How to Add Temporal RAG in Production
Add a temporal reranking layer to RAG so fresh, valid, and versioned facts rank correctly.

Add a temporal reranking layer to RAG so fresh, valid, and versioned facts rank correctly.
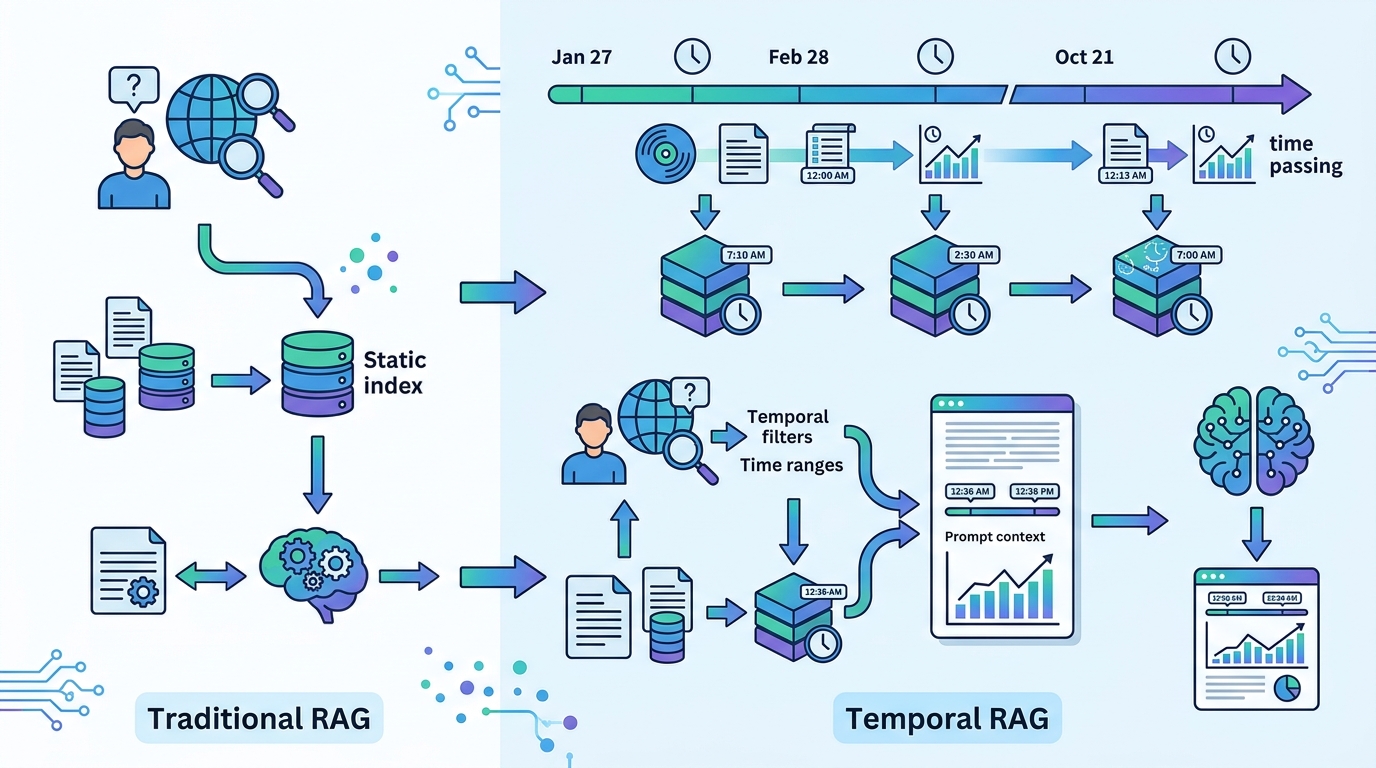
This guide is for developers building RAG systems over content that changes over time, such as docs, policies, tutorials, alerts, and support knowledge bases. After following it, you will have a production-friendly temporal layer that filters expired facts, boosts active time-bound events, and prefers newer versions without rebuilding your retriever.
You will also have a clear scoring path between vector search and the LLM, plus a way to verify that stale documents no longer outrank current ones.
Before you start
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
- Python 3.11+
- Node.js 20+ only if your app shell or API layer is in Node
- A working RAG stack with a vector database such as Pinecone, Weaviate, pgvector, or FAISS
- Document metadata fields for
created_at,updated_at, and optionallyexpires_at - An LLM API key, such as OpenAI or Anthropic
- Access to the reference implementation on GitHub and the original write-up on Towards Data Science
Step 1: Map your time-sensitive documents
Your first outcome is a document inventory that separates timeless facts from replaced versions and active events. This matters because the temporal layer only works if it knows whether a document is static, versioned, or an event with a time window.
Start by tagging each source record with a kind and a validity signal. A practical schema looks like this:
kind: STATIC | VERSIONED | EVENT
valid_from: ISO-8601 timestamp
valid_to: ISO-8601 timestamp or null
expires_at: ISO-8601 timestamp or null
supersedes_id: optional document idVerification: you should be able to point to any document and say whether it is timeless, replaced by a newer version, or only true during a live window.
