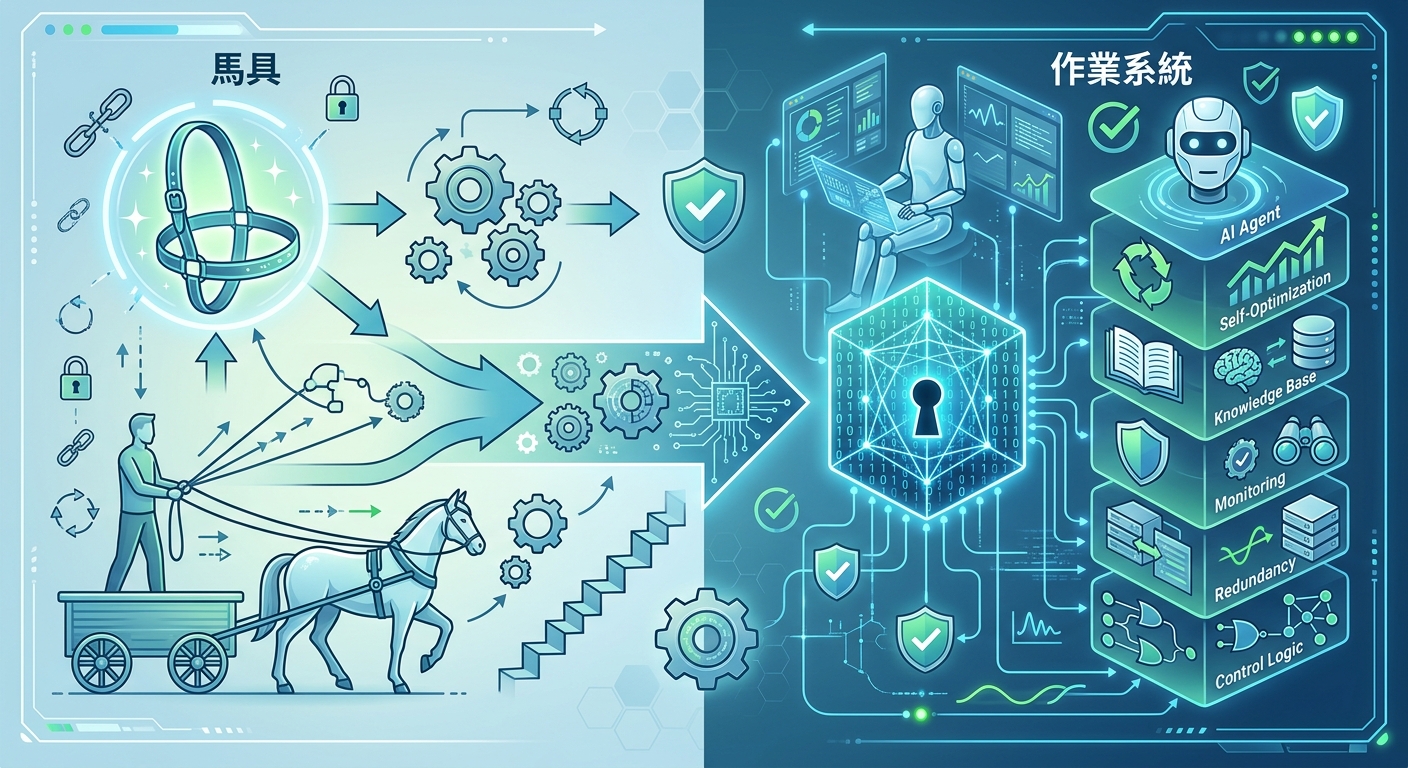
駕馭工程:從「馬具」到「作業系統」,AI Agent 可靠性的終極密碼
Harness Engineering 是設計 AI Agent 外部控制框架的工程實踐,透過上下文工程、架構約束和垃圾回收,將不穩定的大模型轉變為可靠的生產系統。2026 年,決定 Agent 成敗的關鍵不是模型本身,而是包裹它的馬具。

引言:為什麼 GPT-5 還是會犯低級錯誤?
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
你有沒有想過,為什麼最強大的 AI 模型也會莫名其妙地偏離軌道?

