LLM 評審也會不穩
這篇論文做了一個壓力測試工具,檢查 LLM 當評審時,會不會因為格式、改寫、篇幅或標籤翻轉而判斷不一致。

這篇在講一個壓力測試工具,檢查 LLM 當評審時會不會因為格式、改寫、篇幅變化而判斷不一致。
Judge Reliability Harness: Stress Testing the Reliability of LLM Judges 盯上的不是模型生成能力,而是另一個更容易被忽略的問題:當你把 LLM 拿來當評審,它到底穩不穩。這篇摘要的重點很直接,作者想知道,只要把同一段回答換個寫法、換個排版、改長一點或短一點,LLM judge 的判斷會不會跟著飄。
這件事對開發者很實際。現在越來越多人把 model-as-judge 用在評估、排序、審核,甚至自動化流程裡。表面上看,這種做法省人力、也容易擴充;但如果評審本身對字面變化很敏感,整條評估管線就可能被悄悄帶偏。你以為自己在量測答案品質,實際上可能是在量測提示詞長相。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
LLM judge 之所以受歡迎,是因為它能把人工評分的成本壓下來。很多場景不可能每次都找人逐筆看答案,所以就改用模型來判斷另一個模型有沒有把任務做好。問題是,這套流程成立的前提,是評審要夠穩定,至少不能因為輸入外觀的小變化就改變結論。
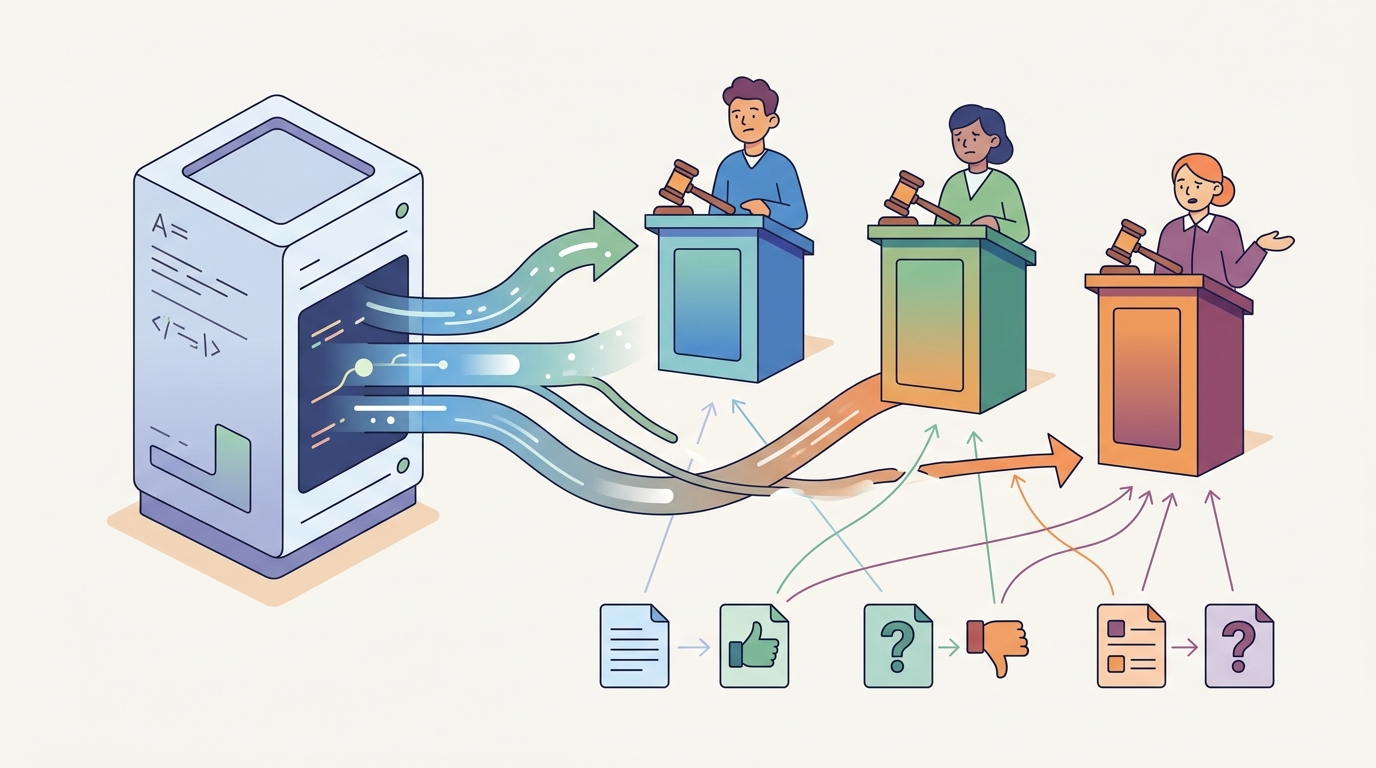
這篇論文就是在補這個缺口。摘要沒有把 LLM judge 說成沒用,而是很務實地指出:即使只是表層變動,也可能讓判斷一致性出問題。對工程團隊來說,這不是抽象的研究疑慮,而是直接影響 evaluation pipeline 的風險。很多系統都默認格式、改寫、篇幅長短不該影響分數,但這篇看起來就是在挑戰這個默契。
作者提出的工具叫做 Judge Reliability Harness。從摘要看,它不是要做一個新的 judge,也不是要取代現有評審,而是要拿來做壓力測試。換句話說,它比較像診斷層,不是替代層。這種定位很重要,因為它對準的是可靠性檢查,而不是再造一個更會打分的模型。
方法怎麼運作
摘要本身沒有把完整實驗流程交代得很細,所以這篇沒有公開完整 benchmark 細節。就已知資訊來看,核心做法很單純:把 LLM 產生的回答做不同形式的變形,再丟給 judge,看它的判斷是否保持一致。
這些變形包含幾種摘要明確點出的情況:
- 簡單的文字格式變化
- 改寫或 paraphrasing
- 篇幅變長或變短,也就是 verbosity 變化
- 把 LLM 產生回答中的 ground-truth label 翻轉
白話一點說,這個 harness 想問的是:如果答案的實質內容沒有變,評審會不會還是給出同樣的判斷。如果答案只是看起來不一樣,結果就跟著變,那就代表 judge 可能不是在理解任務本身,而是在吃輸入外觀的影響。
這也是這類工具最有價值的地方。很多評估系統都會把格式整理、提示詞模板、輸出長度當成工程細節,但對 judge 來說,這些細節可能不是細節,而是會改變輸出分數的變因。Judge Reliability Harness 的目標,就是把這種脆弱性抓出來。
論文實際證明了什麼
