Why RAG in Microsoft Foundry needs better indexes, not bigger prompts
RAG in Microsoft Foundry succeeds when retrieval is indexed well, not when prompts get longer.
RAG in Microsoft Foundry works best when retrieval is indexed well, not when prompts get longer.
RAG is not a prompt-engineering trick, and Microsoft Foundry’s own guidance makes that plain: if your app needs private, fast-changing, or source-cited answers, the real leverage sits in retrieval quality, index design, and grounding discipline. The model is only as trustworthy as the content you feed it, and the article’s architecture choices, from Azure AI Search to agentic retrieval, all point to the same conclusion: stop treating the LLM as the fix and start treating the index as the product.
Indexes are the real control plane for RAG
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Foundry frames an index as the structure that makes retrieval reliable, and that matters because RAG fails first at search, not generation. If your system cannot find the right passage quickly and consistently, the model will confidently synthesize from the wrong evidence. Microsoft calls out keyword, semantic, vector, and hybrid search for a reason: each mode changes what “relevant” means, and that choice determines whether the answer is grounded or merely plausible.
There is a practical clue in the recommendation to use Azure AI Search as the index store for RAG scenarios. That is not just a product preference; it is an admission that retrieval is a first-class systems problem. A good index also carries citation metadata such as titles, URLs, and file names, which means the index is doing double duty: it is not only finding content, it is shaping whether the answer can be audited. In other words, the index is where accuracy becomes operational.
Agentic retrieval beats single-shot RAG for real work
Classic RAG usually fires one query, grabs a few chunks, and hopes the prompt is enough. Foundry’s agentic retrieval is a better answer because it turns retrieval into a planning problem. The model can split a complex user request into focused subqueries, run them in parallel, and return structured grounding data. That is a serious upgrade for multi-turn chat, where the user’s intent evolves and the first query is rarely the whole query.
The article’s own feature list shows why this matters: context-aware planning, parallel execution, semantic ranking, and optional answer synthesis. Those are not cosmetic improvements. Parallel subqueries reduce latency and widen coverage, while structured outputs make citations and tracing easier. For teams building production systems, that means less prompt glue code and fewer brittle heuristics. Agentic retrieval is the right default when the user asks layered questions, not when they ask for one neat fact.
