Server Learning Hardens Federated Learning
A federated learning defense that mixes server-side learning, client filtering, and geometric median aggregation to resist malicious clients.

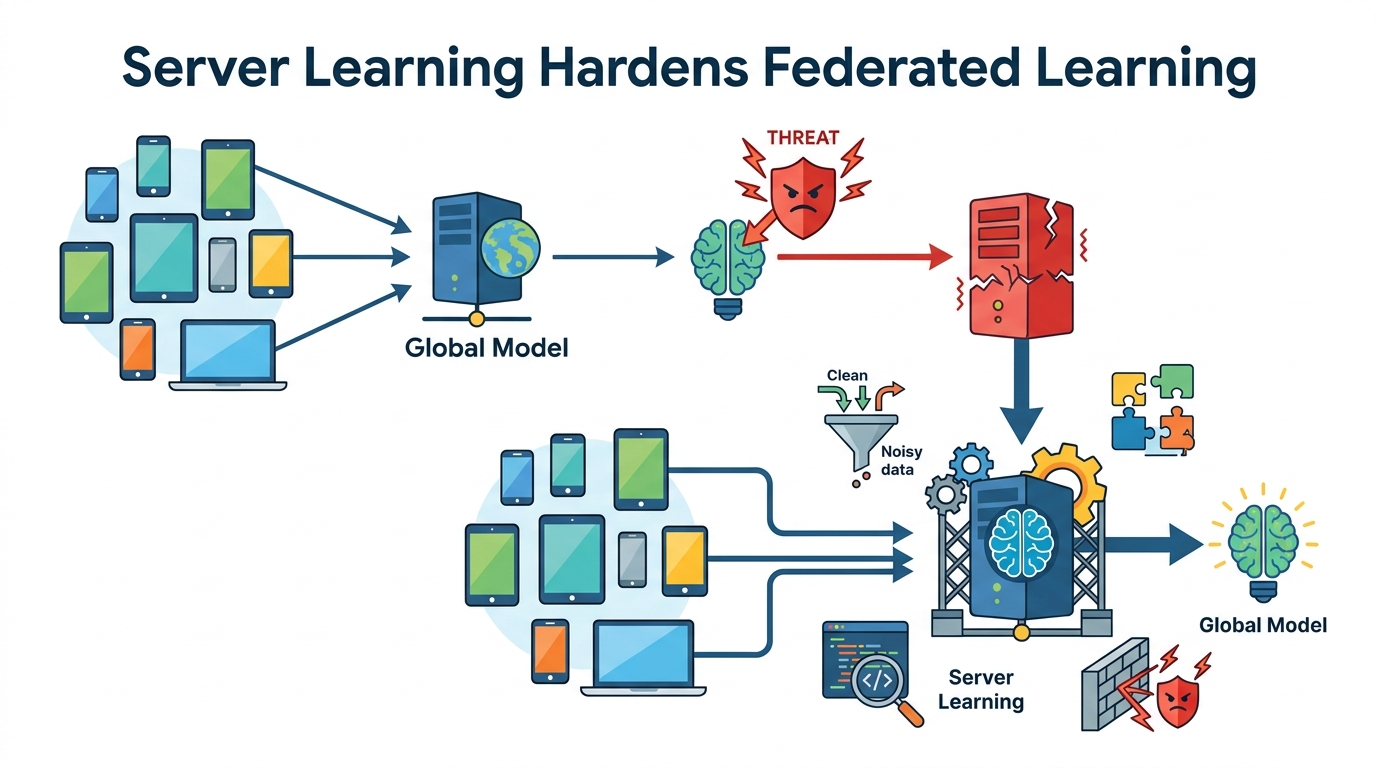
Federated learning is supposed to keep data on devices, but that does not make it automatically safe. In Enhancing Robustness of Federated Learning via Server Learning, the authors look at how a server can actively help defend training when some clients are malicious and the client data are not identically distributed.
The practical idea is straightforward: do not rely only on client updates. Add a small server-side dataset, filter suspicious client updates, and combine the remaining updates with geometric median aggregation. The paper argues that this combination can make federated training more robust even under difficult conditions.
What problem this paper is trying to fix
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Federated learning is often sold as a privacy-friendly way to train models across many clients without centralizing raw data. But in real deployments, the clients are rarely uniform. Their data are usually non-IID, meaning each client sees a different slice of the world. That alone already makes optimization harder.

Now add malicious clients into the mix. A bad actor can send poisoned or otherwise harmful updates and push the global model off track. Many defenses assume the clients behave roughly similarly, or that the server can trust the aggregate signal enough to recover. This paper is focused on the harder case: malicious attacks plus non-IID client data.
The authors' point is that robustness should not depend entirely on the clients. If the server has even a small amount of its own data, it can participate in learning and use that extra signal to judge or stabilize the incoming client updates.
