Rubric-Based DPO for Visual Preference Tuning
rDPO uses instance-specific rubrics to make visual preference optimization more fine-grained, improving filtering and benchmark results.
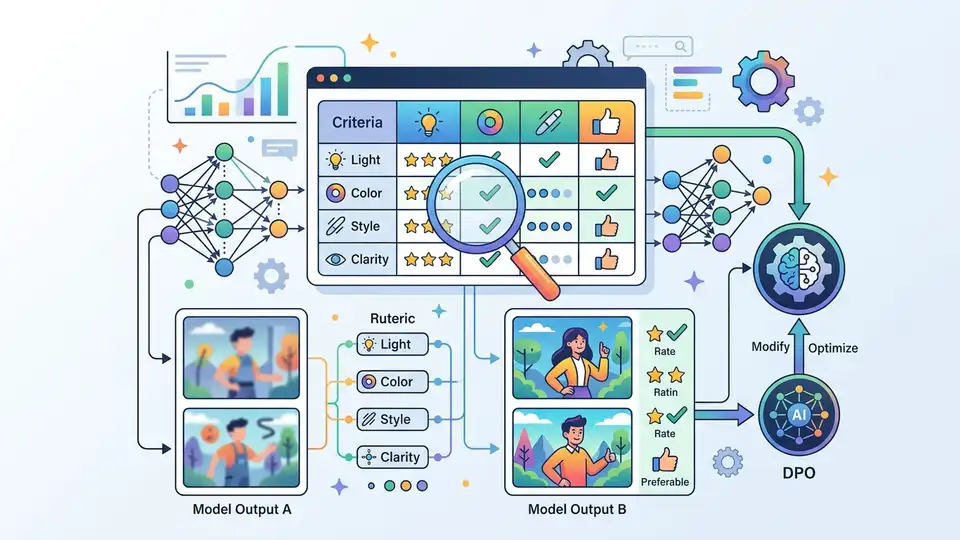
Most preference-optimization pipelines are built on a blunt assumption: if one response is better than another, the model can learn from that pair alone. This paper argues that for multimodal tasks, that is often not enough. The authors introduce Visual Preference Optimization with Rubric Rewards, a framework called rDPO that replaces coarse outcome signals with checklist-style, instance-specific rubrics.
Why should engineers care? Because visual reasoning is usually judged on details: whether the answer noticed the right object, followed the instruction, and handled the image-specific constraints. If your preference data misses those details, your optimizer can learn the wrong lesson. rDPO is a practical attempt to make preference data reflect the actual quality differences that matter in multimodal systems.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The paper starts from a familiar issue in Direct Preference Optimization (DPO): the method is only as good as the preference data behind it. In multimodal settings, the authors say existing pipelines often rely on off-policy perturbations or coarse outcome-based signals. Those signals can work for broad ranking, but they are not a great fit for fine-grained visual reasoning.
That matters because image-based tasks are rarely just about producing a globally “better” answer. A response can be fluent and still miss a small but critical visual detail. If the data collection process only captures overall outcome quality, the model may never learn which specific criteria actually separate good from bad answers on a given image-instruction pair.
The paper’s core claim is simple: if the task is instance-specific, the reward signal should be instance-specific too. Instead of asking annotators or a judge to make a single coarse choice, rDPO asks for rubric-based evaluation that breaks the response down into essential and additional criteria.
How rDPO works in plain English
rDPO builds a checklist-style rubric for each image-instruction pair. That rubric contains the criteria needed to score responses from any policy, which means the evaluation is not tied to a single model’s style or output distribution. In other words, the rubric is meant to describe what matters for that specific example, not just what looks generally good.
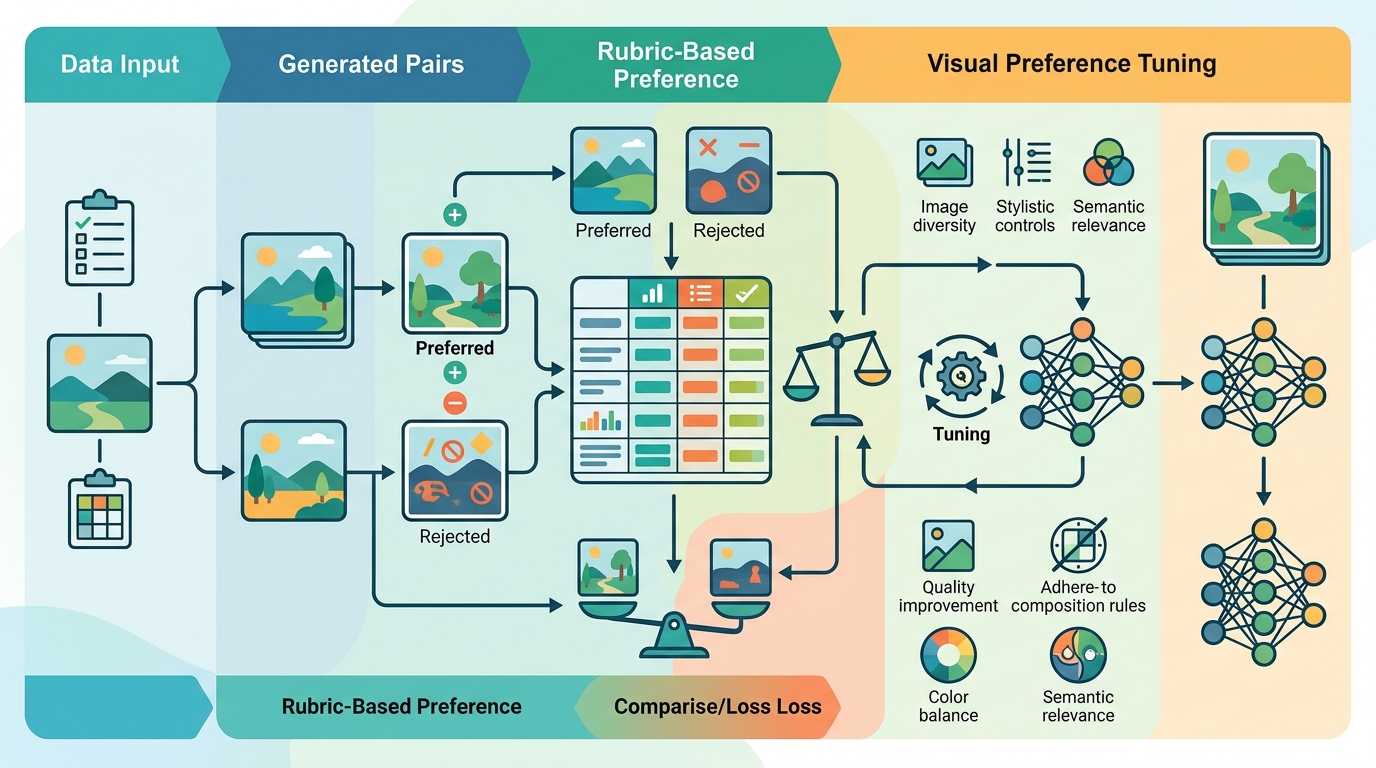
The paper says the instruction-rubric pool is built offline and then reused during the construction of on-policy data. That is an important implementation detail: the rubric generation is not a one-off annotation pass for each training step. Instead, the system creates reusable criteria ahead of time and applies them when building preference data from the current policy.