2025 年 8 月,OpenAI 內部一個小團隊開始了一個大膽的實驗:讓 Codex Agent 在空白倉庫中從零開始構建一個百萬行代碼的產品。最後,七個工程師透過 Agent 在五個月內完成了通常需要數年的工作——平均每名工程師每天合併 3.5 個 PR,項目進度隨著團隊擴大而加快,而非減慢。
但這個成就的代價不是更聰明的模型。實際上,整個項目的制約之一是「零行手動編寫的代碼」。成功的秘密隱藏在看不見的地方:包裹 Agent 的框架體系。
這就是 Harness Engineering 的故事。
什麼是 Harness Engineering?
Harness Engineering(駕馭工程)是設計 AI Agent 外部控制與執行框架的工程實踐。如果 AI 模型是馬匹,那麼 Harness 就是騎手手中的韁繩、鞍具和一整套馴馬術——它決定了這匹馬去往何方、如何對待失控的時刻。
術語起源
這個概念由 HashiCorp 共同創辦人 Mitchell Hashimoto 在 2026 年 2 月正式命名。在他的文章《我的 AI 採納之旅》中,Hashimoto 將他的一個關鍵洞察命名為「Engineer the Harness」(工程化馬具):
「每當 Agent 犯錯時,不要寄希望於它下次做得更好。而是要工程化環境本身,使其無法再以同樣的方式犯同樣的錯誤。」
這一簡單的原則點燃了整個行業的思想火花。幾週後,OpenAI 發表了關於 Harness Engineering 的詳細報告,Anthropic 將其融入 Claude Code 的核心架構,Google DeepMind 用它優化了代碼生成流程。
為什麼叫「馬具」?
Harness 這個詞本身來自騎馬術語——它是連接騎手和馬匹的工具組。隱喻恰當得令人驚訝:
- 馬 = 大模型 — 原始能力強大但性情不定
- 騎手 = 開發者或使用者 — 希望控制方向和速度
- 馬具 = Harness Engineering — 使控制成為可能的工程系統
沒有馬具,再強的馬也無法拉車。沒有馬具,再聰明的 Agent 也無法在生產環境中穩定運行。
三次演進:從 Prompt 到 Harness
AI 工程在過去三年經歷了三個截然不同的時代。理解這三次演進,你才能理解為什麼 Harness Engineering 在 2026 年會成為行業焦點。
第一代:Prompt Engineering(2023-2024)
時代特徵:魔法咒語
在 ChatGPT 推出的早期,開發者們迷上了 Prompting。經典思路是:寫得更聰明的指示,就能從模型中榨取更多智慧。
- 「讓我們一步步思考…」
- 「你是一個資深軟體工程師…」
- 「輸出 JSON 格式…」
這些技巧有效,但效果上限很低。當面對複雜、多步驟的任務時,Prompt Engineering 的局限性浮現:
- 上下文窗口詛咒 — 無論 Prompt 多詳細,它佔據的 token 空間與實際工作空間競爭
- 魔法數字 — 某個在你的案例中有效的 Prompt,在別人的環境中失效
- 零學習能力 — Agent 每次失敗都重新開始,無法從錯誤中積累經驗
第二代:Context Engineering(2024-2025)
時代特徵:動態知識管理
2024 年,Hugging Face 的 Philipp Schmid 發表了《新的 AI 技能不是 Prompting,而是 Context Engineering》。這篇文章改變了遊戲規則。
核心洞察:大多數 Agent 失敗不是因為模型太笨,而是因為上下文不夠好。
Context Engineering 強調:
- 動態上下文構建 — 根據當前任務動態組裝相關信息,而不是靜態 Prompt
- 知識庫優化 — 建立可搜尋的文檔、代碼結構和 API 文檔,Agent 可以按需擷取
- 工具發現 — Agent 不僅知道什麼工具存在,還知道何時使用、如何使用
到 2025 年中期,Context Engineering 已經成為 LangChain、OpenAI 和 Anthropic 的標準做法。但在實踐中,團隊發現了一個新的瓶頸:光有好的上下文還不夠。
Agent 可能知道該怎麼做,但在複雜的多步工作流中仍會失控。為什麼?
