RAG precision tuning can hurt retrieval accuracy
Redis research says tuning RAG embeddings for precision can cut retrieval accuracy by up to 40% and weaken agentic pipelines.

Redis found that tuning RAG embeddings for precision can reduce retrieval accuracy by up to 40%.
Enterprise teams keep trying to make retrieval-augmented generation more exact, but a new Redis research note says that push can backfire. In some setups, precision tuning improved one metric while quietly damaging the retrieval quality that LangChain-style agentic pipelines depend on.
The warning matters because RAG systems often fail in boring ways: a model retrieves the wrong chunk, cites a near-match, or misses the one document that answers the question. If the embedding model is tuned too hard for precision, the system can get pickier in a way that hurts recall and overall usefulness.
| Metric | Reported value | Why it matters |
|---|---|---|
| Retrieval accuracy drop | Up to 40% | Shows the quality hit can be large enough to change product behavior |
| Primary optimization goal | Precision | Improves exact matching, but can narrow what gets retrieved |
| Risk area | Agentic pipelines | Agents depend on high-quality retrieval before they can act |
Why precision tuning can hurt RAG
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
RAG embedding models are often tuned with a simple expectation: make retrieval more precise and the whole system gets better. The Redis research says that assumption is too neat. A model can become better at ranking close matches while becoming worse at surfacing broader, useful context.

That tradeoff matters because retrieval is not a single-score problem. A system that only returns the tightest semantic matches may miss supporting documents, edge cases, or the one source that resolves ambiguity. For knowledge assistants, customer support bots, and internal search tools, that can mean fewer correct answers even when benchmark precision looks healthier.
- Higher precision can reduce the pool of retrieved documents.
- Lower recall can hide the source that actually answers the question.
- Agent workflows can fail early if retrieval feeds them weak context.
That is the uncomfortable part of the finding: teams may celebrate a cleaner metric while the user experience gets worse. The problem is especially sharp in enterprise search, where queries are messy and the right answer often lives in a document that does not look like the query at all.
What Redis is warning teams about
Redis has been pushing deeper into AI infrastructure with tools for vector search, caching, and agent memory, so its research carries practical weight for teams already building on its stack. The company’s message is simple: do not assume that a precision gain in the embedding layer translates into better retrieval in production.
That warning is especially relevant for agentic systems, where retrieval is the first step in a chain. If the retrieved context is thin or biased toward near-duplicates, the agent may answer with confidence while missing the broader factual picture. Once that happens, downstream tools inherit the error.
“There is no free lunch in machine learning,” said Andrej Karpathy.
Karpathy’s line fits this story well. Precision gains often come with a cost somewhere else, and in RAG that cost can show up as weaker recall, worse grounding, or a narrower set of documents feeding the model.
How this compares with the usual RAG playbook
Most RAG teams already know they need to balance retrieval quality, reranking, chunking, and model choice. What this research adds is a more explicit warning that optimization at one layer can distort the rest of the stack. The result is a system that looks improved in a lab and underperforms in real use.
