Harness Engineering: From Bridle to Operating System, The Missing Link in AI Agent Reliability
Harness Engineering is the discipline of designing external control frameworks for AI Agents. By integrating context engineering, architectural constraints, and garbage collection, it transforms unreliable large models into dependable production systems.

The Problem: Why GPT-5 Still Fails at Simple Tasks
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
You've probably noticed something strange: the most powerful AI models sometimes fail spectacularly at tasks they should ace.
In August 2025, OpenAI's internal team started an ambitious experiment: let a Codex Agent build a production application from scratch, on a blank repository. The constraint was radical: zero lines of manually written code. The result? Over 1 million lines of code in five months with a team of seven engineers—averaging 3.5 merged pull requests per engineer per day. Productivity increased as the team grew (opposite of what usually happens).
But this success wasn't built on a smarter model. It was built on something invisible: the infrastructure surrounding the Agent.
This is the story of Harness Engineering.
What Is Harness Engineering?
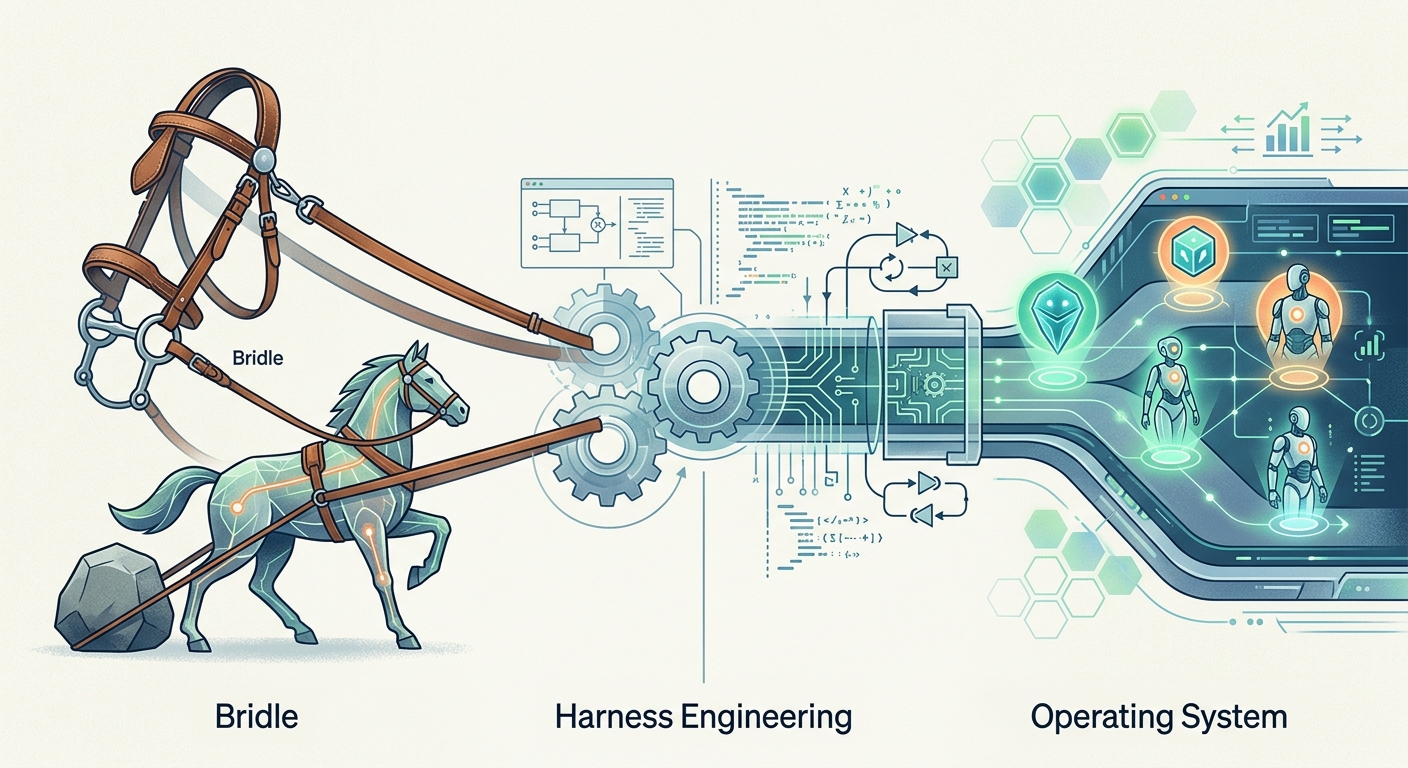
Harness Engineering is the discipline of designing the external control and execution framework for AI Agents. If an AI model is a horse, a Harness is the reins, saddle, and entire system of horsemanship—it determines where the horse goes, what it can touch, and how it recovers from panic.