第三代:Harness Engineering(2026~)
時代特徵:外部控制框架
Harness Engineering 回答的問題是:我們不只是給 Agent 更多信息,我們還要給它一個邊界清晰、可預測、可恢復的執行環境。
這不是改進 Prompt,不是優化上下文,而是重新設計整個系統架構。
三代的演進軌跡:
Prompt Engineering
↓
「寫得更好的魔法咒語」
↓
失敗:上下文窗口有限
↓
Context Engineering
↓
「動態組裝更相關的信息」
↓
失敗:Agent 仍在複雜流程中失控
↓
Harness Engineering
↓
「設計整個執行環境,讓 Agent 無法失控」
Philipp Schmid 的作業系統隱喻:比馬具更精確的類比
儘管「馬具」這個比喻很形象,但 Schmid 提出的「作業系統」隱喻更能捕捉 Harness Engineering 的本質。
四層計算棧
| 層級 | 傳統計算 | AI Agent 系統 | 角色 |
|---|---|---|---|
| 應用 | 文字編輯器、遊戲、瀏覽器 | 具體任務的 Agent(如「編寫測試用例」) | 用戶直接使用 |
| 作業系統 | Windows、Linux、macOS | Harness Engineering(Agent Harness) | 管理資源、執行控制 |
| RAM | 8GB、16GB 的物理記憶體 | 上下文窗口 | 有限的工作空間 |
| CPU | Intel、AMD 處理器 | 大型語言模型 | 原始計算能力 |
為什麼作業系統隱喻更準確?
一個現代作業系統不只是「加快 CPU」,而是:
記憶體管理 — 在有限的 RAM 中運行龐大的應用
- AI 類比:在有限的上下文窗口中處理複雜任務
進程排程 — 決定哪個任務何時運行、分配多少資源
- AI 類比:將複雜任務分解為子任務,決定執行順序
驅動程式 — 標準化軟體與硬體的互動
- AI 類比:標準化 Agent 與工具、API、數據庫的互動
權限管理 — 防止應用程序意外或惡意地造成損害
- AI 類比:限制 Agent 可以執行的操作範圍
異常恢復 — 當應用程序崩潰時,作業系統恢復到一致狀態
- AI 類比:當 Agent 陷入循環或做出錯誤決策時恢復執行
馬具比喻告訴我們「控制」的想法。OS 隱喻告訴我們「控制、管理、優化、恢復」的完整系統設計。
三大業界實踐
理論很好,但 Harness Engineering 如何在現實中運作?以下三個案例展示了不同的實踐方向。
OpenAI:7 人團隊 × 百萬行代碼的「馬具完美」
時間線:2025 年 8 月–2026 年 1 月
目標:用 Codex Agent 在空白倉庫中構建一個生產級應用
成果:
- 超過 100 萬行代碼
- 1500+ pull requests 合併
- 7 名工程師(從 3 人開始,後來擴展)
- 3.5 PR/工程師/天 平均合併率
- 速度隨著團隊擴大而加快(通常應該減慢)
- 十分之一的時間相比手動編寫
這聽起來像科幻,但它基於一個鐵律:沒有人手工編寫任何代碼。
OpenAI 的馬具四支柱
根據 OpenAI 發表的詳細報告,他們的馬具包含四個核心部分:
1. 上下文工程:持續增強的知識庫
OpenAI 構建了「持續增強的代碼庫知識庫 + Agent 對動態上下文(如可觀測性數據和瀏覽器導航)的存取」。
這不是靜態文檔。而是:
- 代碼結構文檔 — 新建模組時,Harness 強制更新 architecture 文檔
- API 與工具清單 — 可搜尋的工具索引,包含使用示例
- 可觀測性集成 — Agent 可以查詢前一個 Agent 的執行日誌,學習為什麼它失敗了
2. 架構約束:LLM + 確定性雙層驗證
最有趣的部分:OpenAI 同時使用 LLM 和傳統 linter。
- LLM 層 — Agent 審查自己的代碼,確保邏輯正確
- 確定性層 — 自訂 linter 和結構測試強制執行代碼風格、模組邊界、命名規範
為什麼雙層?因為 LLM 有時會遺漏,傳統 linter 不會。
3. 垃圾回收:熵的持續戰鬥
即使有好的 Harness,Agent 產生的代碼也會積累技術債:
- 死代碼
- 不必要的檔案
- 過時的註解
- 架構違規
OpenAI 的解決方案:定期運行清理 Agent,它們的唯一工作是尋找不一致之處並修復。這是垃圾回收。
