Why RAGFlow is the right open-source RAG engine to self-host
RAGFlow is the open-source RAG engine teams should self-host when document fidelity and citations matter.

RAGFlow is the open-source RAG engine teams should self-host when document fidelity matters.
I think RAGFlow is the right choice for teams that care about document fidelity, traceable answers, and control over their own stack.
That is not a generic “open source is better” argument. RAGFlow’s value comes from a specific combination: DeepDoc parsing for messy files, hybrid retrieval in Elasticsearch, and paragraph-level citations that let users verify every answer against the source. Railway’s template makes that stack deployable in one click with MySQL, Redis, MinIO, and Elasticsearch already wired together, which turns a hard systems problem into a practical default for teams that want grounded RAG without buying into a closed SaaS.
First argument: document parsing quality is the real moat
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Most RAG failures start before retrieval. If the parser mangles tables, headers, scanned pages, or multi-column PDFs, the model will answer confidently from broken chunks. RAGFlow’s DeepDoc parser is built for exactly that problem, and the template explicitly supports PDFs, Word docs, scanned images, HTML, Markdown, XLSX, PPTX, and tables. That matters because the hardest knowledge bases are not clean text corpora; they are contracts, runbooks, papers, and policy docs where layout is part of the meaning.
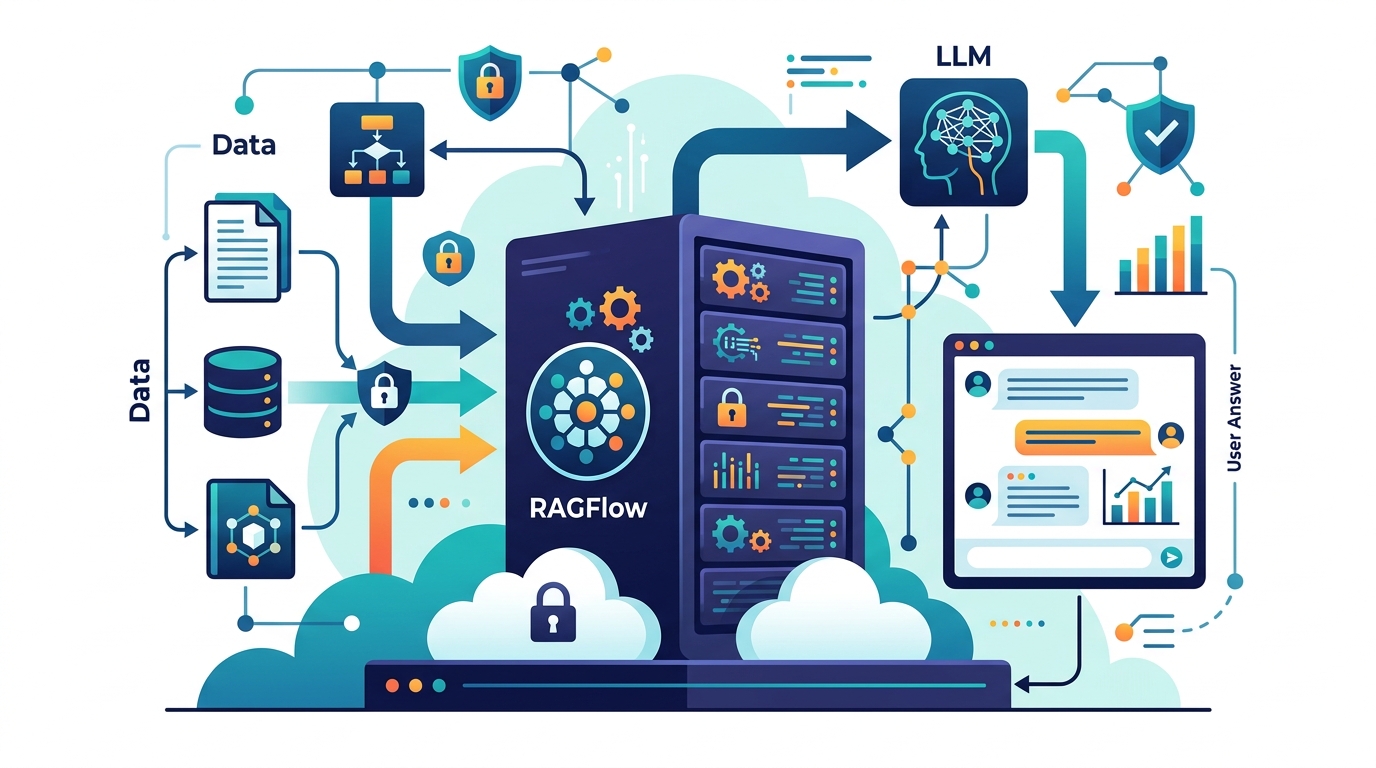
That is why RAGFlow beats “chunk-and-pray” stacks. A document parser that understands structure gives you better chunk boundaries, better retrieval candidates, and fewer hallucinations downstream. In practice, this means a legal team can ask about a clause buried in a scanned annex, or an engineering team can query a postmortem table without first reformatting the source. When the input layer is strong, the rest of the pipeline stops compensating for garbage in.
