What OpenRAG Does for Enterprise AI
IBM’s OpenRAG packages retrieval, indexing, and model orchestration so teams can build grounded AI apps on their own data.
IBM’s OpenRAG is built for a very specific problem: large language models are smart, but they do not know your private docs, your policies, or last week’s product changes. IBM says OpenRAG is a single-package RAG platform built on Langflow, Docling, and OpenSearch, and that combination matters more than the marketing copy does.
RAG, short for Retrieval-Augmented Generation, is the idea that a model should look up relevant material before it answers. That sounds simple, but in practice it requires document ingestion, embeddings, search, reranking, prompt assembly, and model inference. OpenRAG packages those pieces so teams can wire them together without building every layer from scratch.
If you are trying to build an internal assistant, a support bot, or a compliance tool, the appeal is obvious: the system can answer from your documents instead of guessing from general training data. That changes the quality of answers, and it also changes the audit trail, because the response can be tied back to source material.
What OpenRAG actually is
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
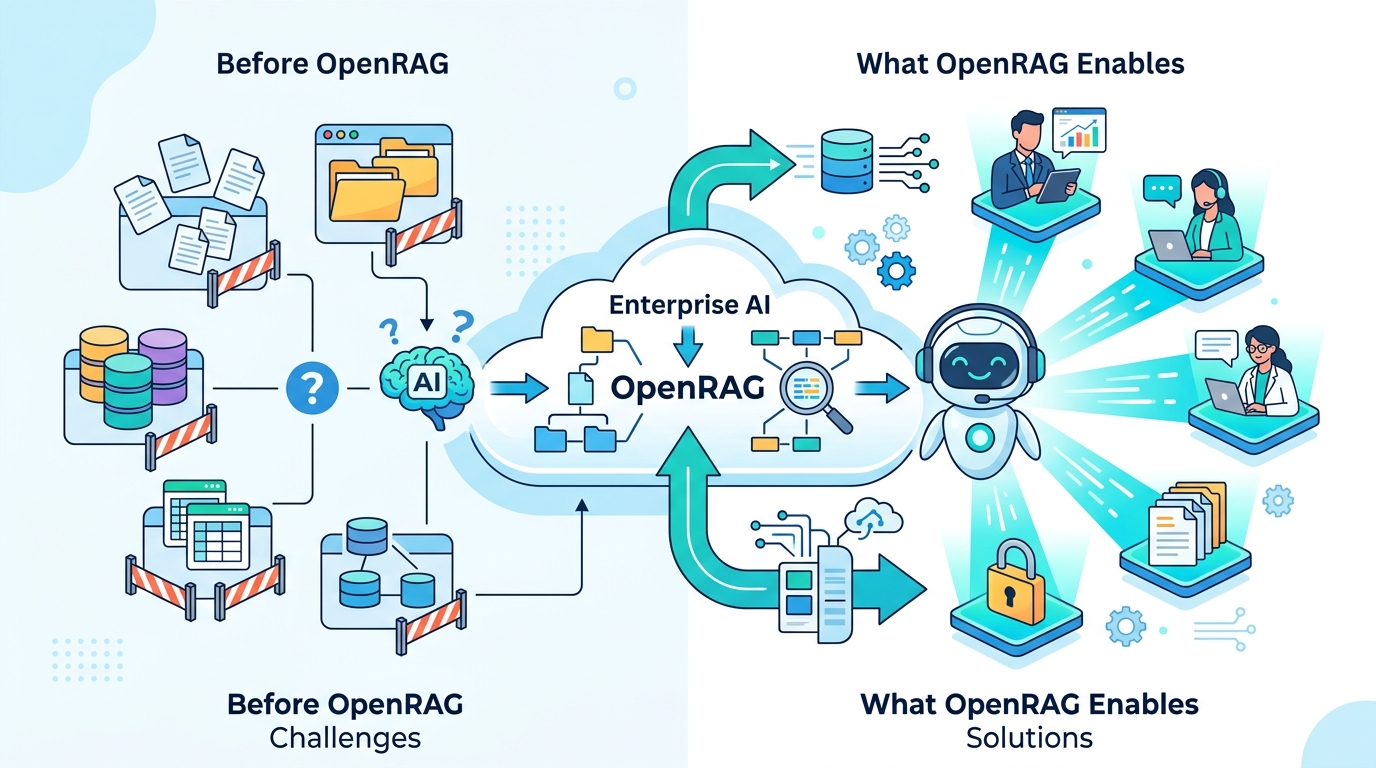
OpenRAG is IBM’s open source toolkit for building RAG systems that connect a model to external data sources such as documents, databases, and knowledge bases. IBM positions it as a complete stack for enterprises that want grounded answers from their own information rather than generic model output.

The basic flow is familiar if you have built with RAG before. A user asks a question, a retriever searches the index, the system ranks the best passages, and the model uses those passages to draft an answer. OpenRAG is designed to coordinate that flow across different storage systems, model hosts, and orchestration tools.
That flexibility matters because enterprise AI rarely lives in one neat box. One team may want OpenSearch for retrieval, another may already store data in IBM watsonx.data, and a third may want inference through IBM watsonx.ai or an external API. OpenRAG is built to let those choices coexist.
- OpenRAG is open source and built for enterprise RAG workflows.
- It uses Docling for document processing and OpenSearch for retrieval.
- It can work with self-hosted models, managed cloud models, or mixed setups.
- IBM says it fits assistant, search, and analytics use cases that depend on private data.