The Term's Origin
The concept was formally named by Mitchell Hashimoto, co-founder of HashiCorp, in February 2026. In his article "My AI Adoption Journey," Hashimoto crystallized a key insight under the section "Engineer the Harness":
"Every time the agent makes a mistake, don't hope it does better next time. Engineer the environment so it can't make that specific mistake the same way again."
This simple principle ignited a field. Weeks later, OpenAI released detailed research on Harness Engineering. Anthropic built it into Claude Code's architecture. Google DeepMind applied it to AlphaCode 2.
Why "Harness"?
The term comes from horsemanship—a harness is the equipment connecting rider to horse. The metaphor is surprisingly precise:
- Horse = Large Language Model — Raw power, unpredictable behavior
- Rider = Developer or User — Wants to direct and control
- Harness = Harness Engineering — Makes control possible
Without a harness, no cart moves, no matter how strong the horse. Without Harness Engineering, no Agent stays reliable in production, no matter how intelligent.
Three Ages of AI Engineering: From Prompt to Harness
The past three years saw AI engineering evolve through three distinct eras. Understanding this progression is essential to understanding why Harness Engineering dominates 2026.

Age One: Prompt Engineering (2023–2024)
Defining characteristic: Magic incantations
In the early ChatGPT days, developers obsessed over prompting. The logic: write smarter instructions, extract more intelligence from the model.
Classic techniques:
- "Let's think step by step…"
- "You are a senior software engineer…"
- "Output JSON format…"
These worked, but hit a ceiling. For complex, multi-step tasks, Prompt Engineering's limitations surfaced:
- Context Window Curse — Your detailed prompt competes with the actual work for token space
- Magic Numbers — A prompt that works for you fails for someone else
- Zero Learning — Each failure resets; the agent learns nothing
Age Two: Context Engineering (2024–2025)
Defining characteristic: Dynamic knowledge management
In 2024, Hugging Face's Philipp Schmid published "The New Skill in AI is Not Prompting, It's Context Engineering." It changed the game.
Core insight: Most agent failures aren't model failures, they're context failures.
Context Engineering meant:
- Dynamic context assembly — Assemble relevant information on-demand, not static prompts
- Knowledge base optimization — Build searchable documentation, code structure, API references the agent can query
- Tool discovery — Agents don't just know tools exist; they know when and why to use them
By mid-2025, Context Engineering was standard at LangChain, OpenAI, and Anthropic. But teams hit a new bottleneck: Good context wasn't enough.
Agents could know what to do but still lose control in complex workflows. Why?
Age Three: Harness Engineering (2026+)
Defining characteristic: External control infrastructure
Harness Engineering answers: We don't just give the agent more information; we give it a bounded, predictable, recoverable execution environment.
This isn't better prompting. This isn't smarter context. This is rearchitecting the entire system.
The progression:
Prompt Engineering
↓
"Write better magic incantations"
↓
Fails: Limited context window
↓
Context Engineering
↓
"Dynamically assemble more relevant information"
↓
Fails: Agent still loses control in complex workflows
↓
Harness Engineering
↓
"Design the environment so the agent can't fail that way"
The Operating System Metaphor: More Precise Than Bridles
Though the "harness" metaphor is vivid, Schmid's "operating system" analogy captures the essence better.
