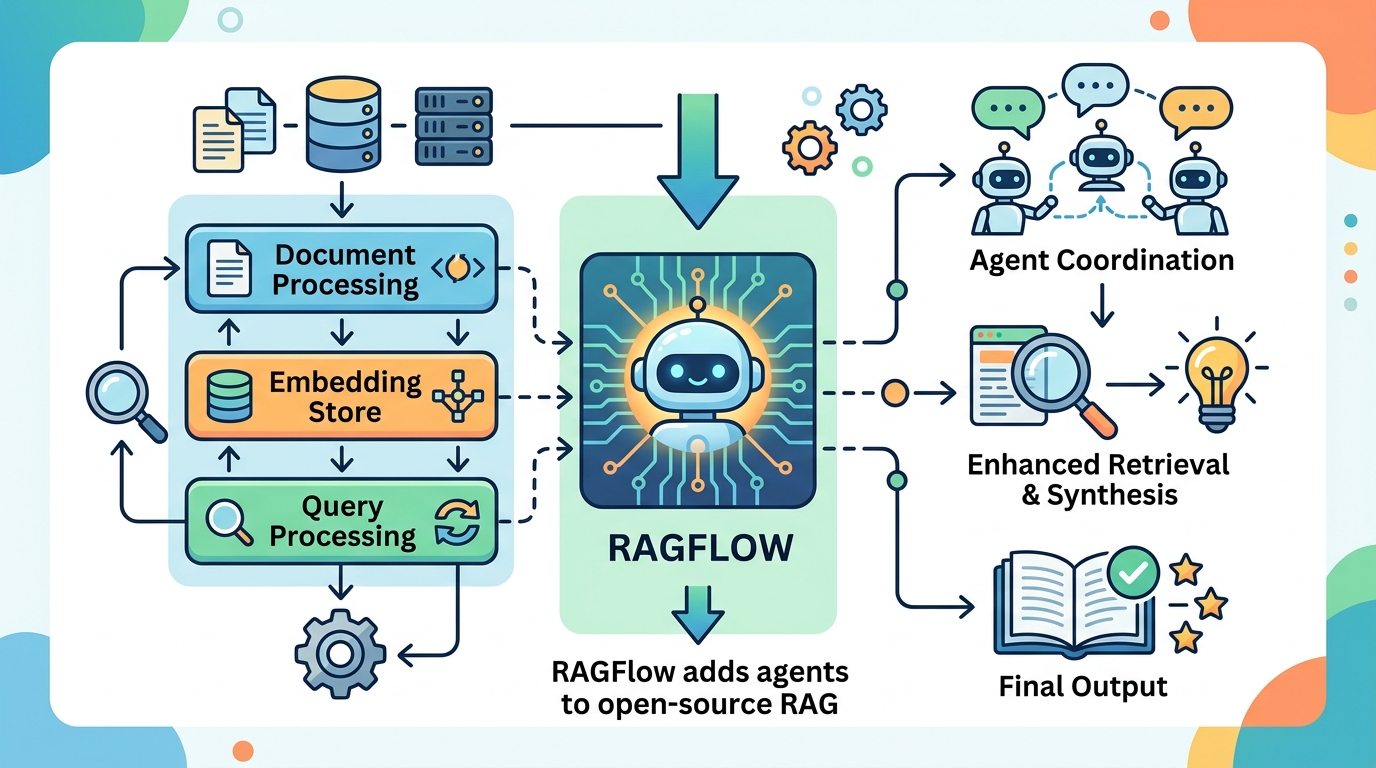
RAGFlow adds agents to open-source RAG
RAGFlow pairs retrieval-augmented generation with agent features, Docker self-hosting, and support for newer models like GPT-5 and Gemini 3 Pro.
RAGFlow is an open-source RAG engine that adds agent features and self-hosting.
RAGFlow is one of those projects that gets more interesting the more data you throw at it. The repository now shows 80.3k stars, 9.1k forks, and 6,155 commits, which tells you this is not a side project tucked away in a corner.
The pitch is simple: take retrieval-augmented generation, add agent capabilities, and make the whole thing usable for real document-heavy workflows. The repo also points people to RAGFlow Cloud for a hosted option, while the open-source path stays centered on Docker, local setup, and a stack that can be tuned for different deployment sizes.
| Fact | Value | Why it matters |
|---|---|---|
| GitHub stars | 80.3k | Shows strong developer adoption |
| GitHub forks | 9.1k | Signals active reuse and experimentation |
| Commits | 6,155 | Points to steady product churn |
| Minimum CPU | 4 cores | Basic self-hosting floor |
| Minimum RAM | 16 GB | Needed for practical local deployment |
| Minimum disk | 50 GB | Storage budget for the full stack |
What RAGFlow is trying to solve
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most RAG systems break down when the source material stops looking like clean Markdown. RAGFlow is built for the messier reality: PDFs with tables, scanned files, slide decks, spreadsheets, web pages, and mixed document stores that need grounding before a model can answer anything useful.