The important design choice here is modularity. In a lot of AI projects, the hard part is not the model. The hard part is everything around the model: parsing PDFs, indexing text, deciding when to retrieve, and keeping the whole system maintainable when data changes.
OpenRAG breaks those pieces apart so teams can swap components without rebuilding the entire application. That gives developers more control over governance, latency, and cost, which are usually the real constraints in production.
Why RAG still matters in 2026
RAG became popular because it solves a plain but painful problem: models hallucinate when they are asked about information they do not actually have. A model may write a fluent answer, but fluency is not the same thing as correctness. When the question depends on private documents, recent updates, or specialized jargon, retrieval is the safer path.
IBM’s own framing makes this clear. OpenRAG is meant to ground answers in data that the organization controls. That is especially useful when the source material changes often, such as product docs, policy manuals, incident reports, or internal wiki pages.
“Retrieval-augmented generation is one of the most practical ways to make large language models useful for enterprise data,” said Joshua Noble in IBM’s OpenRAG article.
That quote gets to the heart of the product. OpenRAG is not trying to replace foundation models. It is trying to make them answer from the right material, in the right context, with enough structure that teams can trust the output more than a raw chat response.
There is also a governance angle that matters a lot in regulated environments. If a company can keep documents, embeddings, and retrieval inside its own infrastructure, it can make a stronger case for data residency and access control than it could with a plain consumer chatbot.
OpenRAG is also a response to the way enterprise AI buying has shifted. Teams are less interested in demos that look clever and more interested in systems that can be audited, updated, and connected to existing infrastructure. A RAG stack is often the shortest path from proof of concept to something people can actually use.
How OpenRAG can be deployed
IBM describes several deployment patterns, and they all reflect the same idea: retrieval, orchestration, and inference do not have to live in the same place. That separation is useful because different organizations care about different constraints.
In a fully self-hosted setup, document ingestion, indexing, orchestration, and model inference all stay inside the company network. IBM mentions Kubernetes for hosting the retrieval system, OpenSearch for indexing and hybrid search, and local orchestration with tools such as Langflow. That setup is attractive for teams with strict security or residency requirements.
In a mixed setup, the data and vector index stay self-hosted while the model runs in a managed cloud service. IBM says this can include external providers such as the OpenAI API or Anthropic Claude. The retrieval results are added to the prompt before the request goes out to the model.
- Self-hosted: documents, embeddings, search, and inference stay internal.
- Mixed cloud: retrieval stays internal while inference runs in a managed API.
- IBM stack: data in watsonx.data and models in watsonx.ai with Granite models.
- Distributed cloud: ingestion, indexing, and inference can run across separate providers.
IBM also calls out a stack built around Granite models inside the IBM environment. That is a practical option for companies already using IBM data and governance tools, because it reduces integration work and keeps the control plane closer to existing enterprise systems.
There is a lighter-weight option too. Developers can run a smaller OpenRAG setup on a single machine or a small cluster for experimentation. That matters because a lot of enterprise AI work starts as a prototype, and the prototype needs to be close enough to production architecture that the team does not throw it away later.
One useful way to think about OpenRAG is as an architecture kit, not a fixed product. The value is in the choices it allows: which model to call, where to store vectors, how to process files, and how much of the system should stay inside your network.
Where OpenRAG fits best
The strongest use cases are the ones where wrong answers are expensive. Internal knowledge assistants are an obvious fit. If an employee needs to know how a legacy system works, what a policy says, or where a process lives in the documentation, a grounded assistant is far more useful than a generic chatbot.
Customer support is another obvious fit. Support teams already sit on top of knowledge bases, issue histories, troubleshooting notes, and product docs. OpenRAG can turn those materials into a live answer layer that helps agents respond faster and gives customers more precise guidance.
Compliance and policy analysis also make sense here, especially in industries where document trails matter. A system that retrieves the exact policy language before generating an answer is much easier to defend than one that free-associates its way through a legal question.
- Internal copilots for HR, IT, engineering, and operations.
- Support assistants that summarize tickets and suggest fixes.
- Compliance tools that cite policy language and regulatory text.
- Research systems that compare reports, papers, or patents.
OpenRAG is also useful for research and analytics workflows. A team can index reports, scientific papers, or financial filings, then ask questions in natural language. That gives analysts a faster way to find relevant passages and compare documents without manually searching through thousands of pages.
For data exploration, the interesting part is the mix of structured and unstructured sources. OpenRAG can help a user ask about a metric, then pull context from reports, dashboards, or notes that explain what the number means. That is often where enterprise AI becomes useful in daily work, because the answer is not just a number, it is the reason behind the number.
Compared with a plain chatbot, OpenRAG gives teams four practical advantages: it can keep private data inside the company, it can use fresher documents, it can cite the source material more reliably, and it can mix different model providers without rewriting the whole app.
What to watch next
OpenRAG is interesting because it is less about a single model and more about making enterprise AI operational. IBM is betting that the winning systems will be the ones that can ingest messy documents, retrieve the right context, and keep working as data and models change.
If that bet holds, the next wave of AI projects will look less like chat demos and more like controlled information systems with clear retrieval paths, source citations, and deployment choices that fit real infrastructure. The teams that win will be the ones that treat retrieval quality as seriously as prompt design.
My prediction is simple: in the next year, more internal AI assistants will be judged on whether they can answer from company-specific documents without drifting into generic model fluff. If your team is evaluating RAG platforms now, the first question should be whether the stack fits your data governance rules before you ask whether the demo feels smart.
// Related Articles
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention
- [TOOLS]
Midjourney turns prompt ideas into art