4. 反饋迴路:失敗 → 信號 → 改進
OpenAI 採取的最重要哲學:
「當 Agent 失敗時,我們將其視為信號:識別缺少什麼 — 工具、護欄、文檔 — 並將其反饋到倉庫中。」
這不是「希望 Agent 做得更好」,而是「識別系統缺陷並修復系統」。
Anthropic:生成-評估分離架構
方法論:多 Agent 協作,而非單一超級 Agent
Anthropic 在 Claude Code 中內建的 Harness 採用了不同的模式:專門化的 Agent 團隊。
三層 Agent 架構
Orchestrator Agent (領導層)
- 運行最聰明的模型(Claude Opus 4.5)
- 分析用戶請求
- 將工作分解為子任務
- 協調執行順序
Specialist Sub-agents(執行層)
- 運行更快、更便宜的模型(Claude Sonnet 4、Haiku 4.5)
- 並行執行專門任務
- 如:一個 Agent 寫代碼,一個 Agent 寫測試,一個 Agent 寫文檔
Verification Agent(驗證層)
- 審查所有輸出
- 檢查代碼正確性、文檔完整性、測試覆蓋
- 在返回給用戶前提高品質
為什麼分離有效?
績效提升:內部評估顯示這個架構的性能比單個 Claude Opus 4 高出 90.2%。
原因:
- 並行性 — 多個 Agents 可以同時工作,不會相互阻礙
- 專業化 — 每個 Agent 優化於特定任務,而非通才
- 可恢復性 — 一個 Sub-agent 失敗不影響其他的,Orchestrator 可以重新分配
Claude Code 正是這個 Harness 的公開實現。當你在 Claude Code 中寫代碼時,你看到的不是單一 Agent,而是一個完整的團隊在幕後運作。
Google DeepMind:循環驗證的 AlphaCode 2 範式
Google DeepMind 的方法強調迭代改進,而非一次性生成。
儘管 Google 沒有公開詳細的「Generator-Verifier-Reviser」(GVR) 架構論文,但他們在 AlphaCode 2 中展示的實踐反映了 Harness Engineering 的核心:
三階段循環
- Generator — 生成多個代碼候選(通常 > 100 個)
- Verifier — 在測試用例上驗證,排除失敗的候選
- Reviser — 對經過驗證的候選進行微調和最佳化
這不是線性的「寫一次,提交」,而是循環:Generator 可以看到 Verifier 的反饋,重新生成更好的候選。
與開源 CodeContests 競賽的成果
Google DeepMind 用 AlphaCode 2 在 CodeContests 競賽中的排名進入前 15% 的人類程式師。這超越了 GPT-4 和 Claude Opus 的單一生成性能。
差異在哪裡?Harness。不是模型本身,而是圍繞它的驗證和修訂系統。
反直覺經驗:Vercel 為什麼砍掉 80% 的工具
2026 年 2 月,Vercel 發表了一篇令人困惑的文章:《我們移除了 Agent 80% 的工具》。
結果?效能提升了。
故事背景
Vercel 建立了一個文本轉 SQL Agent,用於他們的 Vercel Data Platform。初始版本配備了許多精心設計的工具:
- SQL 查詢執行器
- 數據庫 schema 檢查器
- 表統計工具
- 自訂 Vercel API 包裝器
- 錯誤處理工具
- …… 還有更多
初始性能:80% 成功率。但過程很痛苦:
- 平均 100 步才能完成一個查詢
- 145,000 tokens(成本高)
- 724 秒最壞情況下的延遲
大膽的決定
Vercel 團隊做了反直覺的事:刪除所有自訂工具,只保留一個通用工具:執行任意 bash 命令。
新 Harness:
- 給 Claude 檔案系統存取權限
- 給 Claude 標準的 Unix 工具:
cat、grep、ls - 信任 Claude 自己理解如何導航
結果令人震驚
新版本:
- 100% 成功率(相比 80%)
- 19 步(相比 100)
- 67,000 tokens(相比 145,000,節省 40%)
- 141 秒(相比 724 秒,快 5 倍)
為什麼更少的工具 = 更好的性能?
