Why multimodal MoE models get distracted
A study of multimodal MoE models finds visual inputs can derail routing to reasoning experts, and a routing-guided fix improves results.
Multimodal mixture-of-experts models can recognize what is in an image, then stumble on the reasoning step that follows. In Seeing but Not Thinking: Routing Distraction in Multimodal Mixture-of-Experts, the authors argue that the problem is not just semantic mismatch between image and text, but a routing issue: visual inputs can pull the model away from the task-relevant reasoning experts it should be using.
That matters for anyone building vision-language systems. If a model answers the same question correctly in text but fails when the exact same problem is shown with an image, the bottleneck is not always perception. Sometimes the model sees fine and still routes itself into the wrong internal path.
What problem the paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper starts from a specific failure mode in multimodal MoE systems: they can accurately perceive image content, yet still fail on the reasoning that comes after. The authors call this pattern “Seeing but Not Thinking.”
That distinction is important. A lot of debugging effort in multimodal systems focuses on alignment between image and language representations. This paper says that is not the whole story. The models can share semantics across modalities and still underperform when the input is visual rather than textual.
In practical terms, this is the kind of issue that shows up when a system handles a question one way in a text-only prompt and another way when the same content is embedded in an image. For developers, that creates a reliability problem: the model’s behavior depends on the input format, not just the task.
How the method works in plain English
The authors analyze multimodal MoE routing behavior layer by layer. Their first finding is that cross-modal semantic sharing does exist in these architectures, which helps rule out a simple “the image and text spaces don’t line up” explanation.
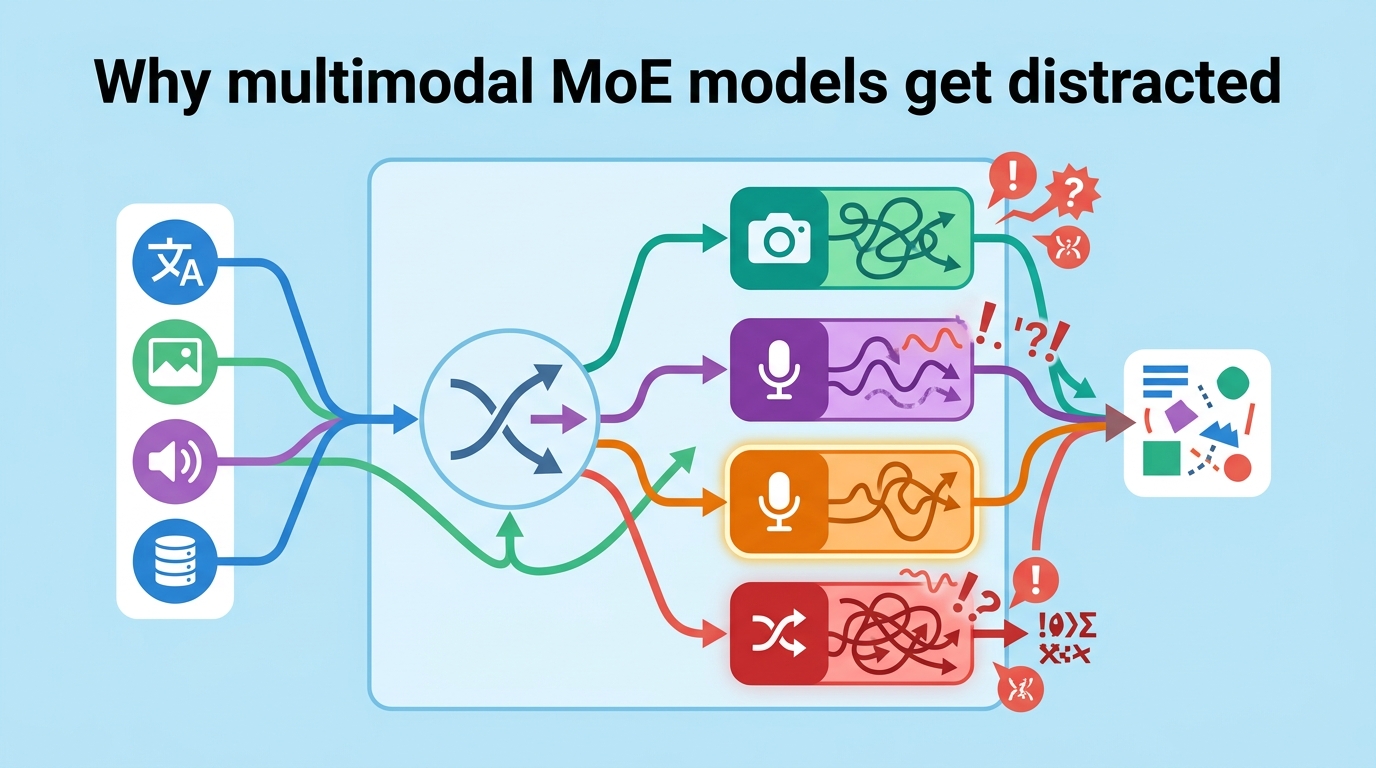
They then look at how experts are activated across layers and find a separation between visual experts and domain experts. According to the paper, image inputs cause significant routing divergence from text inputs in the middle layers, and that is where domain experts are concentrated.