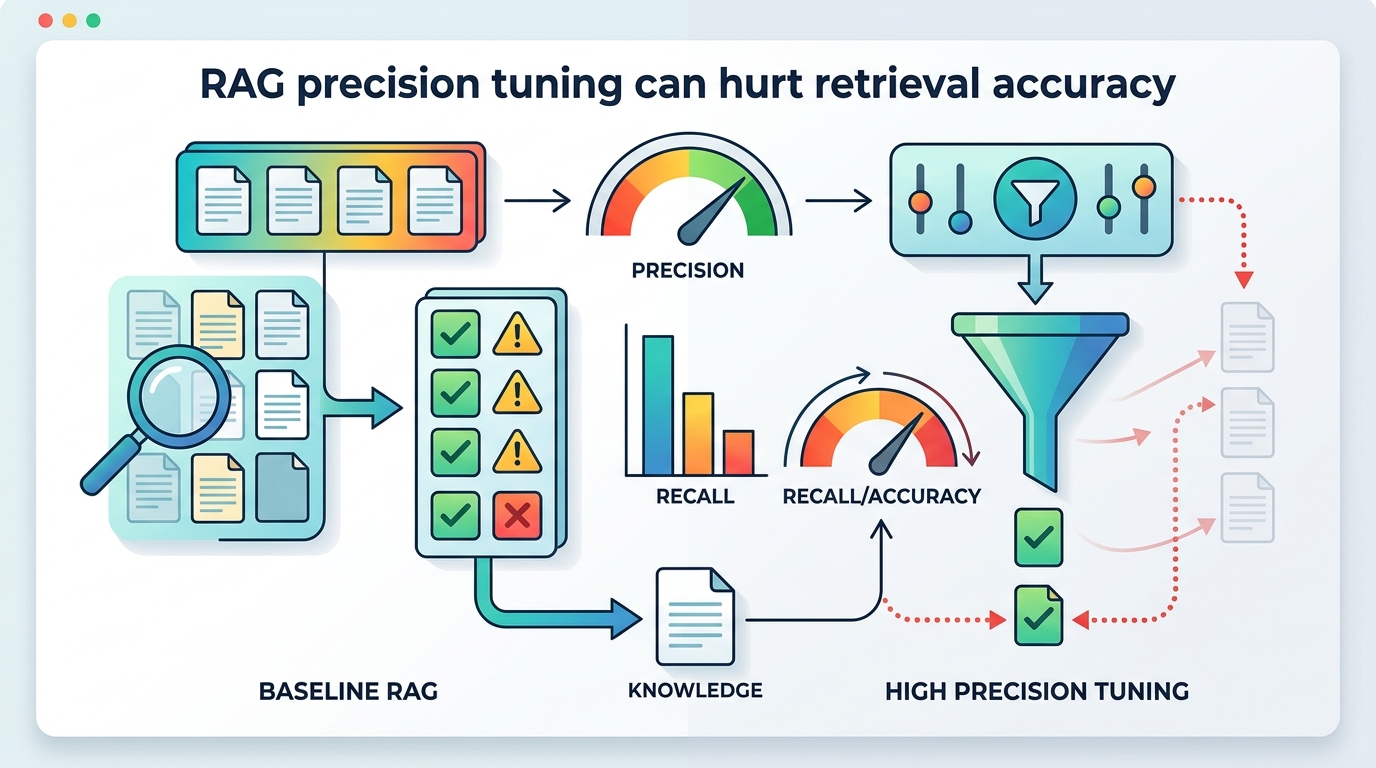
Here is the practical comparison teams should keep in mind:
- Precision-first tuning: tighter matches, smaller candidate sets, higher chance of missing useful context.
- Recall-aware tuning: broader retrieval, more context for the generator, more work for reranking and filtering.
- Production-focused tuning: balanced metrics, query diversity testing, and human evaluation on real tasks.
That last approach is the one most teams skip, usually because it takes more time. But if a retrieval layer can lose 40% accuracy after a tuning change, synthetic benchmarks alone are not enough. Teams need tests that reflect messy user prompts, long-tail questions, and the documents users actually care about.
It is also worth comparing the story with how vector databases and agent frameworks are marketed. Tools like Pinecone, Weaviate, and LangChain make it easy to wire up retrieval, but they cannot rescue a bad embedding strategy on their own. The model choice still sets the ceiling.
What teams should do next
The lesson here is not to stop tuning embeddings. It is to stop treating precision as the only score that matters. If your RAG system powers customer support, analyst workflows, or autonomous agents, you need to measure how many correct documents are retrieved, how often the right answer is missed, and how the system behaves on real query sets.
In practice, that means running A/B tests on retrieval quality, watching recall alongside precision, and checking whether reranking or chunking changes the result more than the embedding model itself. It also means keeping an eye on failure modes in agentic pipelines, because a small retrieval regression can cascade into a much larger product bug.
The next question for teams is simple: if your embedding tweak raises precision by a few points but cuts useful retrieval by double digits, which metric are you actually optimizing for? The answer will decide whether your RAG system gets smarter or just more selective.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10