Vercel 的假設是:模型變得更聰明了,上下文窗口變大了,也許最好的 Agent 架構就是幾乎沒有架構。
深層原因:
認知超載 — 太多工具讓 Agent 困惑,它花時間思考該用哪個工具,而不是解決問題
信任與自由 — 當給予 Agent 基本但強大的原始工具,它反而表現得更好
通用性優於專門性 — 自訂工具可能遺漏邊界情況,通用工具更魯棒
這反映了 Harness Engineering 的一個深刻真理:最好的馬具不是限制性的,而是釋放潛力的。
LangChain 實證:只改 Harness,排名從 30 到 5
LangChain 的案例是 Harness Engineering 有效性的最清晰證據。
基準線
LangChain 的深度 Agent(用於軟體開發任務)在 Terminal Bench 2.0 上排名第 30,分數 52.8%。
Terminal Bench 是一個代碼生成基準,測試 Agent 在實際軟體開發場景中的表現。排名第 30 意味著有 29 個系統比它更好。
實驗設置
LangChain 的關鍵決定:保持模型固定,只改變 Harness。
使用的模型:GPT-5.2-Codex(固定不變)
改變的變數:
- 系統 prompt
- 工具集合和工具設計
- 中間件掛鉤和控制流
核心發現
1. 驗證迴路是遊戲改變者
問題:Agent 寫完代碼後,自己讀了一遍,決定「看起來不錯」,就停止了。沒有實際執行測試。
解決方案:LangChain 實裝了 PreCompletionChecklistMiddleware,強制 Agent 執行驗證通過。
效果:單這一個掛鉤就貢獻了 13.7 百分點的改進。
2. 上下文注入優於口頭說教
問題:Agent 被淹沒在文檔中,遺漏關鍵細節。
解決方案:LocalContextMiddleware 在代碼執行前掃描整個本地結構,主動注入相關信息(文件樹、關鍵檔案內容、測試命令)。
效果:上下文注入單獨貢獻了 7.2 百分點的改進。
3. 計算預算的詭異逆轉
發現:將推理預算設為最高(xhigh)實際上 降低了性能。
xhigh設置:53.9%(由於超時)high設置:63.6%(最佳性能)
理由:更多思考時間不一定更好;Agent 可能陷入分析癱瘓或超時。有時候,約束能改進性能。
最終結果
經過這些改動,LangChain 的 Agent:
- 排名上升到第 5
- 分數從 52.8% → 66.5%
- 僅改變 Harness,未改變模型
這是對 Harness Engineering 有效性最有力的證明:問題不是模型,而是如何使用它。
Martin Fowler 的三大 Harness 組件
讓我們從更結構化的視角重新審視 Harness 的組成。Martin Fowler 與 Birgitta Böckeler 總結的框架已經成為業界標準。
1. 上下文工程(Context Engineering)
定義:持續增強的知識庫 + Agent 對動態數據的存取
上下文工程不是寫更詳細的 Prompt,而是:
構成要素
| 要素 | 描述 | 例子 |
|---|---|---|
| 靜態知識庫 | 代碼結構、API 文檔、架構決策 | README.md、API docs 索引 |
| 動態上下文 | 實時數據,根據任務變化 | 當前檔案樹、相關代碼片段 |
| 工具發現 | Agent 知道有什麼工具,為什麼需要它 | 精選的工具清單 + 使用示例 |
| 可觀測性積分 | Agent 可以查詢前一次執行的日誌 | 錯誤日誌、性能數據 |
為什麼分開靜態和動態?