Four-Layer Compute Stack
| Layer | Traditional Computing | AI Agent System | Role |
|---|---|---|---|
| Application | Word processors, games, browsers | Concrete agent tasks (e.g., "write tests") | End user directly uses |
| Operating System | Windows, Linux, macOS | Harness Engineering | Manages resources, enforces control |
| RAM | 8GB, 16GB physical memory | Context Window | Limited working space |
| CPU | Intel, AMD processors | Large Language Model | Raw computational power |
Why the OS Metaphor Is More Accurate
A modern OS isn't just "make CPU faster." It:
Manages Memory — Runs huge applications in limited RAM
- AI analogy: Handle complex tasks in limited context windows
Schedules Processes — Decides which task runs when
- AI analogy: Decompose work into sub-tasks, sequence execution
Provides Drivers — Standardizes software-hardware interaction
- AI analogy: Standardizes agent-to-tool, agent-to-API communication
Enforces Permissions — Prevents apps from causing damage
- AI analogy: Restrict agent actions to safe operating bounds
Recovers from Crashes — Returns to consistent state on failure
- AI analogy: Detect when agent loops or makes bad decisions, recover
The harness metaphor tells you "control." The OS metaphor tells you "control, manage, optimize, recover"—the complete picture.
Three Cornerstone Implementations
Theory matters, but how does Harness Engineering work in practice? Three case studies show different approaches.
OpenAI: Seven Engineers × One Million Lines of Code
Timeline: August 2025 – January 2026
Goal: Build a production application using only Codex Agents on a blank repository
Outcome:
- Over 1 million lines of code
- 1,500+ pull requests merged
- 7 engineers (scaled from 3)
- 3.5 PR/engineer/day average throughput
- Throughput increased as team grew (unusual)
- One-tenth the time compared to manual coding
The radical constraint: zero manually written code.
OpenAI's Four-Pillar Harness
Based on OpenAI's published report, their harness consists of:
1. Context Engineering: Continuously Enhanced Knowledge Base
OpenAI built a "continuously enhanced knowledge base in the codebase, plus agent access to dynamic context like observability data and browser navigation."
Not static documentation. Rather:
- Architecture documentation — When new modules are created, the Harness enforces documentation updates
- Searchable tool index — Tools with usage examples, not just names
- Observability integration — Agents query logs from previous agent runs, learning from failures
2. Architectural Constraints: LLM + Deterministic Dual Verification
The most innovative part: OpenAI uses both LLMs and traditional linters.
- LLM layer — Agent reviews its own code for logical correctness
- Deterministic layer — Custom linters and structural tests enforce style, module boundaries, naming conventions
Why dual? Because LLMs sometimes miss things. Deterministic checks don't.
3. Garbage Collection: The Entropy War
Even with good Harness, agent-generated code accumulates debt:
- Dead code
- Unnecessary files
- Stale comments
- Architectural violations
OpenAI's solution: Run cleanup agents periodically, whose sole job is finding inconsistencies and fixing them. This is garbage collection.
4. Feedback Loop: Failure → Signal → Improvement
OpenAI's most important philosophy:
"When the agent struggles, we treat it as a signal: identify what is missing—tools, guardrails, documentation—and feed it back into the repository."
Not "hope the agent does better." But "identify system defects and repair the system."
Anthropic: Generator-Evaluator Separation Architecture
Approach: Multi-agent collaboration, not single superhuman agent
Anthropic's Harness in Claude Code uses a different pattern: specialized agent teams.
Three-Tier Architecture
Orchestrator Agent (Leadership tier)
- Runs the smartest model (Claude Opus 4.5)
- Analyzes user request
- Decomposes into sub-tasks
- Coordinates execution order
Specialist Sub-agents (Execution tier)
- Run faster, cheaper models (Claude Sonnet 4, Haiku 4.5)
- Execute tasks in parallel
- Example: one agent writes code, another writes tests, another writes documentation
Verification Agent (Validation tier)
- Reviews all outputs
- Checks code correctness, documentation completeness, test coverage
- Elevates quality before returning to user
Why Separation Works
Performance Improvement: Internal evaluations show this architecture outperforms a single Claude Opus 4 by 90.2%.
