OpenRAG 在企業 AI 的用途
IBM OpenRAG 把檢索、索引和模型協調包成一套。適合用公司內部資料做 RAG,讓回答更貼近文件,也更好追查來源。
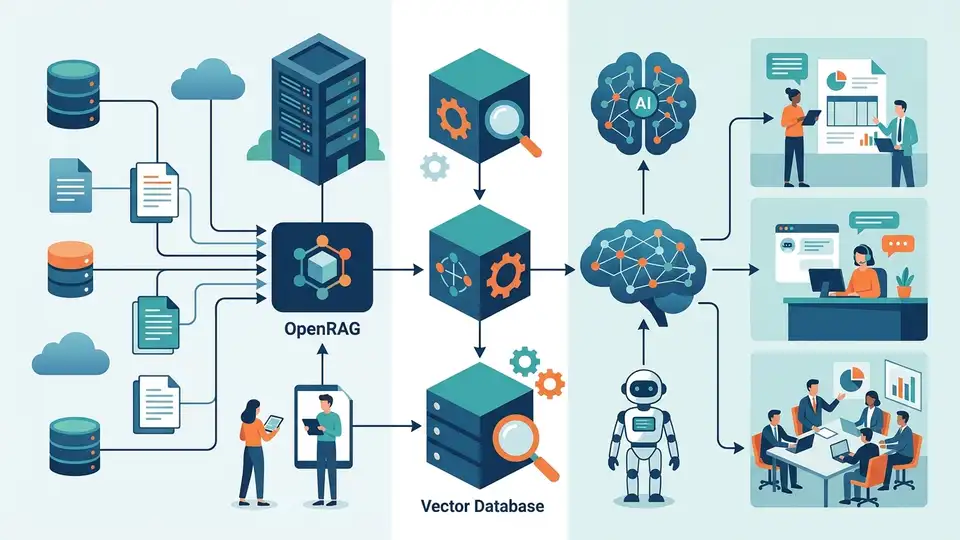
企業在玩 AI,最怕一件事。模型講得很順,卻答非所問。IBM 的 OpenRAG 就是在解這個痛點。它把檢索、索引、文件處理和模型協調包成一套。
講白了,LLM 很會寫。它不會自己知道你公司的內規、產品更新,或昨天才改的 SOP。OpenRAG 讓系統先找資料,再產生答案。這比直接丟問題給模型,實用很多。
IBM 說這套工具建在 Langflow、Docling 和 OpenSearch 上。這三個名字很關鍵。因為企業 AI 真正卡住的,通常不是模型本身,而是前後流程。
OpenRAG 到底在做什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
OpenRAG 是 IBM 的開源 RAG 工具組。它的目標很直白。把模型接到外部資料源,像是文件、資料庫、知識庫。這樣模型回答時,不是靠腦補,而是靠檢索到的內容。
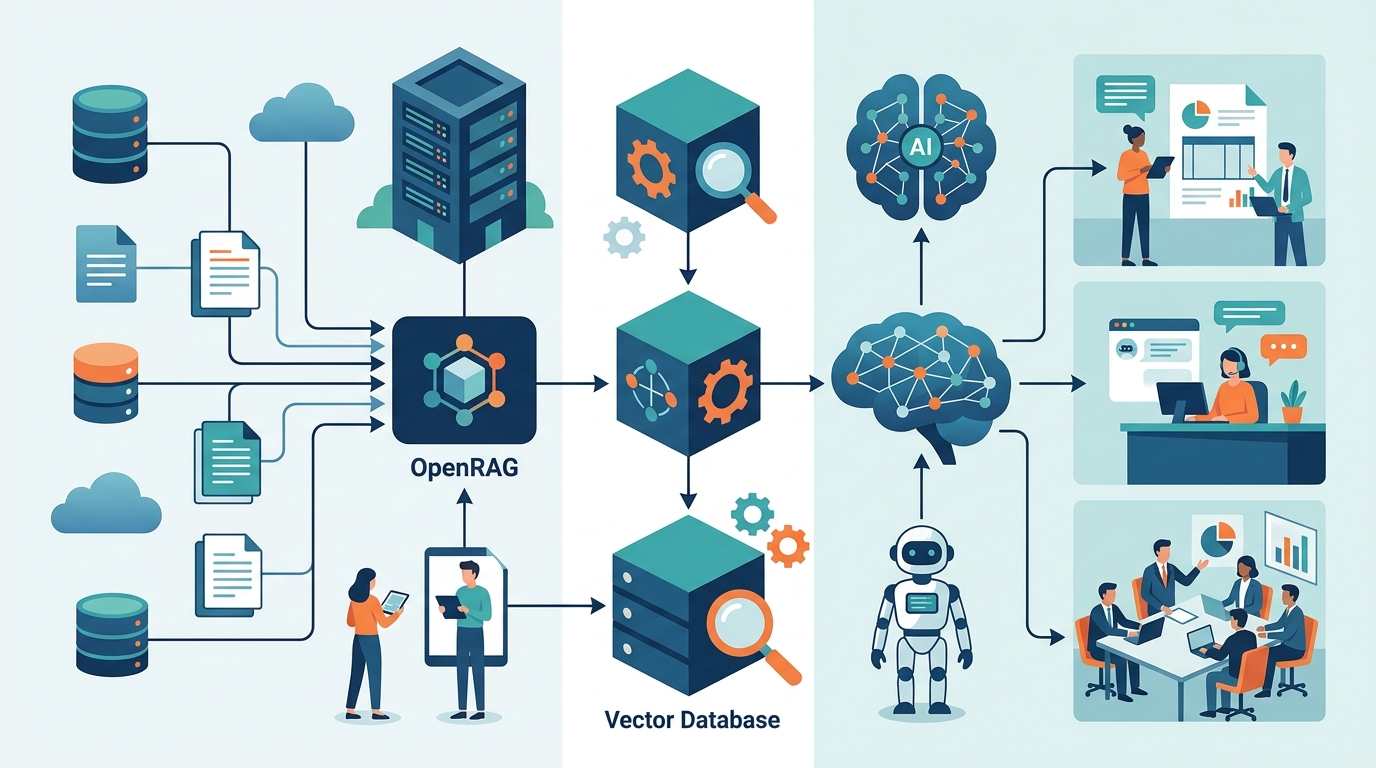
RAG 全名是 Retrieval-Augmented Generation。中文常翻成檢索增強生成。流程也不複雜。使用者提問後,系統先搜尋資料,再挑出相關段落,最後把這些段落塞進 prompt,讓模型生成答案。
