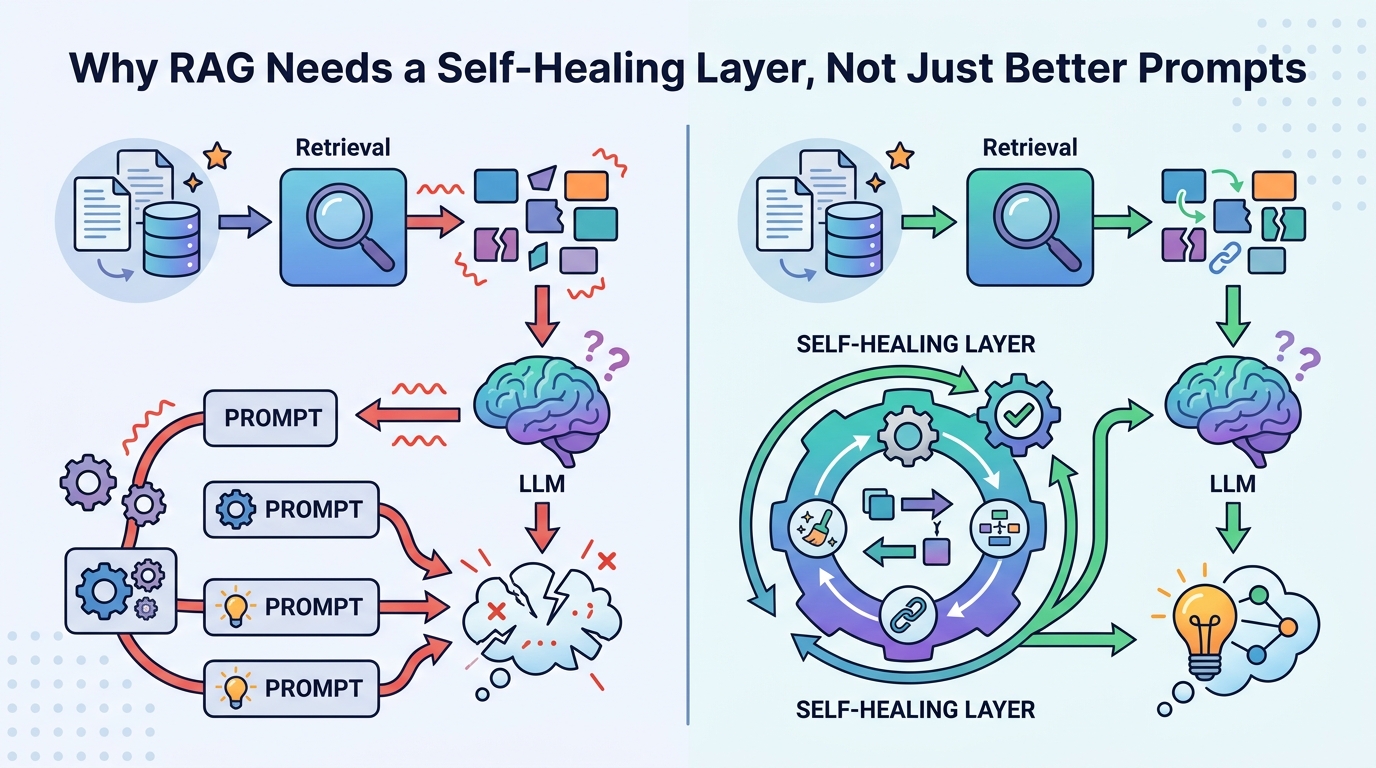
Why RAG Needs a Self-Healing Layer, Not Just Better Prompts
RAG should be treated as a failure-prone system that needs real-time self-healing, not prompt tuning.
RAG systems need a real-time self-healing layer because grounded retrieval still produces wrong answers.
I am firmly on the side of adding a self-healing layer to RAG, not pretending prompt engineering is enough. The evidence is plain: a retrieval step can fetch the right source and the model can still contradict it with a fluent answer, which means the dangerous failure is not missing context but misusing context. In the system described here, that gap is handled with detection, scoring, and repair before the answer reaches the user, and the author reports 70 tests covering the failure modes that kept recurring in production-like runs.
First, retrieval is not the same as grounding
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most teams still talk about RAG as if retrieving the right document solves the problem. It does not. A model can see the correct chunk, then answer with a different number, a different policy, or a different conclusion. That is why this failure is worse than a plain hallucination: the system appears authoritative because the source was present, which makes the wrong answer more believable, not less.
The article’s core example is simple and damning: the retriever found the correct document, yet the LLM contradicted it. That is not a rare glitch that disappears with a cleaner prompt. It is a structural weakness of the generation step. If your production system stops at retrieval and generation, you are shipping an answer engine with no final integrity check.
Second, the right fix is inspection at the answer boundary
The strongest part of this approach is its placement. The system inspects the final answer after generation and before release, which is exactly where the risk lives. The reported pipeline runs as retrieve(query) → generate(query, chunks) → detector.inspect(...) → QualityScore.compute(...) → healer.heal(...) → accept or fall back. That sequence matters because the user only ever sees the final string, not the internal promise of grounding.
There is also a practical engineering win here: the author kept the check inside a normal FastAPI request, with no external APIs, no embeddings model, and no LLM judge. The claimed latency is under 50ms with spaCy and under 10ms on a regex fallback. That is the kind of constraint that makes a safety layer deployable instead of decorative. If a safeguard adds seconds, teams skip it. If it adds milliseconds, teams can keep it on.
Third, simple detectors beat vague confidence in production
The system’s detector does not try to be clever in the academic sense. It looks for concrete failure patterns: numeric contradictions, fake citations, negation flips, answer drift, and confident-but-ungrounded responses. That is the right move. Production failures are usually boring in their shape even when they are expensive in their impact, so the defense should be equally direct.
One example is the confidence scorer, which uses linguistic overconfidence markers like “definitely” and “guaranteed” versus uncertainty markers like “might” or “I think.” That is a poor man’s logprob, but it is enough to catch a model bluffing with authority. Another example is the faithfulness scorer, which checks whether claim keywords appear in the retrieved context. This is not a philosophical metric. It is a practical gate that asks a blunt question: does the answer have traceable support, yes or no?
The counter-argument
The best objection is that self-healing layers add complexity, and complexity can create its own failure modes. A poorly tuned detector can over-flag valid paraphrases, route too many answers to fallback, or mask deeper retrieval problems. There is also a legitimate worry that a system like this encourages teams to accept mediocre generation quality instead of fixing the underlying model behavior.
That objection is real, but it does not defeat the case for the layer. It only sets the bar for implementation. The article already acknowledges this by using named assertions for each failure mode, by separating detection from repair, and by tuning thresholds such as a 40% keyword overlap for faithfulness. In other words, the answer is not “trust the detector blindly.” The answer is “treat the detector like production infrastructure, test it hard, and let it fail closed when the answer is ungrounded.”
What to do with this
If you are an engineer, add a final-answer gate before any RAG response leaves your service, and make it check for contradictions, unsupported entities, and overconfident language. If you are a PM, budget for safety latency the same way you budget for search latency, because a fast wrong answer is still a wrong answer. If you are a founder, stop selling RAG as if retrieval alone creates trust; trust comes from retrieval plus verification plus a repair path when the model goes off the rails.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10