The project describes itself as a “converged context engine” with pre-built agent templates. In plain English, that means it tries to do more than simple chunk-and-embed retrieval. It wants to understand documents deeply, extract structure, and keep citations tied to the answer so humans can check the source.
That matters because the failure mode in enterprise AI is usually not model quality alone. It is context quality. If the input layer is sloppy, the output layer looks confident while being wrong.
- Deep document understanding for unstructured and mixed-format data
- Template-based chunking with visible, inspectable citation paths
- Support for Word, slides, Excel, text, images, scanned copies, structured data, and web pages
- Multiple recall paths with fused re-ranking for better answer selection
What changed in recent updates
The update log is unusually dense, and that is useful because it shows where the project is heading. Recent entries mention support for DeepSeek v4, GPT-5, and Gemini 3 Pro, along with agent memory, MCP, and data sync from Confluence, S3, Notion, Discord, and Google Drive.
"The most important thing about AI is that we need to understand that it is not magic." — Sundar Pichai
That quote fits RAGFlow well. The project is not selling magic. It is trying to make the plumbing better, which is usually where enterprise AI either wins or fails. The newer features point to a system that is moving from document retrieval toward agentic workflows that can act on that context.
Here are the recent updates that matter most if you are evaluating it for a team:
- 2026-04-24: DeepSeek v4 support
- 2026-03-24: RAGFlow Skill on OpenClaw for dataset access
- 2025-12-26: agent memory support
- 2025-11-19: Gemini 3 Pro support
- 2025-11-12: sync from Confluence, S3, Notion, Discord, and Google Drive
- 2025-10-23: MinerU and Docling parsing methods
- 2025-10-15: orchestrable ingestion pipeline
- 2025-08-08: GPT-5 series support
How the self-hosted setup compares
RAGFlow is opinionated about deployment. The documentation asks for 4 CPU cores, 16 GB RAM, and 50 GB disk as a baseline, plus Docker 24.0.0 and Docker Compose v2.26.1. If you want code execution in its sandboxed agent flow, you also need gVisor.
That is a real-world setup, not a toy demo. The repo also warns that the published Docker images are built for x86, so ARM64 users need to build their own image. For teams running Macs with Apple Silicon or ARM servers, that detail is easy to miss and painful to discover late.
The storage engine choice is another practical signal. RAGFlow uses Elasticsearch by default for full text and vectors, but it also supports switching to Infinity. That kind of flexibility matters when you are tuning cost, performance, and operational complexity.
If you are comparing RAGFlow with a lighter RAG stack, the trade-off is clear: you get more document intelligence and more control, but you also accept more setup work. The project is aimed at teams that care about citations, multi-source ingestion, and production deployment rather than a quick weekend prototype.
For readers who want related context, OraCore has also covered Claude Code and MCP registry workflows.
Why this matters for builders
RAGFlow is interesting because it sits between a document pipeline and an application framework. The project is trying to reduce the gap between raw enterprise content and answers that can be trusted, cited, and acted on by agents.
That positioning is timely. Teams are past the stage where they want a chatbot that can answer one-off questions from a PDF. They want systems that can ingest multiple sources, preserve traceability, and support workflows that mix retrieval, tool use, and memory.
If RAGFlow keeps shipping at the current pace, the next question is not whether it can ingest more formats. It is whether teams will standardize on it as the context layer for internal AI products, or keep using it as a specialized tool for document-heavy workloads.
For now, the clearest takeaway is practical: if your AI app depends on messy source data, RAGFlow is worth a serious look, especially if you need self-hosting and citation-aware retrieval. If your stack is already clean and simple, the extra machinery may be more than you need.
What matters next is whether the project can keep balancing breadth, setup complexity, and reliability as agent features keep expanding.
// Related Articles
- [TOOLS]
Why VidHub 会员互通不是“买一次全设备通用”
- [TOOLS]
Why Bun’s Zig-to-Rust experiment is the right move
- [TOOLS]
Why OpenAI API pricing is a product strategy, not a footnote
- [TOOLS]
Why Claude Code’s prompt design beats IDE copilots
- [TOOLS]
Why Databricks Model Serving is the right default for production infe…
- [TOOLS]
Why IBM’s Bob is the right kind of AI coding assistant