Why Databricks RAG Is a Platform Play, Not a Feature
Databricks treats RAG as an end-to-end platform problem, and that is the right way to build it.
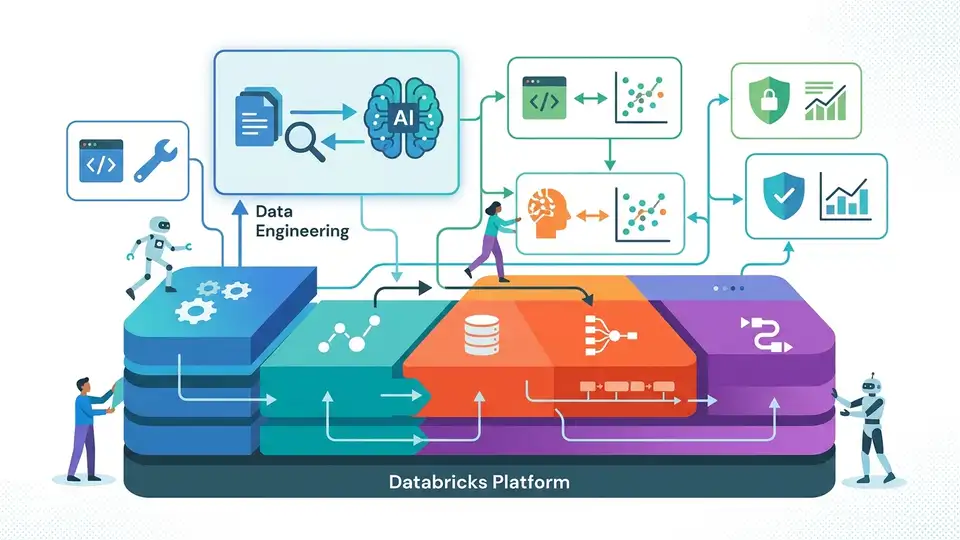
Databricks treats RAG as an end-to-end platform problem, and that is the right way to build it.
Databricks is right to frame retrieval-augmented generation as infrastructure, not a clever prompt trick. The company’s own guide puts retrieval, augmentation, generation, evaluation, monitoring, governance, and access control in the same conversation, because that is where RAG succeeds or fails. If the data pipeline is brittle, the chunks are bad. If retrieval is weak, the answer is weak. If monitoring is missing, production drift goes unnoticed. RAG is only as good as the system around it.
RAG fails when teams treat it like a prompt hack
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The basic RAG flow is straightforward: retrieve supporting data, add it to the prompt, then generate an answer. That simplicity tempts teams to think the hard part is writing a better prompt template. It is not. The hard part is building a retrieval layer that consistently surfaces the right evidence from messy enterprise data, then feeding that evidence into a model that can use it without hallucinating around the gaps.
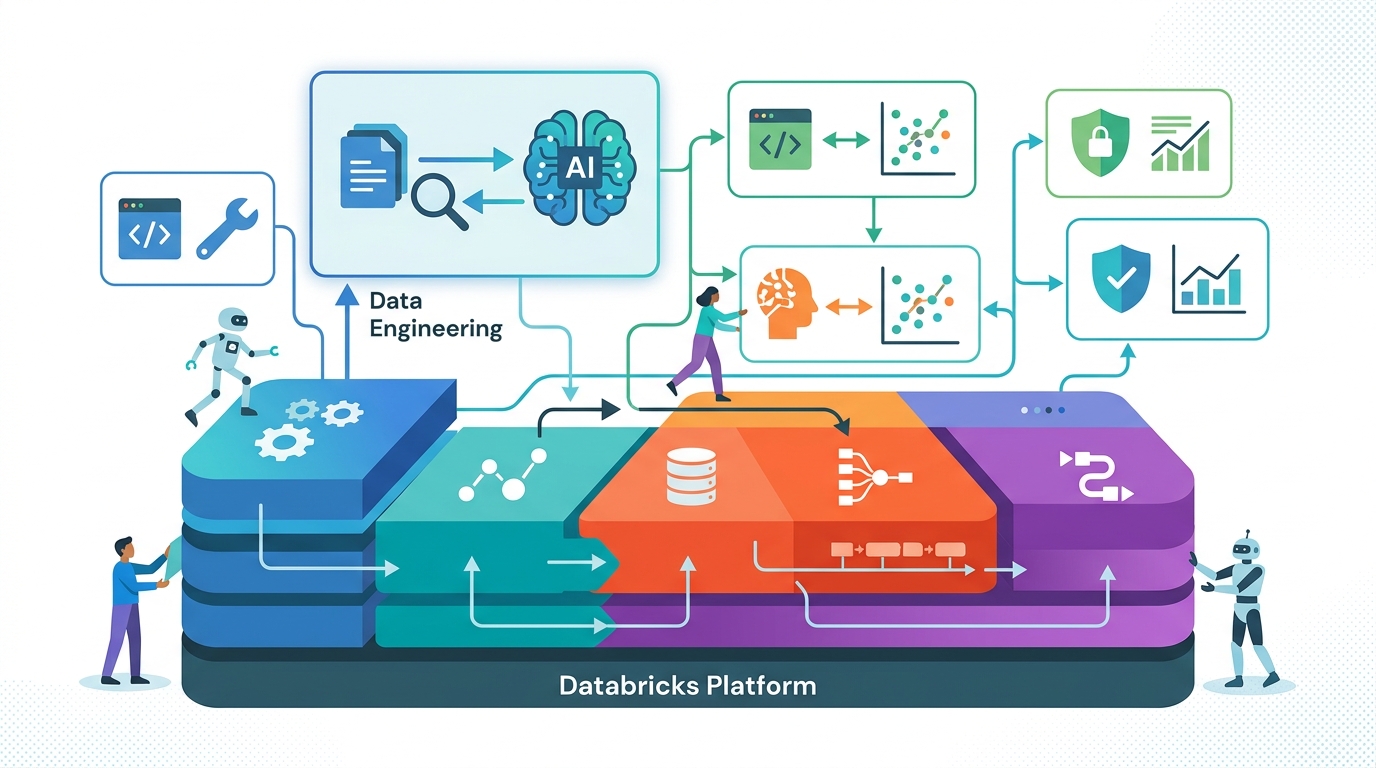
Databricks calls out the need for a data pipeline before the chain itself. That order matters. A company with PDFs, wikis, images, SQL tables, and API output does not have a prompt problem. It has an ingestion, indexing, and governance problem. If the source material is stale or poorly formatted, the model will produce confident nonsense no matter how polished the prompt looks.
Evaluation belongs at the center, not the end
Databricks is also correct to emphasize evaluation and monitoring as first-class components. In RAG, quality does not come from the model alone. It comes from retrieval quality, chunking strategy, prompt construction, and downstream generation. Change one upstream detail, such as document formatting, and the retrieved chunks can shift enough to alter the answer. That means “the app works” is not a meaningful test unless each stage is measured.
The practical proof is in production behavior. A RAG system that looks fine in a demo can fail under real user queries, new documents, or changing schemas. Databricks explicitly separates development-time evaluation from production monitoring, which is the right split. Development tells you whether the design is sound. Monitoring tells you whether the system is still sound after the data changes, the workload grows, and the business asks harder questions.
Governance is not optional when the data is proprietary
One of the strongest arguments for Databricks’ approach is security and access control. RAG is most valuable when it can answer questions over internal memos, emails, documents, and records that were never part of a foundation model’s training set. That is also where risk lives. If retrieval is not permission-aware, the system can expose information to users who should never see it. In an enterprise setting, that is a product failure and a compliance failure at the same time.