Why:
- Parallelism — Multiple agents work simultaneously without blocking each other
- Specialization — Each agent optimizes for specific tasks vs. being a generalist
- Recoverability — One sub-agent's failure doesn't cascade; Orchestrator reroutes
Claude Code is the public implementation of this Harness. When you code in Claude Code, you're not interacting with one agent—you're orchestrating a team.
Google DeepMind: Iterative Verification Loop (AlphaCode 2)
Google DeepMind emphasizes iterative refinement, not single-pass generation.
While Google hasn't published a detailed "Generator-Verifier-Reviser" paper, their AlphaCode 2 practice embodies Harness Engineering's core:
Three-Stage Loop
- Generator — Generate multiple code candidates (typically >100)
- Verifier — Test candidates on test cases, eliminate failures
- Reviser — Refine verified candidates
Not linear "write once, submit." Rather cyclical: Generator sees Verifier feedback and regenerates better candidates.
CodeContests Performance
Using AlphaCode 2, Google DeepMind ranked in the top 15% of human programmers on CodeContests. This exceeded GPT-4 and Claude Opus single-generation performance.
Where's the difference? The Harness—the verification and revision system surrounding the generator.
The Counterintuitive Lesson: Why Vercel Deleted 80% of Tools
In February 2026, Vercel published a confusing article: "We Removed 80% of Our Agent's Tools." Result? Performance improved.
The Setup
Vercel built a text-to-SQL Agent for Vercel Data Platform. The initial version had many carefully designed tools:
- SQL query executor
- Database schema checker
- Table statistics tool
- Custom Vercel API wrappers
- Error handling utilities
- Plus many more
Initial performance: 80% success rate. But the process hurt:
- Average 100 steps to complete a query
- 145,000 tokens (expensive)
- 724 seconds worst-case latency
The Bold Move
Vercel did the counterintuitive: Delete all custom tools. Keep one: execute arbitrary bash.
New Harness:
- Give Claude file system access
- Give Claude standard Unix tools:
cat,grep,ls - Trust Claude to figure out navigation
Shocking Results
New version:
- 100% success rate (vs. 80%)
- 19 steps (vs. 100)
- 67,000 tokens (vs. 145,000—40% savings)
- 141 seconds (vs. 724—5x faster)
Why Fewer Tools = Better Performance?
Vercel's hypothesis: Models got smarter, context windows grew larger, so maybe the best agent architecture is almost no architecture.
Deeper reasons:
Cognitive Overload — Too many tools confuse the agent. It spends time deciding which tool to use instead of solving the problem.
Trust and Freedom — Given basic but powerful primitives, agents perform better.
Universality Beats Specialization — Custom tools can miss edge cases. Universal tools are more robust.
This reveals a deep truth about Harness Engineering: The best harness isn't restrictive, it's enabling.
LangChain's Evidence: Harness-Only Improvement from Rank 30 to 5
LangChain's case is the clearest proof of Harness Engineering's power.
Baseline
LangChain's deep Agent on Terminal Bench 2.0 ranked #30 with a score of 52.8%.
Terminal Bench is a code generation benchmark testing agents in real software development scenarios. Rank 30 means 29 systems beat it.
Experimental Design
LangChain's critical decision: Keep the model fixed, change only the Harness.
Model used: GPT-5.2-Codex (fixed throughout)
Variables changed:
- System prompt
- Tool set and tool design
- Middleware hooks and control flow
Key Findings
1. Verification Loop is a Game-Changer
Problem: Agent writes code, re-reads it, thinks "looks good," stops. No actual testing.
Solution: PreCompletionChecklistMiddleware forces verification pass before exit.
Impact: This single hook contributed 13.7 percentage points improvement.
2. Context Injection Beats Lecture
Problem: Agent drowned in documentation, missed critical details.
Solution: LocalContextMiddleware scans local structure upfront, proactively injects relevant information (file tree, key file contents, test commands).
Impact: Context injection alone contributed 7.2 percentage points improvement.
3. The Counterintuitive Compute Budget Discovery
Finding: Setting reasoning budget to maximum (xhigh) actually decreased performance.
xhigh: 53.9% (due to timeouts)high: 63.6% (optimal)
Lesson: More thinking time isn't always better. Agents can suffer analysis paralysis or timeout. Sometimes constraints improve performance.