How the method works in plain English
The paper proposes a heuristic algorithm built from three pieces: server learning, client update filtering, and geometric median aggregation. The abstract does not spell out every implementation detail, but the high-level flow is clear enough to understand the design intent.
First, the server does some learning on its own small dataset. That dataset can be synthetic, and the paper says its distribution does not have to closely match the clients' aggregated data. That matters because it lowers the bar for deployment: the server does not need a large, perfectly representative dataset to contribute useful information.
Second, the system filters client updates. The goal is to remove or downweight suspicious client contributions before they can distort the model. The abstract does not specify the exact filtering rule, so this should be treated as a heuristic defense rather than a formally complete guarantee.
Third, the method uses geometric median aggregation. In plain English, instead of averaging client updates in a way that can be pulled hard by outliers, the geometric median tries to land near the center of the update cloud in a more outlier-resistant way. That makes it a natural fit when some clients may be malicious.
Put together, the pipeline is trying to do something practical: let the server act as a stabilizing reference point, reject obviously bad updates, and then aggregate the rest in a way that is less sensitive to extreme values.
What the paper actually shows
The paper reports experimental evidence that this approach can improve model accuracy under malicious attack, even when the malicious fraction is high. The abstract specifically says the fraction of malicious clients can be more than 50% in some cases and the method still yields significant improvement in accuracy.
That is the most concrete result available from the source material. The abstract does not provide benchmark tables, exact accuracy numbers, dataset names, attack types, or ablation results, so those details are not available here. In other words, the claim is promising, but the public summary is light on the experimental specifics engineers would want before treating it as a drop-in defense.
One notable detail is the server dataset requirement. The authors say the server's dataset can be small and even synthetic. They also say its distribution does not need to be close to the distribution of the clients' aggregated data. That is an important practical claim because it suggests the defense may be usable even when the server cannot collect representative real-world data.
Still, the paper frames the method as a heuristic algorithm. That wording matters. It signals a practical approach that works in experiments, not a proof that all attacks are defeated or that the method is optimal in every federated learning setting.
Why developers should care
If you build federated systems, the main takeaway is that the server does not have to be passive. Even a small amount of server-side data can be used as a robustness tool, not just a training convenience. That opens up a design space for defenses that are more active than simple aggregation.
This is especially relevant for teams working on systems where client trust is weak or impossible to enforce. Examples could include consumer devices, edge deployments, or cross-organization training where some participants may be noisy, compromised, or adversarial. The paper suggests that a server-side signal can help when client behavior is not trustworthy.
From an implementation perspective, the appeal is also operational. A small synthetic server dataset may be much easier to maintain than a large curated one. If the method holds up beyond the paper's experiments, it could lower the barrier to adding a robustness layer without requiring a major data collection effort.
Limitations and open questions
The abstract leaves several important questions unanswered. We do not know which attacks were tested, how the filtering step is defined, how the server dataset was constructed, or how sensitive the method is to the size and quality of that server data. Those details matter a lot in practice.
There is also the usual tension with heuristic defenses: robustness in experiments does not automatically translate into a guarantee against adaptive attackers. If an attacker knows the defense strategy, they may be able to shape updates to evade filtering or reduce the effectiveness of geometric median aggregation.
Another open question is cost. Server learning adds extra computation and some extra data management on the server side. The abstract does not quantify overhead, so it is not possible to say whether the robustness gains come with a meaningful runtime or complexity penalty.
Even with those caveats, the paper is useful because it pushes on a real weakness in federated learning: the assumption that aggregation alone is enough. The authors are arguing for a more active server role, and that is a direction developers should pay attention to if they care about adversarial robustness in distributed training.
In short, this paper is less about a flashy new model and more about a practical defense pattern: let the server learn a little, use that signal to screen client updates, and aggregate in a way that is harder to manipulate. For teams shipping federated learning systems, that is a meaningful design idea even before the full experimental details are known.
- Core idea: combine server learning, client update filtering, and geometric median aggregation.
- Best-fit scenario: federated learning with non-IID clients and possible malicious participants.
- Practical claim: the server dataset can be small, synthetic, and not closely matched to client data.
- Evidence in the abstract: significant accuracy improvement, even with more than 50% malicious clients in some cases.
- Main limitation: the summary does not include benchmark numbers or detailed attack settings.
// Related Articles
- [RSCH]
How VLMs Learned Complex Scene Descriptions
- [RSCH]
Visual Pretraining Beats Text-Only in Language Models
- [RSCH]
PHINN-EEG brings topology to dream-state EEG
- [RSCH]
Google’s Android Bench update exposes Gemini’s gap
- [RSCH]
Benchmarks should not pick your LLM in 2026
- [RSCH]
Rust Breaks Into TIOBE’s Top 10