RAG is a data pipeline problem before it is an AI problem
Microsoft’s implementation workflow is telling: prepare data, chunk it, set up an index, connect Foundry, build the app, then test and evaluate. That sequence puts data preparation ahead of model calls, where it belongs. If chunking is sloppy, embeddings are low quality, or search configuration is mismatched, the system will fail before the LLM even gets a chance to reason. The article does not hide that dependency; it says poor data preparation directly impacts response quality.
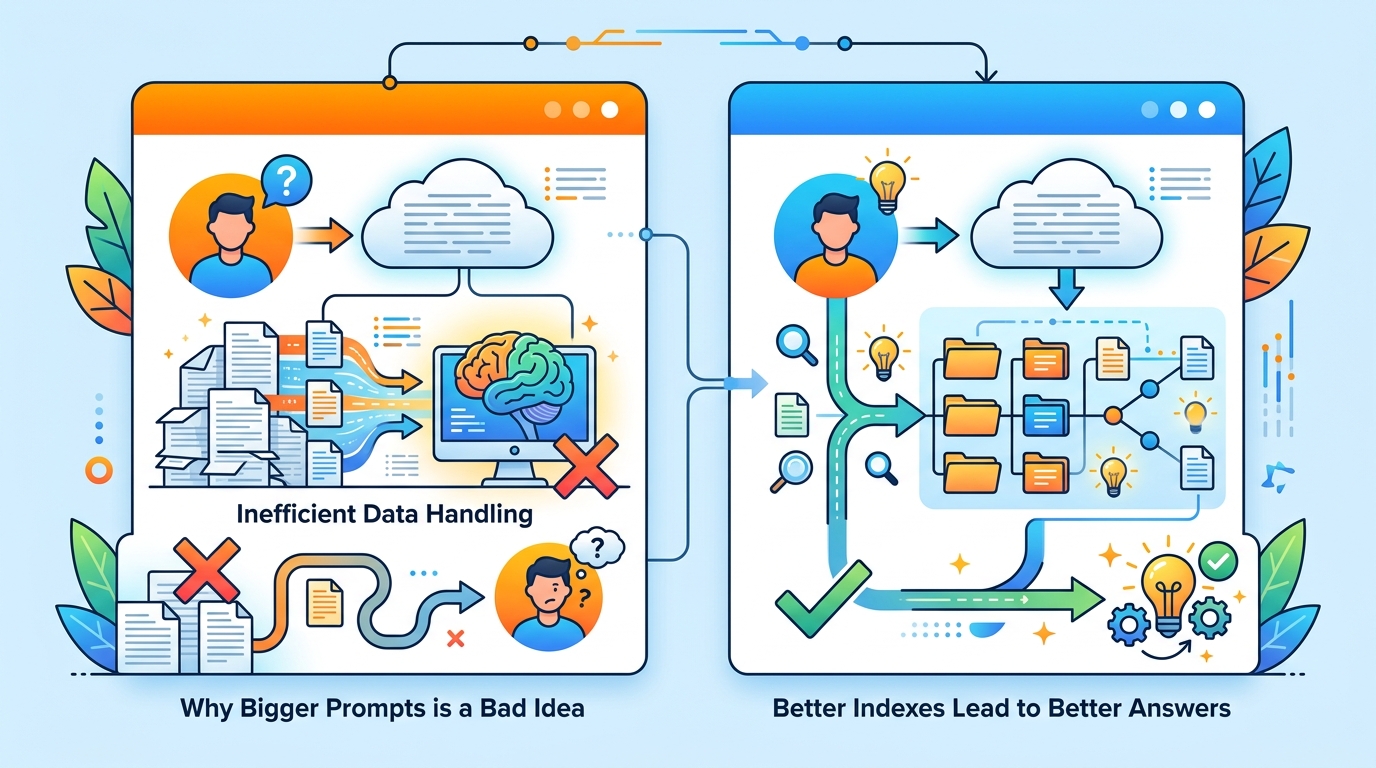
This is why the common obsession with “better prompts” is misplaced. A prompt cannot recover passages that were never retrieved, and a clever system message cannot repair a broken chunking strategy. The most useful part of the Foundry guidance is the troubleshooting section, because it names the actual failure modes: irrelevant passages, hallucination despite grounding, latency, and token bloat. Those are pipeline defects. Fixing them means tuning the data path, not polishing the prose around the model.
The counter-argument
The best objection is that RAG adds complexity and cost, and that is true. Microsoft says retrieval adds round trips and compute, embeddings add indexing and sometimes query-time overhead, and retrieved passages consume tokens. If a team only needs stable behavior or style changes, fine-tuning can be cleaner. And if the use case is an agent, retrieval may belong as one tool among several rather than as the whole architecture.
That critique is valid, but it does not weaken the case for index-centered RAG. It strengthens it. The article is explicit that you should choose the right approach based on the problem: use RAG for private or frequently changing data, fine-tuning for behavior changes, and agent tools when retrieval is just one capability. The mistake is not using RAG; the mistake is using it everywhere. Once you accept that boundary, the index still remains the core asset whenever freshness, provenance, and citations matter.
What to do with this
If you are an engineer, design the retrieval layer before you touch the prompt. Pick the index mode that matches the content, store citation metadata from day one, enforce access control at retrieval time, and test with real user questions rather than synthetic toy queries. If you are a PM or founder, budget for indexing, evaluation, and security as part of the product, not as implementation details. RAG is only compelling when your team treats the index as infrastructure and grounding as a product requirement.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production