Final Results
After these changes, LangChain's Agent:
- Ranked #5 (up from #30)
- Score 66.5% (from 52.8%)
- Model unchanged, only Harness improved
This is the strongest evidence for Harness Engineering's power: the problem isn't the model, it's how you use it.
Martin Fowler's Three-Component Framework
Let's examine Harness structure through a more formal lens. The framework articulated by Martin Fowler and Birgitta Böckeler has become the industry standard.
1. Context Engineering
Definition: Continuously enhanced knowledge base + agent access to dynamic data
Context Engineering isn't writing longer prompts. It's:
Core Elements
| Element | Description | Examples |
|---|---|---|
| Static Knowledge Base | Code structure, API docs, architecture decisions | README.md, API index |
| Dynamic Context | Real-time data, varies by task | Current file tree, relevant code snippets |
| Tool Discovery | Agent knows what tools exist and why | Curated tool list with usage examples |
| Observability Integration | Agent queries logs from previous runs | Error logs, performance data |
Static vs. Dynamic
Static docs go stale. Dynamically generated context balloons. Best practice: hybrid:
- Core architecture and API docs stay static, regularly updated
- Runtime context generated dynamically (file tree, recently edited files)
- Combine both when sending to agent
2. Architectural Constraints
Definition: Enforce code structure and patterns using both LLMs and deterministic tools
This is the Harness's "rule enforcer."
Dual-Layer Verification
Layer One: LLM Verification
- Agent reviews its own code
- Checks logical correctness, naming, structure
Weakness: LLMs sometimes miss things or aren't strict.
Layer Two: Deterministic Checks
- Custom linters
- Structural tests (e.g., all
user_functions must live inuser.ts) - Module boundary checks (e.g.,
data/layer can't import fromui/)
Example
Suppose you enforce Clean Architecture. Harness can mandate:
// Violation ❌ — data layer importing ui layer
import { Button } from '../ui/button'; // Linter rejects
// Correct ✅
import { UserRepository } from './user.repository'; // Linter allows
Not a suggestion. Enforced. Every commit must pass.
3. Garbage Collection
Definition: Regularly run cleanup agents to find and fix inconsistencies
Code entropy is real. Agent-generated code especially accumulates debt:
- Dead code (functions from removed features)
- Stale comments
- Missing unit tests
- Naming violations
- Documentation-implementation drift
How GC Agents Work
- Scan — Periodically scan entire codebase
- Detect — Identify inconsistencies using rules and LLMs
- Report — Generate fix proposals
- Fix — Auto-fix or flag for review
Example
$ npm run gc
Results:
- Found 12 dead code blocks from removed APIs
- Detected 3 stale documentation files
- Identified 5 naming convention violations
- Suggested repairs (auto-apply or review)
Six Core Modules of Harness Engineering
Synthesizing the practices above, a complete Harness Engineering framework includes six core modules.
1. Context Management Engine
Responsibility: Place the most relevant information in the limited context window
Implementation:
- Declarative context rules ("When running Python scripts, include .env template")
- Vector similarity search (find most relevant code snippets)
- Priority queues (critical information first)
Tools: Supabase Vector DB, Pinecone, LangChain's RecursiveCharacterTextSplitter
2. Tool and Capability Layer
Responsibility: Define what agents can do and how to do it
Key Decision: High-level abstractions (run_command) vs. fine-grained tools?
→ Vercel's lesson: High-level abstractions win. Fewer tools, more power.