靜態文檔會過時。動態生成的上下文會過度膨脹。最佳實踐是混合:
- 核心架構和 API 文檔保持靜態更新
- 執行時上下文動態生成(如檔案樹、最近編輯的檔案)
- 兩者結合送給 Agent
2. 架構約束(Architectural Constraints)
定義:強制執行代碼結構和設計模式,既用 LLM 也用確定性工具
這是 Harness 的「守法者」。
雙層驗證方法
第一層:LLM 驗證
- Agent 自己審查生成的代碼
- 檢查邏輯正確性、命名、結構
缺點:LLM 有時會遺漏,或不嚴格執行。
第二層:確定性檢查
- 自訂 linter
- 結構測試(如:所有
user_前綴的函數必須在user.ts中) - 模組邊界檢查(如:
data/層不能直接導入ui/層)
架構約束的例子
假設你建立一個 Clean Architecture 應用。Harness 可以強制:
// 違規 ❌ — data 層不能導入 ui 層
import { Button } from '../ui/button'; // Linter 檢測並拒絕
// 正確 ✅
import { UserRepository } from './user.repository'; // Linter 允許
這不是建議,而是強制。每個 commit 都要通過。
3. 垃圾回收(Garbage Collection)
定義:定期運行清理 Agent,尋找並修復不一致之處
代碼熵是真實的。Agent 生成的代碼尤其容易積累技術債:
- 死代碼(被移除的特性卻留下的函數)
- 過時的註解
- 遺漏的單元測試
- 違反命名規範的變數
- 文檔與實現不一致
Garbage Collection Agent 的運作方式
- 掃描 — 定期掃描整個代碼庫
- 檢測 — 識別不一致(用規則和 LLM)
- 報告 — 生成修復提案
- 修復 — 自動修復或標記待人工審查
例子
# 每週執行一次垃圾回收
$ npm run gc
結果:
- 找到 12 個已移除的 API 端點的死代碼
- 發現 3 個過時的文檔
- 識別 5 個違反命名規範的變數
- 建議修復(可自動應用或人工審查)
Harness Engineering 的六大核心模組
綜合前述實踐,Harness Engineering 的完整框架包含六個核心模組。
1. 上下文管理引擎
職責:在有限的上下文窗口中放置最相關的信息
實現方式:
- 聲明式上下文規則(「執行 Python 腳本時包含 .env 範本」)
- 向量相似度搜尋(找到最相關的代碼片段)
- 優先級佇列(重要信息優先)
工具:Supabase Vector DB、Pinecone、LangChain 的 RecursiveCharacterTextSplitter
2. 工具與能力層
職責:定義 Agent 可以做什麼,以及如何做
核心決定:
- 提供高層次抽象(如
run_command)還是細粒度工具? → Vercel 案例表明:高層次抽象更好 - 工具有多少(Vercel 的教訓:越少越好,除非有明確的理由)
工具集合例子:
- 文件系統存取(read, write, delete)
- 代碼執行(run Python, run bash)
- 搜尋和瀏覽(Google search, Brave API)
- 外部 API(Stripe, AWS, 自訂 API)
3. 控制流協調器
職責:決定任務執行的順序和分支
三種常見模式:
a) 線性執行 — 一個步驟接一個
Plan → Code → Test → Deploy
b) 並行執行 — 多個 Agents 同時工作
Code Agent ──┐
Test Agent ─┼→ Verify
Doc Agent ──┘
c) 循環執行 — 生成 → 驗證 → 修訂 → 再驗證
Generate → Verify → Revise → Verify (loop)
4. 驗證與反饋層
職責:檢查輸出品質,提供可操作的反饋
驗證類型:
| 驗證 | 方法 | 例子 |
|---|---|---|
| 語法驗證 | 確定性(Linter) | TypeScript tsc --noEmit |
| 邏輯驗證 | 自動化測試 | Unit tests, Integration tests |