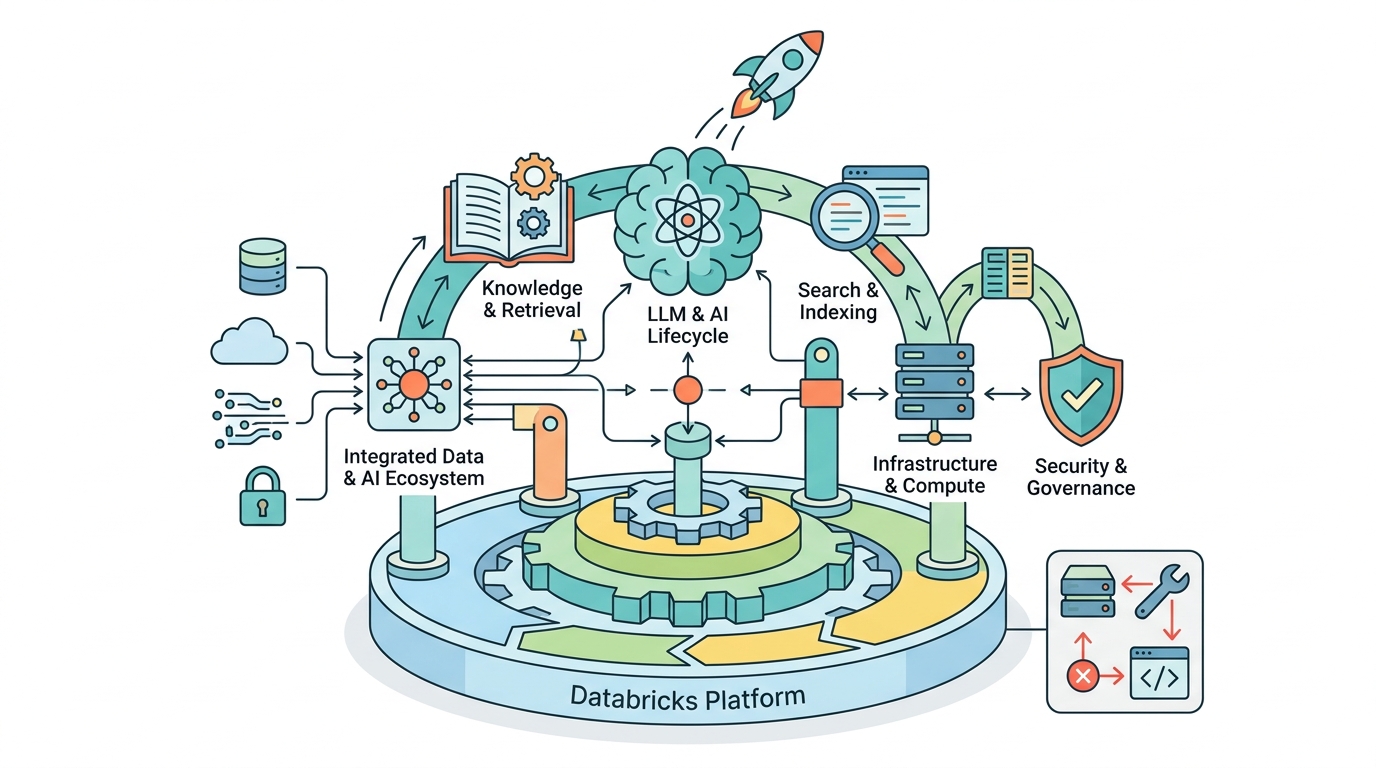
Databricks ties RAG to lineage, governance, and ACL-aware retrieval for a reason. The value of RAG is not just that it can answer more questions. It is that it can answer the right questions for the right user from the right data. Once you accept that, the platform argument becomes unavoidable: the team needs controls around data sources, indexes, serving, and observability, not a standalone chatbot bolted onto a warehouse.
The counter-argument
The best objection is that Databricks is overengineering a pattern that many teams can prototype with a vector database, an LLM API, and a few hundred lines of code. That is true for a narrow demo. It is also true that not every use case needs enterprise-grade governance, multi-format ingestion, or deep monitoring. For a small internal tool, the platform overhead can exceed the value of the first release.
But that objection stops at the demo stage. The moment a RAG app becomes business-critical, the missing pieces show up fast: broken retrieval, stale indexes, unclear lineage, and no way to explain why the model answered the way it did. Databricks is not claiming every RAG project needs a heavyweight platform on day one. It is claiming that serious RAG work inevitably becomes a systems problem, and that claim is correct.
What to do with this
If you are an engineer, design RAG as a pipeline with testable stages: ingestion, indexing, retrieval, prompt assembly, generation, evaluation, and monitoring. If you are a PM, define success in terms of answer quality, freshness, latency, and access control, not just “does it respond.” If you are a founder, build around a domain where proprietary data and auditability matter, because that is where a platform like Databricks creates defensible value instead of a thin wrapper around an LLM.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production