Typical Tool Set:
- File system access (read, write, delete)
- Code execution (Python, bash)
- Search and browsing (Google, Brave, web)
- External APIs (Stripe, AWS, custom)
3. Control Flow Orchestrator
Responsibility: Decide task execution order and branching
Three Common Patterns:
a) Linear — One step after another
Plan → Code → Test → Deploy
b) Parallel — Multiple agents simultaneously
Code Agent ──┐
Test Agent ─┼→ Verify
Doc Agent ──┘
c) Cyclic — Generate → Verify → Revise → Verify (loop)
Generate → Verify → Revise → Verify (repeat)
4. Verification and Feedback Layer
Responsibility: Check output quality, provide actionable feedback
Verification Types:
| Type | Method | Example |
|---|---|---|
| Syntax | Deterministic (linter) | TypeScript tsc --noEmit |
| Logic | Automated tests | Unit tests, integration tests |
| Style | Rule engine | Prettier, ESLint |
| Semantic | LLM review | "Is this function name meaningful?" |
| Business | Humans or rules | "Does this match product requirements?" |
5. Recovery and Retry Mechanism
Responsibility: Gracefully recover when agents fail
Failure Modes and Strategies:
| Failure | Symptom | Recovery |
|---|---|---|
| Tool Timeout | API unresponsive >30s | Exponential backoff (1s, 2s, 4s) |
| Context Overflow | Exceeds token limit | Dynamic truncation or sub-tasks |
| Infinite Loop | Same step repeated >5 times | Mark failed, rollback to checkpoint |
| Permission Error | "Access Denied" | Alert user, don't auto-retry |
| Model Refusal | "I can't do this" | Restructure context or upgrade model |
6. Observability and Learning Layer
Responsibility: Record execution traces for debugging and improvement
Critical Data:
- Execution logs — What happened at each step and why
- Decision points — Where agent chose, based on what
- Performance metrics — Tokens spent, execution time, success/failure
- User feedback — "Was this helpful?"
Uses:
- Real-time debugging — When agent fails, see the trace
- Continuous improvement — Identify patterns, improve Harness
- Training data — Seed fine-tuning or reinforcement learning
Risks, Controversies, and Engineering Challenges
Harness Engineering isn't a silver bullet. It introduces new complexity and new risks.
Challenge 1: Documentation Decay and Entropy
Problem: Even with good Harness, knowledge in the codebase goes stale.
A simple markdown file decays. Too many rules overwhelm the task.
Example:
# Our Architecture Rules (written June 2025)
1. All API responses should return { data, error }
2. Use PostgreSQL JSONB for nested structures
3. Service layer should use dependency injection
... (50 more rules)
Six months later, #1 and #3 changed, but docs didn't. Agent follows outdated rules.
Partial Solutions:
- Write architecture rules as executable tests, not comments
- Use LLM verification to complement deterministic checks
- Run periodic garbage collection to audit documentation-implementation alignment
Challenge 2: Model Iteration Speed vs. Harness Stability
Problem: Harness is designed for a specific model. What happens when new models launch?
Each model has different optimal prompting strategies, tool usage patterns, reasoning styles. A perfect Harness for GPT-5 may fail on Claude Opus.
Example:
# Harness optimized for GPT-5
system_prompt = "Think step by step..." # GPT-5 loves this
tools = [file_read, bash_execute] # Minimal tool set
# Claude Opus might prefer
system_prompt = "Analyze carefully, consider alternatives..."
tools = [file_read, bash_execute, web_search, ...] # More tools
Schmid's Recommendation: "Build to Delete"—design Harness assuming it'll be replaced with each new model release.
Challenge 3: Over-Engineering Risk
Problem: Teams may over-invest in Harness optimization, creating complexity.
Red Flags:
- Harness code exceeds application code
- 10+ middleware layers, each "optimizing"
- Documentation-implementation sync becomes night work
Balance Point:
- Start simple (maybe just a prompt + verification layer)
- Optimize when you see specific bottlenecks
- Regular audits: Is the Harness helping or hurting?
Challenge 4: Deliverability and Explainability
Problem: Complex harnesses are hard to explain to non-technical users.
User wants: "Why did the agent reject my request?"
Answer is: "Because architectural constraint layer 3 detected…" Too technical.
Solutions:
- User-readable rejection messages
- Provide repair suggestions, not just "no"
- Escalation paths ("This needs human review")
Challenge 5: Governance: How Much Human-in-the-Loop?
Problem: Where to inject humans? Too much, agent value disappears. Too little, risk is high.