| 風格驗證 | 規則引擎 | Prettier, ESLint |
| 語義驗證 | LLM 審查 | 「這個函數名是否有意義?」 |
| 商業邏輯驗證 | 人工或規則 | 「這個功能符合產品需求嗎?」 |
5. 恢復與重試機制
職責:當 Agent 失敗時,優雅地恢復
故障模式與恢復:
| 故障 | 症狀 | 恢復策略 |
|---|---|---|
| 工具超時 | API 無響應超過 30 秒 | 指數退避重試 (1s, 2s, 4s) |
| 上下文溢出 | 超過模型 token 限制 | 動態截斷或分解為子任務 |
| 無限循環 | 相同步驟重複 > 5 次 | 標記為失敗,回滾到檢查點 |
| 權限錯誤 | 「Access Denied」 | 告知用戶,不自動重試 |
| 模型拒絕 | 「I can't do this」 | 重新組織上下文或升級至更強模型 |
6. 可觀測性與學習層
職責:記錄執行軌跡,以便改進和調試
關鍵數據:
- 執行日誌 — 每一步做了什麼、為什麼
- 決策點 — Agent 在哪裡做出選擇,基於什麼
- 性能指標 — 花費的 token、執行時間、成功/失敗
- 用戶反饋 — 「這個結果有幫助嗎?」
用途:
- 即時除錯 — 當 Agent 失敗時,看清執行軌跡
- 持續改進 — 識別常見失敗模式,改進 Harness
- 訓練數據 — 為微調或強化學習提供數據
風險、爭議與工程挑戰
Harness Engineering 不是銀彈。它引入了新的複雜性和新的風險。
挑戰 1:文檔衰變與熵戰爭
問題:即使有好的 Harness,代碼庫中的知識仍會過時。
一個簡單的 markdown 文件會迅速衰變,變成過時的。太多指導會淹沒任務。
具體例子:
# 我們的架構規則(寫於 2025 年 6 月)
1. 所有 API 回應應返回 { data, error }
2. 使用 PostgreSQL JSONB 儲存嵌套結構
3. Service 層應使用 dependency injection
... (還有 50 條規則)
6 個月後,#1 和 #3 改了,但文檔沒更新。Agent 遵循過時的規則。
解決方案(部分):
- 將架構規則寫成可執行的測試(不是評論)
- 使用 LLM 驗證來補充確定性檢查
- 定期垃圾回收,審計文檔與實現的一致性
挑戰 2:模型迭代速度 vs Harness 穩定性
問題:Harness 是為特定模型設計的。當新模型推出時會發生什麼?
每個模型有不同的最優提示策略、工具使用模式、推理風格。為 GPT-5 設計的完美 Harness 可能在 Claude Opus 上表現糟糕。
例子:
# 為 GPT-5 優化的 Harness
system_prompt = "Think step by step..." # GPT-5 喜歡
tools = [file_read, bash_execute] # 精簡工具集
# Claude Opus 可能更喜歡
system_prompt = "Analyze carefully, consider alternatives..."
tools = [file_read, bash_execute, web_search, ...] # 更多工具
Philipp Schmid 的建議:「Build to Delete」— 設計 Harness 時,假設它會隨著每個新模型推出而被替換。
挑戰 3:過度工程化風險
問題:團隊可能投入過多精力優化 Harness,以至於過度複雜化。
紅旗:
- Harness 本身的代碼超過應用代碼本身
- 有 10+ 層中間件,每層都做「優化」
- 文檔與實現之間的同步變成夜間工作
平衡點:
- 從簡單開始(可能就是 Prompt + 一個驗證層)
- 當看到具體瓶頸時再優化
- 定期審計:Harness 是幫助還是礙事?
挑戰 4:可交付性與可解釋性
問題:複雜的 Harness 很難向非技術人員解釋。
用戶想知道:「為什麼 Agent 拒絕了我的請求?」
答案是:「因為架構約束層 3 的確定性檢查檢測到……」 太技術性了。
解決方案:
- 用戶可讀的拒絕消息
- 提供修復建議,不只是「不行」
- 提升路徑(「這個操作需要人工審查」)
挑戰 5:人工在迴路的治理困境
問題:在什麼地方讓人類介入?