但實作起來很煩。你要處理 PDF、切段、嵌入向量、搜尋、重排序、上下文組裝,還有推論服務。OpenRAG 的價值,就是把這些東西拆成可組合的元件。開發者不用每一層都自己寫。
- OpenRAG 是開源工具組。
- 它適合企業內部知識查詢。
- 它支援文件處理與向量檢索。
- 它可接自架模型或雲端 API。
這種模組化設計很務實。因為企業環境很少是單一雲、單一模型、單一資料庫。你可能今天用 OpenSearch,明天又想接 IBM watsonx.data。OpenRAG 讓這些選項能共存。
我覺得這才是它真正的賣點。不是「AI 很強」。而是「你可以把資料管好,再讓 AI 去答」。這種順序很重要。先管資料,再談模型,通常比較不會翻車。
為什麼 RAG 還是主流解法
很多人以為 RAG 是過渡方案。其實不是。只要企業資料還在內網、文件還在變、政策還在改,RAG 就很有用。因為模型本身不會自動知道你的最新資料。
LLM 最大的問題之一,就是會講得像真的。它語氣很穩,但內容不一定對。當問題牽涉到內部文件、法規、產品規格,直接生成答案風險很高。先檢索,再回答,會安全很多。
IBM 的文章也點出這件事。OpenRAG 的重點,是把答案綁回來源資料。這對稽核很重要。你不只知道它答了什麼,還能追到它根據哪份文件。
“Retrieval-augmented generation is one of the most practical ways to make large language models useful for enterprise data,” said Joshua Noble.