Second argument: the deployment model is honest about cost and control
RAGFlow is Apache 2.0, so the software itself does not tax you with license fees, per-seat pricing, or feature gating. Railway charges only for the compute and storage you actually use. For a small team, the template’s documented footprint of roughly $20–40 per month for infrastructure is the right kind of price signal: you are paying for real resources, not for artificial packaging around your own data.
That cost structure matters because RAG systems are operationally expensive in ways buyers often underestimate. You need persistent storage for uploaded files, a metadata database, a task queue, and a retrieval index. RAGFlow’s Railway template makes those dependencies explicit instead of hiding them behind a managed black box. MySQL stores tenants and knowledge base metadata, Redis handles queueing and session cache, MinIO stores raw documents, and Elasticsearch powers retrieval. This is a stack you can reason about, back up, and migrate.
The counter-argument
The strongest case against RAGFlow is that self-hosting a five-service RAG stack is still real work. Teams have to manage memory limits, index growth, uptime, secrets, and the operational tax of keeping MySQL, Redis, MinIO, and Elasticsearch healthy. A managed product like Dify or a hosted knowledge platform can look easier because it compresses all of that into a single bill and a single control plane. For small teams without infra expertise, that simplicity is not a luxury.
There is also a product argument against RAGFlow: if your main need is broad app building, SaaS connectors, or a lightweight internal chatbot, a more general platform may be faster to ship. RAGFlow is optimized for document understanding and grounded retrieval, not for replacing every low-code AI workflow tool. If your documents are simple and your retrieval needs are basic, its heavier architecture is unnecessary.
That critique is fair, but it does not beat the core case. The complexity is the price of owning the data path, and RAGFlow earns that price by improving the quality of the answer path. If your use case depends on citations, audits, or high-stakes document accuracy, “simpler” is a false economy. A bad answer delivered quickly is worse than a slower stack that can point back to the exact paragraph it used.
What to do with this
If you are an engineer or founder choosing a RAG stack, use RAGFlow when your source material is messy, your users need citations, and you want infrastructure you can control end to end. Deploy the Railway template, set an external LLM or embedding provider, lock signups after onboarding, and treat the stack like production software from day one. If your priority is document fidelity, RAGFlow is the default you should reach for.
Conclusion
RAGFlow is not the lightest RAG option, but it is the one built for serious document work. Its parser, retrieval design, and citation-first output solve the problems that make most RAG demos fall apart in production. For teams that want trustworthy answers from private documents, self-hosting RAGFlow on Railway is the right tradeoff.
// Related Articles
- [AGENT]
Perplexity should build Teammate as a coding agent, not a copilot
- [AGENT]
HP adopts OpenAI Frontier across global operations
- [AGENT]
Build a production vector DB for RAG
- [AGENT]
Ornith-1 turns agent coding into a server
- [AGENT]
Crypto AI agents are useful, but only for narrow workflows
- [AGENT]
AI Agents in Crypto: 2026 Protocol Guide