解的是一個典型 trade-off:效果不要掉太多,但成本要明顯下降。
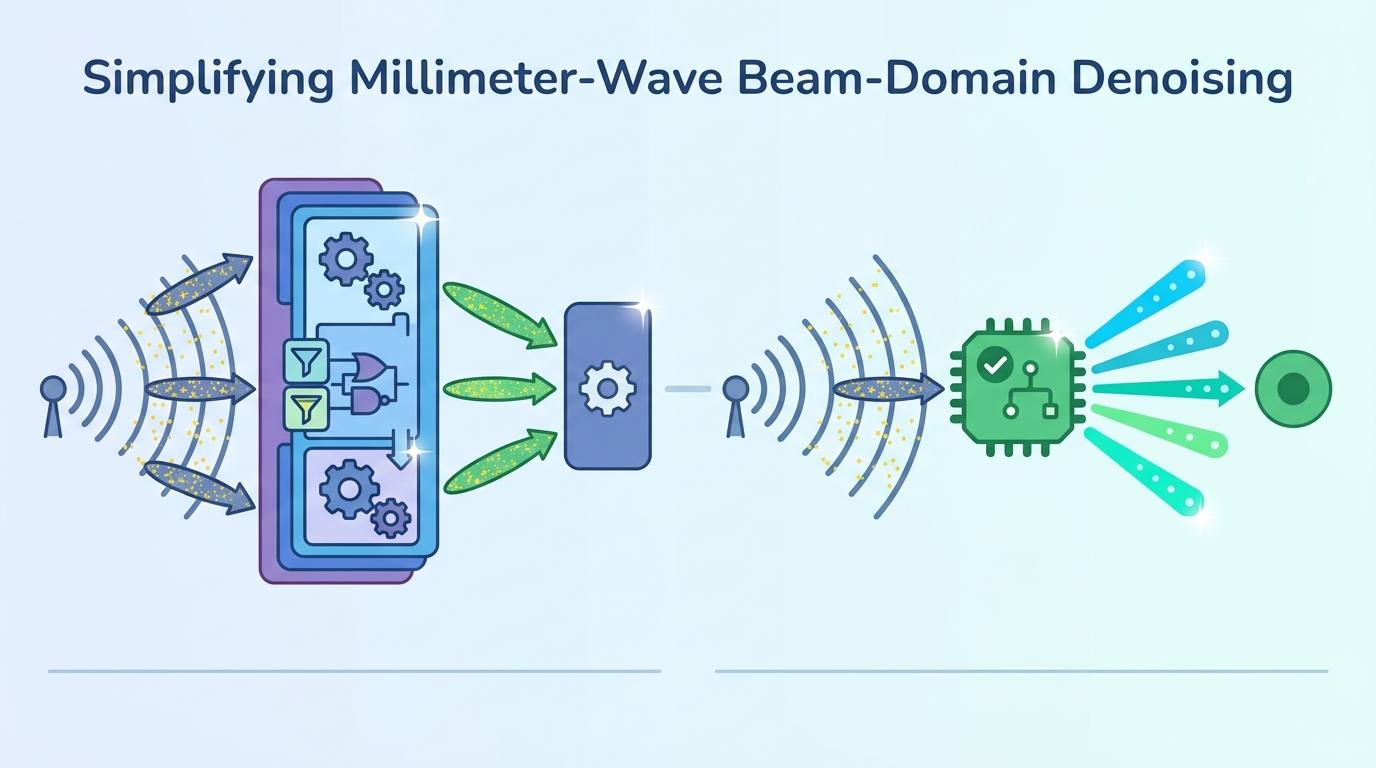
這篇工作的另一個重點不是只停在演算法層,而是往硬體落地走。作者還做了 hardware-efficient VLSI architecture,並且把設計實作在 AMD-Xilinx Kintex UltraScale+ KCU116 FPGA 平台上。這代表它不是只在模擬環境裡說自己省算力,而是把硬體實作也納入貢獻。
根據摘要,這個硬體設計透過針對實作限制的簡化與有效的處理結構,帶來更低的延遲與更少的硬體資源使用量,並且在天線數增加時呈現 sublinear scaling。這些都是很工程導向的訊號,表示作者關心的不只是數學形式,也包括實際部署的成本。
不過,這裡也要講清楚:摘要沒有公開完整 benchmark 細節。它沒有提供明確的 latency 數字、resource 數量、或是和哪些 baseline 比到什麼程度的完整數據。因此,若要判斷實際性能差距,還是得回到論文正文看完整實驗設定。
就目前 raw 資料能確定的內容來說,這篇論文至少證明了兩件事:第一,beamspace sparsity 可以被用來做簡潔的硬閾值去噪;第二,這個設計不只是概念上低複雜度,也被作者往 FPGA 實作方向推了一步。
對開發者有什麼影響
如果你是做無線通訊、DSP、或硬體加速的人,這篇論文的價值在於它很明確地站在「可部署」那一邊。很多通道估計方法在 paper 裡看起來很強,但一碰到 FPGA、ASIC、或低功耗 baseband 平台就會卡住,因為矩陣運算和迭代流程太重。
這篇的思路剛好相反。它先接受 beamspace 的稀疏結構,再把低解析度 ADC 的失真合併進簡化模型,最後用閉式門檻做出決策。這種做法對硬體工程很友善,因為它把不必要的運算拿掉了。
對實作端來說,這也意味著幾個方向值得注意。像是如果你在做 mmWave receiver prototype,或是在評估低功耗設計時刻意降低 ADC 解析度,這種方法就很有參考價值。它不是要把每個物理效應都完整建模,而是要找出一個夠快、夠簡單、又能支撐實際判斷的統計模型。
這也是這篇論文比較值得被記住的地方:它不是單純提出一個新公式,而是把演算法設計、噪聲模型、和硬體實作拉在一起看。對開發者而言,這類研究的意義往往不只在準確率,而是在能不能真的塞進系統裡跑。
限制與還沒回答的問題
先講最直接的限制。摘要沒有給出完整 benchmark 數字,所以我們目前不知道它在不同場景下的實際提升幅度,也不知道和哪些既有方法相比,差距到底有多大。這會影響你判斷它是不是值得換掉既有方案。
另外,這個方法建立在 Bernoulli-complex Gaussian prior 與 composite noise approximation 上。這代表它的效果會依賴模型假設是否貼近真實系統。摘要沒有說明這個閉式門檻對模型偏差有多敏感,也沒有說不同 ADC 解析度下的穩定性如何。
硬體部分也是一樣。雖然摘要提到 FPGA 實作、低延遲、低資源使用量,以及 sublinear scaling,但沒有提供細部資源拆解。對工程師來說,這些資訊很重要,因為「省多少」和「怎麼省」會直接影響是否能移植到其他平台。
所以,這篇論文目前最穩的結論不是「它已經完美解決 mmWave 通道估計」,而是「它提供了一條更簡單、也更硬體導向的路線」。如果你的目標是做可落地的毫米波接收器,這條路線值得關注;如果你要的是完整的性能比較與部署成本分析,還是得看正文的實驗與實作細節。
整體來看,這篇工作很像是在提醒開發者:在 mmWave massive MIMO 這種又稀疏、又吵、又吃硬體的場景裡,最有價值的未必是最複雜的方法,而是能把問題切乾淨、再用最少的運算做出可靠判斷的方法。