這句話很實在。企業不是在買會聊天的玩具。企業要的是可追溯、可更新、可控管的系統。RAG 正好把這幾件事串起來。
還有一個常被忽略的點。RAG 也影響資料治理。當文件、向量索引、權限控管都在公司內部時,資料外洩風險會比較好管。這對金融、製造、醫療這類場景特別重要。
說真的,很多 AI 專案死掉,不是因為模型不夠強。是因為資料沒整理好,最後只能做 demo。RAG 至少讓這條路比較像正經工程。
OpenRAG 跟其他方案怎麼比
OpenRAG 的設計思路,跟「自己拼一套 RAG」很像,但少了很多重工。你還是可以自己接 OpenAI API 或 Anthropic Claude。差別在於,OpenRAG 把流程框架先整理好了。
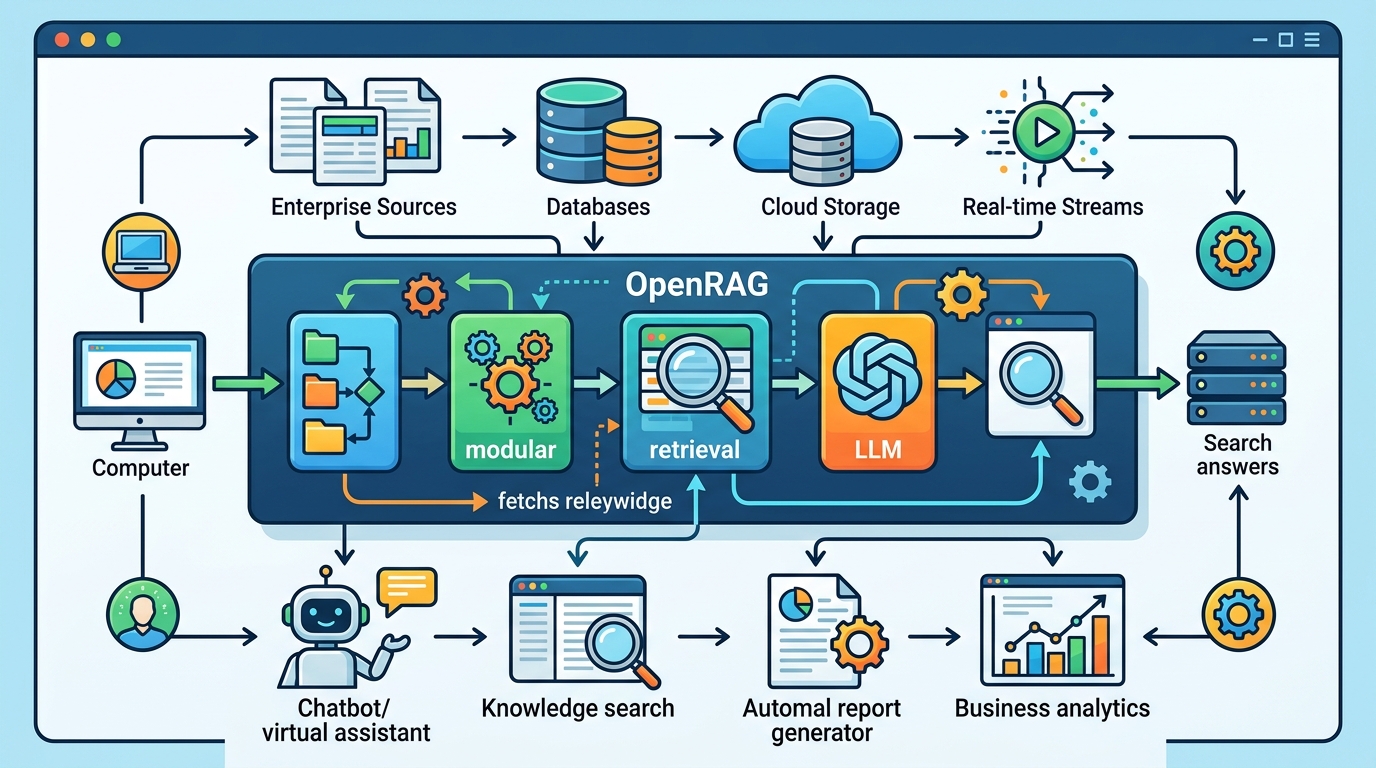
如果跟純手刻相比,OpenRAG 省掉不少整合成本。你不用每次都自己處理文件解析、索引更新、搜尋策略、提示詞拼接。這些東西看起來瑣碎,但一進 production 就很花時間。
如果跟封閉式平台比,OpenRAG 的好處是彈性。你可以自己選模型、自己選儲存、自己選部署方式。這對有合規需求的團隊很重要。因為不是每個資料都能丟到外部 SaaS。
- 手刻 RAG:自由高,但維護成本高。
- 封閉平台:上手快,但彈性低。
- OpenRAG:中間路線,適合既要控管又要彈性。
- watsonx.ai:適合已在 IBM 生態系的團隊。
如果看部署方式,OpenRAG 也很靈活。可以全自架,也可以混合雲。資料和索引留在內部,推論丟給雲端 API。這種架構對很多企業來說,剛好卡在可接受範圍內。
我會把它看成架構工具,不是單一產品。它比較像一組積木。你要哪顆模型、哪個向量庫、哪種文件流程,都可以換。這對工程團隊很友善。
OpenRAG 適合哪些場景
最適合的場景,是答案錯了會出事的地方。像內部知識助理、客服助手、合規查詢,這些都很吃資料正確性。OpenRAG 能讓回答綁到公司文件,不會亂飄。
例如 HR 或 IT 問答。員工常常只想知道流程在哪。這種問題不需要創意,只需要準。RAG 系統如果能直接抓出內規和操作手冊,效率會好很多。