從摘要能確定的結果不多,但方向很清楚。作者做了 preliminary experiments,發現 LLM judges 會出現 consistency issues。摘要特別提到的衡量點,是 judge 在判斷另一個 LLM 是否完成任務時的 accuracy。

不過,這篇摘要沒有公開完整 benchmark 細節,所以我們不能從這份來源直接推論具體數字、模型名稱、資料集,或是哪一個 judge 比較強。也沒有看到表格、排名、或跨模型比較。換句話說,這份摘要傳達的是一個早期警訊,而不是一份完整的 leaderboard。
但即使如此,訊息還是很有份量。因為它指出的不是難題本身,而是日常工作裡最容易被忽略的失真來源:格式、改寫、篇幅、標籤翻轉。這些因素本來常被視為不影響語意的表面差異,但在 judge 身上,它們可能已經足夠讓結果偏移。
對評估流程來說,這代表一件事:如果你的 judge 會被這些表層變化帶著跑,那麼最後的分數可能同時混進了答案品質、呈現方式,以及 prompt 包裝的影響。這不是單純的噪音問題,而是你以為在量測 A,結果卻混進了 B 和 C。
對開發者有什麼影響
如果你有在做 LLM 評估、模型排序、回歸測試,或自動化審核,這篇的訊號很明確:LLM-as-judge 不能只看方便,還要看穩定性。當評審變成基礎設施的一部分,它的可靠性就會直接影響產品決策。
最現實的風險有幾個。第一,排名可能不穩。第二,回歸測試可能被格式改動干擾。第三,自動 gating 可能因為輸入包裝不同而放行或擋下不一樣的結果。這些都不是理論上的小毛病,而是會直接進到工程流程裡的問題。
這篇論文的實務意義,不是叫大家立刻不用 LLM judge,而是提醒你要把它當成需要驗證的元件。就像你不會直接相信一個沒做壓力測試的服務,評審模型也不該只因為它看起來很會講,就默認它很穩。
如果團隊真的要上 LLM judge,至少要把它放進 perturbation test 的思維裡。也就是說,不只看一次分數,而是要看在不同寫法、不同長度、不同排版下,結果會不會一致。Judge Reliability Harness 看起來就是朝這個方向設計的。
限制與還沒回答的問題
這份來源也有明顯限制。首先,摘要太短,所以很多關鍵資訊都沒公開。包括實驗規模、測試任務、使用了哪些 judge model、以及 harness 是否涵蓋更多失敗模式,摘要都沒有交代。
其次,我們也不知道這個工具是偏研究用途、工程用途,還是兩者都想兼顧。摘要只說 code is available,但在這份 raw 資料裡沒有提供可用連結,也沒有實作細節可供延伸判讀。
再來,摘要沒有回答一個更大的問題:什麼樣的 judge 才算夠穩。它指出了不一致,但沒有說哪種修正方式有效,也沒有說可靠性要怎麼量化到可以安心上線。這些都還是空白。
但就算資訊有限,這篇還是有價值。因為它把一個常被省略的事實講白了:LLM judge 不只是在評分,它也會被輸入表面影響。對台灣開發者來說,這種提醒很重要,尤其當你開始把模型評估自動化之後,最該先確認的往往不是模型多強,而是它到底穩不穩。
總結來看,Judge Reliability Harness 是一個偏診斷、偏壓測的工具。它不是在宣告模型評審失敗,而是在提醒大家:如果你把 LLM 拿來當 judge,就要先證明它不會因為格式和寫法的小變動而失常。這件事看起來很基礎,但對真正要落地的系統來說,往往就是最重要的那一步。