In practice, that means rDPO tries to connect two pieces of training infrastructure that are often separated: data generation and reward assessment. The on-policy part gives the model data closer to its current behavior, while the rubric adds criterion-level feedback so the preference signal is more precise than a simple win/loss label.
The paper frames this as a better fit for visual preference optimization because the feedback is both local and structured. Local, because it is tied to the specific image-instruction pair. Structured, because it is based on essential and additional criteria rather than a single holistic score.
What the paper actually shows
The abstract reports results in three places: reward modeling benchmarks, downstream benchmarks, and a comprehensive scalability benchmark. The paper does include concrete numbers, which makes it easier to judge the method than many abstract-only claims.
On public reward modeling benchmarks, rubric-based prompting “massively improves” a 30B-A3B judge and brings it close to GPT-5.4. The abstract does not provide the exact benchmark scores for that comparison, so it is not possible to quantify the gap beyond that qualitative statement.
On public downstream benchmarks, the paper says rubric-based filtering raises the macro average to 82.69. By contrast, outcome-based filtering drops to 75.82 from 81.14. That is the clearest signal in the abstract that rubric-guided filtering is not just a nice idea—it can materially change downstream performance in the authors’ setup.
The scalability result is also concrete. On a comprehensive benchmark, rDPO achieves 61.01, outperforming the style-constrained baseline at 52.36 and surpassing the 59.48 base model. The abstract does not name the benchmark in the text provided here, so the safest reading is that rDPO scales better than the baseline and moves past the starting model on that evaluation.
What the paper does not show in the abstract is just as important. There are no training cost figures, no latency numbers, no annotation throughput metrics, and no details on how hard it is to build the rubrics in practice. So while the performance results are promising, the operational cost of adopting this method remains unclear from the source material provided.
Why this matters for developers
If you are building multimodal assistants, vision-language evaluators, or any system that depends on preference tuning, this paper is pointing at a real failure mode: generic preference labels can be too coarse for image-grounded reasoning. A model may optimize toward responses that look better overall while still missing the criteria that matter for a specific visual task.
rDPO suggests a more engineering-friendly direction: make the reward signal explicit and task-local. That can be useful whether you are training the policy itself or building a judge model that scores outputs. The paper’s result that rubric-based prompting improves a 30B-A3B judge also hints that the method may be useful beyond pure policy optimization, especially where evaluation quality is a bottleneck.
There is also a data-engineering lesson here. The authors emphasize offline construction of an instruction-rubric pool that gets reused later. That matters because it hints at a way to amortize rubric creation instead of redoing the work for every sample. For teams thinking about scalable annotation pipelines, that is likely the most practical part of the proposal.
Limitations and open questions
The abstract is strong on outcomes and light on implementation detail, so several open questions remain. How expensive is rubric creation compared with standard preference labeling? How consistent are rubrics across annotators or automated judges? How much of the gain comes from better data selection versus the rubric structure itself?
There is also a broader question about portability. The paper says the rubrics are instance-specific, which is exactly what makes them powerful. But that also means the approach may be harder to generalize across domains where the instruction and visual content vary widely. A team would likely need a robust rubric-generation process to make this work at scale.
Finally, the abstract does not provide benchmark names for every result, nor does it include full ablations in the text provided here. So while the direction is clear—on-policy data plus criterion-level feedback beats coarse outcome filtering—the exact boundary conditions are still something you would want to inspect in the full paper before adopting the method.
The main takeaway is straightforward: if your multimodal preference data is too vague, your optimizer will be too. rDPO is an attempt to fix that by turning visual preference learning into a rubric-driven process, and the reported numbers suggest that this extra structure can pay off.
- Core idea: replace coarse preference labels with instance-specific rubrics.
- Training setup: build rubrics offline, then reuse them for on-policy data construction.
- Reported gains: better reward modeling, better downstream macro average, and a stronger scalability result.
- Main caveat: the abstract does not reveal the full cost of rubric creation or the full benchmark setup.
For practitioners, the value is not just in the reported scores. It is in the design pattern: if your task depends on subtle visual criteria, make those criteria explicit before you ask the model to optimize against them.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10