客服也一樣。客服中心本來就有知識庫、工單紀錄、故障排除文件。把這些資料接進 OpenRAG,客服人員就能更快找到答案。這比叫一個聊天機器人硬猜,實際太多了。
- 內部知識助理。
- 客服與工單摘要。
- 法遵與政策查詢。
- 研究與文件比對。
研究場景也很有意思。像報告、論文、專利、財報,這些文件量都很大。把它們索引起來,使用者就能用自然語言問問題。這對分析師很省時間。
如果再往下看,OpenRAG 也很適合混合資料。像數字在資料庫裡,解釋在報告裡。模型可以先找數字,再補上下文。這種「數字加原因」的查詢,才是企業每天真的會用到的。
比起一般聊天機器人,OpenRAG 有幾個明顯優勢。它能保留私有資料。它能用更新的文件。它能把來源拉回來。它也比較容易換模型,不用整個重寫。
產業脈絡與實作現況
現在企業 AI 的重點,已經不是「能不能聊天」。而是「能不能接進流程」。很多團隊做完 demo 就卡住,因為資料來源太亂,版本太多,權限也太複雜。
這也是為什麼 RAG 持續有市場。它不是最炫的做法,但它很接地氣。只要公司還有文件系統,還有內部知識庫,RAG 就有存在價值。OpenRAG 只是把這件事做得更系統化。
另一個背景是模型供應商越來越多。今天可能用 GPT,明天可能改 Claude,後天又想試自架 LLM。企業不想被綁死。OpenRAG 的模組化,剛好符合這種需求。
從工程角度看,這也意味著團隊開始重視評估指標。不是只看回答像不像人話。還要看檢索命中率、引用準確率、延遲、成本,還有文件更新後多久能同步。這些才是上線後的真問題。
如果你在做 PoC,我會建議先看三件事。資料能不能整理。權限能不能切。回覆能不能追溯。這三個過了,才談模型效果。順序錯了,後面很容易重工。
你該怎麼看 OpenRAG
OpenRAG 不是在賣神奇 AI。它是在處理企業最現實的問題。資料很多、文件很亂、模型很會講,但答案要能對得上來源。這件事做不好,再強的 LLM 都只是聊天。
我會給它一個很直接的判斷。只要你的場景有內部資料,而且答案要可追查,OpenRAG 就值得看。尤其是客服、法遵、內部知識庫、工程文件這幾類。
接下來一年,我猜企業會更在意「檢索品質」而不是單純換更大的模型。因為模型再大,沒有好資料還是會亂講。你如果正在評估 RAG 平台,先問自己一件事:你的資料流程,真的準備好了嗎?