Typical Governance Levels:
| Operation | Human Intervention |
|---|---|
| Modify non-critical file | Auto, post-review |
| Delete code | Auto, post-review |
| Deploy to production | Required approval |
| Modify schema/API | Required approval |
| Create new database table | Required approval |
No perfect answer. Depends on risk tolerance and trust.
Challenge 6: Learning Curve and Knowledge Transfer
Problem: Building and maintaining Harness requires specialized skills.
Not every team has them. When the Harness expert leaves, what happens?
Long-term Solutions:
- Open-source Harness best practices (LangChain, Anthropic doing this)
- Develop Harness engineering as a career path
- Provide tools and frameworks to lower entry barriers
The Great Shift: Competition Moves from Models to Harnesses
In 2025, everyone competed on model quality. In 2026, everyone competes on Harness quality.
Why the Shift?
Three reasons:
Model Convergence
- GPT-5, Claude Opus 4.5, Gemini 2.0 capabilities are converging
- Incremental improvements are expensive and hard
- Model-based competitive advantage is eroding
Harness Multiplier Effect
- Good Harness can improve existing model performance by 20-30%
- LangChain case: 25 rank positions, 13.7% score improvement
- Cost: improving Harness vs. training new models
Production Reality
- Reliability matters more than raw capability
- Agent not losing control > Agent's raw IQ
- Vercel case: Removing complexity improved performance
New Division of Labor
Old:
AI Researcher → Build better model → Engineer → Integrate
New:
Model Provider (OpenAI, Anthropic, Google)
↓
Model
↓
Harness Engineer → Design framework → App Engineer → Build product
Harness Engineer becomes a distinct role. Not model expert, not app developer, but systems designer.
Business Implications
If competition shifts from models to harnesses:
- Smaller teams can compete — Harness development is lighter weight than model training
- Open-source tools matter more — LangChain, LlamaIndex, Claude Agent SDK become critical
- Consulting and implementation services boom — Many teams need help building harnesses
Conclusion: The System Wins
In 2026, Harness Engineering has evolved from a new idea to a core production requirement. Mitchell Hashimoto's simple observation—"Engineer the environment so agents can't fail that way"—has crystallized into an engineering discipline.
Seven engineers built a million-line product through Harness. Vercel won by deletion. Anthropic won through orchestration. LangChain jumped 25 ranks by improving system design.
Models still matter. But they're no longer the whole story. Real competition happens in the invisible places: system boundaries, constraints, verification loops, and recovery mechanisms.
For engineers building reliable AI systems, Harness Engineering is no longer optional. It's essential. Not because it's trendy, but because it works.
References
Primary Sources
- Mitchell Hashimoto - My AI Adoption Journey — Origin of Harness Engineering naming
- Martin Fowler - Harness Engineering — Classic articulation of three components
- OpenAI - Harness Engineering: Leveraging Codex in an Agent-First World — One million lines of code case study
- Philipp Schmid - The Importance of Agent Harness in 2026 — OS metaphor and context engineering
- Vercel - We Removed 80% of Our Agent's Tools — Simplicity > Complexity evidence
- LangChain - Improving Deep Agents with Harness Engineering — Terminal Bench 2.0 case study (rank 30 to 5)
Secondary Analysis
- Anthropic - How We Built Our Multi-Agent Research System — Agent orchestration patterns
- Epsilla - Harness Engineering: The Evolution of AI Development — Prompt → Context → Harness trajectory
- NxCode - Harness Engineering Complete Guide for 2026 — Practical patterns synthesis
- SmartScope - Harness Engineering Overview — Concept clarification
Tools and SDKs
- Claude Agent SDK Documentation — Permissions and hooks implementation
- LangChain - The Anatomy of an Agent Harness — Open-source design patterns
// Related Articles
- [AGENT]
Claude Code 动态工作流:AI 自写 Harness
- [AGENT]
Agent orchestration is the missing layer for enterprise AI
- [AGENT]
AI agents use blockchain as a trust layer
- [AGENT]
8 RAG patterns that turn demos into prod
- [AGENT]
Fine-tuning beats RAG when the goal is style, not facts
- [AGENT]
OpenClaw shows how small businesses use AI staff