From there, the paper proposes a “Routing Distraction” hypothesis. The idea is straightforward: when the model sees a visual input, the routing mechanism does not sufficiently activate the experts that are needed for reasoning about the task. In other words, the model’s internal router gets distracted by the modality and fails to send the signal to the right experts.
To test that idea, the authors introduce a routing-guided intervention method. The abstract says this method increases domain expert activation. The implementation details are not included in the source notes, so the safest reading is that the intervention nudges the router toward reasoning experts rather than changing the underlying task or the image itself.
What the paper actually shows
The paper evaluates the approach on three multimodal MoE models across six benchmarks. That is enough to suggest the effect is not isolated to one architecture or one dataset, but the abstract does not list the benchmark names or their exact scores.
What it does provide is the headline result: the routing-guided intervention produces consistent improvements, with gains of up to 3.17% on complex visual reasoning tasks. The paper does not claim that every benchmark improves by the same amount, only that the direction is consistent across the tested models and tasks.
There is also a more conceptual result hiding in the analysis. The authors say domain expert identification captures cognitive functions rather than sample-specific solutions. That means the experts they identify seem to represent reusable reasoning roles, not just one-off patterns tied to a particular example.
That finding matters because it suggests the intervention can transfer across tasks with different information structures. In plain English: if the model has learned a reasoning function in one setting, the routing analysis can help surface and reuse it in another, even when the prompt format changes.
Why developers should care
For engineers building multimodal assistants, document understanding systems, or vision-language agents, this paper points to a concrete failure mode in MoE routing. The issue may not be that the model cannot understand the image. The issue may be that the router sends the computation down the wrong expert path once the image is present.
That changes how you would think about debugging. Instead of only checking perception quality or prompt wording, you would also inspect whether the model’s expert activation shifts when the same task moves from text to image. If performance drops in multimodal settings, routing behavior may be part of the root cause.
It also suggests a design direction: if a multimodal MoE system is meant to reason, not just perceive, then the router should be explicitly encouraged to activate domain experts during visual inputs. The paper’s intervention is one example of that idea, but the broader lesson is that expert selection itself may be a first-class optimization target.
- Visual inputs can change routing behavior even when semantic sharing exists.
- Reasoning failure may come from expert selection, not just weak perception.
- Routing analysis can reveal reusable cognitive functions in domain experts.
- Improving multimodal reasoning may require steering the router, not only scaling the model.
Limits and open questions
The abstract gives a clear direction, but not a full engineering recipe. We do not get the exact intervention mechanism, the benchmark list, or the full experimental setup from the source notes, so it is hard to judge how easy the method would be to reproduce in production systems.
There is also a scope question. The paper studies three multimodal MoE models, which is a meaningful start, but not proof that the same routing distraction pattern appears in every multimodal architecture. The result is strong evidence for the tested class of models, not a universal law.
Another open question is operational: if domain expert activation is pushed too hard, does that ever hurt tasks that genuinely need more visual specialization? The abstract does not say. That tradeoff would matter in real deployments, where better reasoning on one class of inputs should not come at the cost of worse performance elsewhere.
Still, the paper’s core message is useful and practical. In multimodal MoE systems, the path from seeing to thinking is not automatic. If the router does not send visual inputs to the right reasoning experts, the model can perceive correctly and still fail the task.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10