Step 2: Add freshness metadata to your index
Your second outcome is an index that stores the timestamps needed for reranking. The vector store can still do semantic retrieval, but it must return metadata alongside embeddings so the temporal layer can make a decision.
When you ingest or update content, write the metadata into the same record you embed. If you already have a pipeline, add these fields without changing the embedding model.
doc = {
"id": "policy_v2",
"text": "API rate limits are now 200 requests per minute",
"kind": "VERSIONED",
"created_at": "2026-01-10T09:00:00Z",
"updated_at": "2026-03-01T12:00:00Z",
"valid_from": "2026-03-01T12:00:00Z",
"valid_to": null,
"supersedes_id": "policy_v1"
}Verification: you should see the metadata returned with each retrieved chunk, not just the text and similarity score.
Step 3: Classify validity before ranking
Your third outcome is a pre-ranker that removes expired facts and marks active time-bound facts before the LLM ever sees them. This is the key safety step, because expired content should not be down-weighted, it should be dropped.
Use three states: EXPIRED, VALID, and TEMPORAL. In the pattern from the source article, only EVENT documents can become TEMPORAL. VERSIONED documents remain VALID until they are superseded, and then the old copy is excluded.
def classify(doc, now):
if doc.get("expires_at") and doc["expires_at"] < now:
return "EXPIRED"
if doc["kind"] == "EVENT" and doc.get("valid_from") <= now <= doc.get("valid_to"):
return "TEMPORAL"
return "VALID"Verification: you should see expired items removed from the candidate set and active alerts marked TEMPORAL rather than merely ranked lower.
Step 4: Rerank candidates with temporal decay
Your fourth outcome is a reranker that combines semantic similarity with freshness. The goal is not to let time override relevance, but to make recency matter when several documents are otherwise close matches.
A practical scoring model is to normalize cosine similarity, apply exponential decay by age, and add a boost for active events. The source article uses a hybrid score so the newest relevant document wins without forcing every fresh document to the top.
decay = 0.5 ** (age_in_days / half_life_days)
final_score = (0.7 * vector_score) + (0.3 * decay)
if state == "TEMPORAL":
final_score *= 1.2
if state == "EXPIRED":
final_score = 0.0Verification: you should see a newer policy outrank an older policy with similar wording, while a live outage notice jumps above static docs during its active window.
Step 5: Wire the temporal layer between retriever and LLM
Your fifth outcome is a production path where the retriever stays unchanged and the temporal layer only rewrites the candidate order. That keeps the implementation low-risk and easy to slot into an existing system.
Take the top-k semantic matches, classify them, rerank them, then pass only the final context to the LLM. This preserves your current retriever while fixing the time blindness at the last responsible moment.
candidates = retriever.search(query, top_k=20)
scored = [score_candidate(c, now) for c in candidates]
ranked = sorted(scored, key=lambda x: x.final_score, reverse=True)
context = [item.doc for item in ranked if item.state != "EXPIRED"]
answer = llm.generate(query, context)Verification: you should see the prompt context contain the newest valid version, not the oldest semantically similar chunk.
Step 6: Test stale-answer failures
Your sixth outcome is a repeatable test suite that proves the layer works on the cases that matter most. The right tests are not generic retrieval tests, but time-aware failures such as a replaced policy, an expired tutorial, and a live event that should outrank everything else.
Build fixtures for at least three scenarios: a superseded document, an expired document, and a currently active event. Then assert both ranking order and exclusion behavior.
assert "policy_v1" not in final_context
assert final_rank[0].id == "announcement_today"
assert any(item.state == "TEMPORAL" for item in ranked)Verification: you should see the old version removed, the active notice surfaced, and the latest valid document outranking its predecessor.
| Metric | Before/Baseline | After/Result |
|---|---|---|
| Ranking behavior | Old policy ranked first by cosine similarity | Latest valid policy ranked first after temporal rerank |
| Expired content handling | Expired doc remained in top results | Expired doc removed before LLM context |
| Active event handling | Live notice ranked below static docs | Live notice boosted to the top during its window |
Common mistakes
- Using one freshness rule for every document type. Fix: separate STATIC, VERSIONED, and EVENT so each gets the right behavior.
- Down-weighting expired facts instead of removing them. Fix: filter EXPIRED items before reranking or prompt assembly.
- Boosting every recent document as if it were urgent. Fix: reserve TEMPORAL boosts for true event windows, not for normal version updates.
What's next
Once this is working, extend it with source-specific half-lives, audit logs for ranking decisions, and user-facing explanations that say why one document beat another. From there, you can add live refresh hooks, policy-specific expiry rules, and evaluation sets that measure stale-answer reduction over time.
// Related Articles
- [AGENT]
Perplexity should build Teammate as a coding agent, not a copilot
- [AGENT]
HP adopts OpenAI Frontier across global operations
- [AGENT]
Build a production vector DB for RAG
- [AGENT]
Ornith-1 turns agent coding into a server
- [AGENT]
Crypto AI agents are useful, but only for narrow workflows
- [AGENT]
AI Agents in Crypto: 2026 Protocol Guide