太多人工干預,Agent 的優勢蕩然無存。太少人工干預,風險很高。
典型的治理層級:
| 操作 | 人工干預 |
|---|---|
| 修改非關鍵檔案 | 自動,事後審查 |
| 刪除代碼 | 自動,事後審查 |
| 部署到生產環境 | 人工批准前置 |
| 修改 schema 或 API | 人工批准前置 |
| 建立新的數據庫表 | 人工批准前置 |
沒有一個完美的答案。取決於風險承受度和信任度。
挑戰 6:學習曲線與技能轉移
問題:建立和維護 Harness 需要高度專業化的技能。
這不是每個團隊都有的。當建造 Harness 的人離職時會發生什麼?
長期解決方案:
- 將 Harness 最佳實踐開源化(LangChain、Anthropic 正在做這個)
- 發展 Harness 工程師的職業路徑
- 提供工具和框架,降低進入門檻
展望:競爭重心的轉移
2025 年,大家都在競爭最好的模型。2026 年,大家都在競爭最好的 Harness。
為什麼?
三個原因:
模型收斂
- GPT-5、Claude Opus 4.5、Gemini 2.0 的能力越來越接近
- 增量改進變得困難且昂貴
- 基於模型本身的競爭優勢正在消蝕
Harness 的倍增效應
- 好的 Harness 可以讓現有模型性能提升 20-30%
- LangChain 的案例:排名提升 25 位,分數提升 13.7 百分點
- 成本:改進 Harness 而非訓練新模型
大規模部署的現實
- 在生產環境中,可靠性比原始能力更重要
- Agent 不失控比 Agent 智力 IQ 更有價值
- Vercel 的案例:移除複雜性,反而改進了性能
新的分工
舊分工:
AI 研究員 → 構建更好的模型 → 工程師 → 集成到產品
新分工:
模型提供商(OpenAI、Anthropic、Google)
↓
模型
↓
Harness 工程師 → 設計馬具 → 應用工程師 → 構建產品
Harness 工程師成為一個獨立的角色。不是模型專家,不是應用開發者,而是系統設計師。
商業含義
如果競爭重心從模型轉向 Harness,這意味著:
- 較小的團隊可以與大公司競爭 — Harness 通常比模型開發更輕量級
- 開源工具變得更重要 — LangChain、LlamaIndex、Anthropic Agent SDK
- 諮詢和實施服務的機會 — 許多公司需要幫助構建他們的 Harness
結語
2026 年,Harness Engineering 已經從一個新想法演變為生產系統的關鍵組件。Mitchell Hashimoto 的簡單觀察——「工程化環境,使 Agent 無法失控」——已經成為推動 Agent 可靠性的工程學科。
七個工程師透過 Harness 生成了百萬行代碼。Vercel 透過刪除複雜性而獲得了簡單。Anthropic 透過協調多個 Agents 而超越單一超級 Agent。LangChain 透過改進 Harness 而跳升 25 名。
模型仍然重要,但它不再是故事的全部。真正的競爭發生在看不見的地方:系統的邊界、約束、驗證迴路和恢復機制中。
對於想在 AI 時代構建可靠系統的工程師來說,Harness Engineering 不再是可選項。它是必需的。不是因為它很流行,而是因為它有效。
參考來源
一手文章
- Mitchell Hashimoto - 我的 AI 採納之旅 — Harness Engineering 正式命名的起源
- Martin Fowler - Harness Engineering — 三大組件框架的經典闡述
- OpenAI - Harness Engineering: 在 Agent 優先的世界中運用 Codex — 百萬行代碼案例研究
- Philipp Schmid - Agent Harness 在 2026 年的重要性 — 作業系統隱喻和上下文工程
- Vercel - 我們移除了 Agent 80% 的工具 — 簡單性勝過複雜性的實證
- LangChain - 用 Harness 工程改進深度 Agents — Terminal Bench 2.0 從 30 到 5 的案例
二手分析
- Anthropic - 我們如何構建多 Agent 研究系統 — 協調 Agents 的架構模式
- Epsilla - Harness Engineering 演進 — Prompt → Context → Harness 的演進軌跡
- NxCode - Harness Engineering 完整指南 — 實踐模式總結
- SmartScope - Harness Engineering 與 Context Engineering 的區別 — 概念澄清
工具與SDK
- Claude Agent SDK 文檔 — 權限管理和掛鉤
- LangChain Agent Harness 架構 — 開源 Harness 設計模式