Tag
RAG
RAG, or retrieval-augmented generation, combines search with model output so answers can be grounded in source data. This tag covers vector databases, hybrid search, indexing, recall, and evaluation for knowledge bases, semantic search, and enterprise assistants.
23 articles
2026 domain-specific LLM benchmarks map
Kili Technology maps 2026 vertical LLM benchmarks across medicine, law, finance, code, cybersecurity, multilingual, and multimodal use cases.
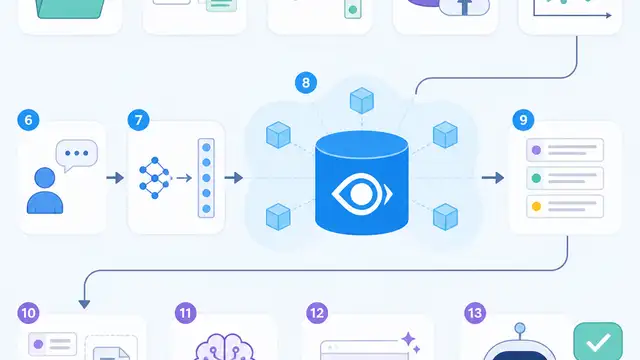
How to Build a Milvus RAG Stack in 13 Steps
Build a production-ready Milvus RAG stack with embeddings, hybrid search, and LangChain.

Prompt engineering turns vague asks into usable outputs
I break down prompt engineering into practical patterns, with a copy-ready template for better LLM outputs.
Oracle: AI doesn’t need another database
InfoWorld argues vector search belongs in existing databases, not a separate stack, as vendors like Pinecone move toward retrieval quality.

How to Choose a Vector Database in 2026
A practical guide to selecting a 2026 vector database by scale, pricing, and architecture.
How to Add Temporal RAG in Production
Add a temporal reranking layer to RAG so fresh, valid, and versioned facts rank correctly.

Why RAG is ending for agentic AI
RAG is the wrong layer for agentic AI, and compilation-stage knowledge systems will replace it.
Why RAG Needs a Self-Healing Layer, Not Just Better Prompts
RAG should be treated as a failure-prone system that needs real-time self-healing, not prompt tuning.
Why Open-Source LLMs Must Be Judged by Workload, Not Hype
Open-source LLMs in 2026 should be chosen by workload fit, not benchmark hype.
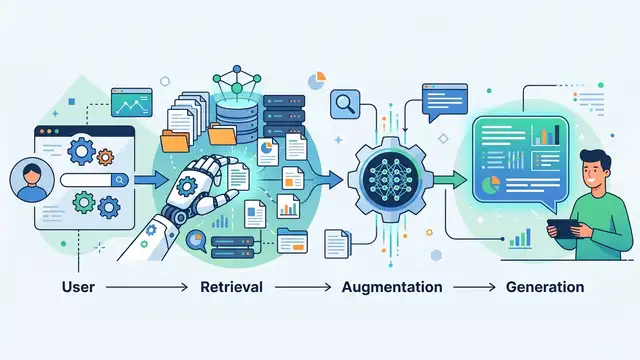
Retrieval-Augmented Generation, Explained Simply
RAG lets large language models pull fresh facts from documents before answering, which cuts hallucinations and adds citations.

RAG precision tuning can hurt retrieval accuracy
Redis research says tuning RAG embeddings for precision can cut retrieval accuracy by up to 40% and weaken agentic pipelines.
AWS Bedrock Knowledge Bases simplifies RAG
Amazon Bedrock Knowledge Bases helps teams build RAG apps with managed ingestion, retrieval, citations, and structured-data queries.
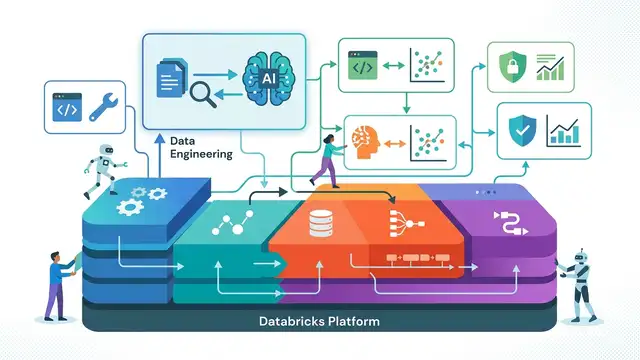
Why Databricks RAG Is a Platform Play, Not a Feature
Databricks treats RAG as an end-to-end platform problem, and that is the right way to build it.
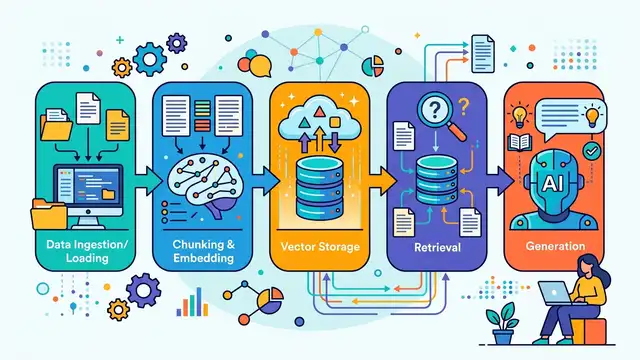
How to Build a RAG Pipeline in 5 Steps
Build a retrieval-augmented generation pipeline that grounds AI answers in your own data.

Actian’s VectorAI DB Claims 22x Faster Search
Actian says VectorAI DB embeds vector search inside apps and delivers up to 22x faster retrieval than common alternatives.
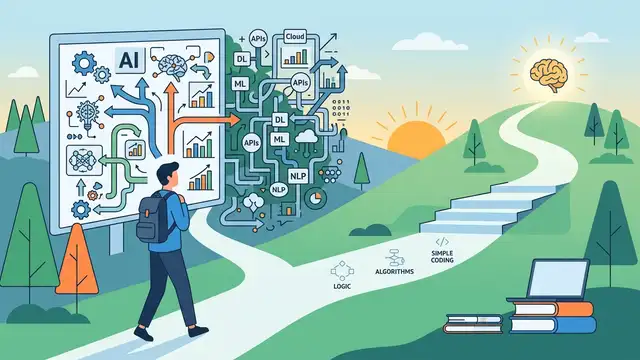
Why the 2026 AI engineer roadmap is the wrong starting point
The 2026 AI engineer roadmap is too broad to be the first plan you follow.

MathNet: Global Multimodal Math Reasoning & Retrieval
MathNet adds 30,676 Olympiad problems across 47 countries and tests both solving and retrieval for multimodal models.

Qdrant vs Milvus vs Weaviate for RAG in 2026
Qdrant, Milvus, and Weaviate power different RAG needs in 2026. Here’s how they compare on latency, scale, hybrid search, and cost.

IBM hits 100B vectors on one server
IBM says its CAS prototype indexed 100 billion vectors on one server, with 694 ms latency and 90% recall for RAG.

How Windsurf Flow Keeps Context Alive
Windsurf Flow updates AI context as you work. Here’s how RAG, Cascade, Memories, and rules shape every suggestion.

What OpenRAG Does for Enterprise AI
IBM’s OpenRAG packages retrieval, indexing, and model orchestration so teams can build grounded AI apps on their own data.
20 GitHub AI Projects to Watch in 2026
OpenClaw may top GitHub, but 2026’s AI list shows a bigger shift toward agents, workflow systems, RAG, and multimodal tools.

RAG in 2026: The Indispensable AI Bridge
In 2026, advanced Retrieval Augmented Generation (RAG) systems are essential for bridging large language models with enterprise knowledge, ensuring informed AI outputs.