Claude Code 源碼拆解:五步循環與四層防護
從 Claude Code 源碼看五步 Agentic Loop、四層安全防線、三層 Agent 架構與記憶系統。這篇拆解它怎麼把聊天工具變成能跑長任務的開發流程。
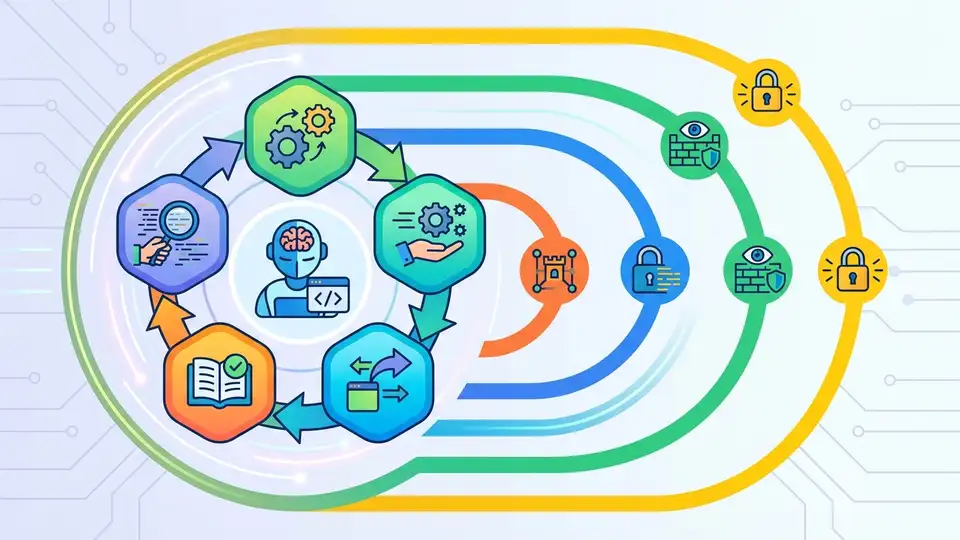
說真的,Claude Code 這次被拆源碼,蠻有意思。文章裡直接點出 五步 Agentic Loop、四層安全防護、三層 Agent 架構。這不是一般聊天機器人的玩法。
它更像一個會跑流程的系統。不是你問一句,它答一句。它會讀任務、規劃、呼叫工具、檢查結果,再決定下一步。講白了,就是把 LLM 放進可控的工作流裡。
對台灣開發者來說,這種拆法很實用。因為我們平常不是在做 demo。真的上線時,卡住的常常是權限、上下文、測試、回滾。Claude Code 的設計,剛好碰到這些痛點。
先看整體:它不是聊天,是執行系統
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
很多人第一次看 Claude Code,會以為它只是命令列版 AI 助手。其實不是。它的核心是持續迭代的執行循環。這個循環把任務拆成幾段,讓模型每次只處理一小步。
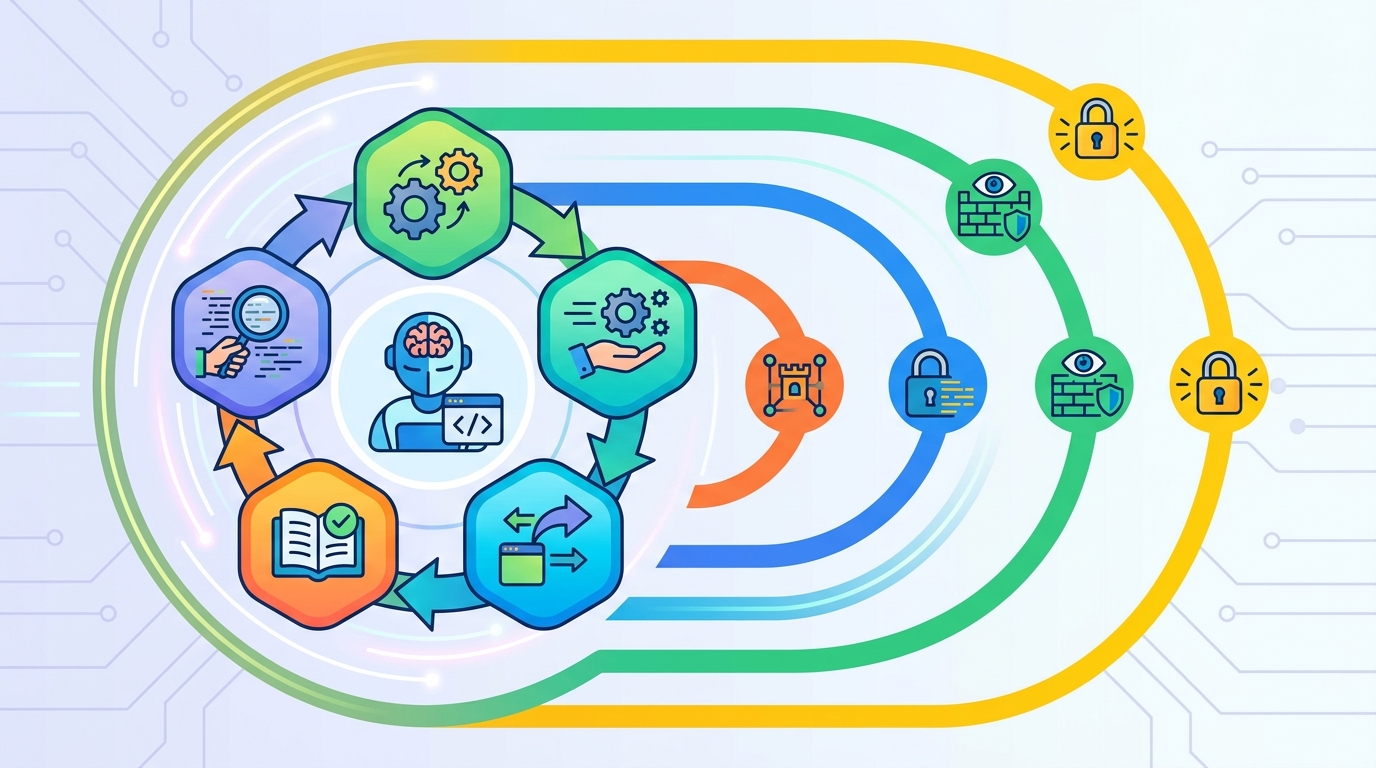
這種做法很像人類做專案。先看需求,再找資料,再改檔案,最後跑測試。差別在於,Claude Code 把這些步驟都塞進系統裡,讓機器自己接著跑。
這裡的重點,不是模型多會講。重點是它能不能把事情做完。對真實專案來說,能做完比會回答重要太多。
- 任務是循環式處理
- 工具呼叫是流程的一部分
- 適合多檔案、多步驟任務
- 目標是完成工作,不只是回話
五步 Agentic Loop 怎麼跑
文章提到的五步流程,是理解 Claude Code 的關鍵。它大致會先整理任務,再做計畫,然後呼叫工具,接著讀回饋,最後決定要不要繼續。這種結構把黑箱拆開了。
這樣做的好處很直接。哪一步出錯,一眼就能看出來。是計畫錯了,還是工具沒回應,還是驗證沒過。對工程團隊來說,這比純文字輸出好 debug 太多。
我覺得這裡最猛的地方,是它把「思考」變成中間狀態。模型不是直接吐答案,而是一路修正。這很像一個會自己迭代的 junior engineer,只是速度快很多。
另外,Claude 系列的內部線索,也讓人看到它不是單一模型在撐場,而是整套系統一起配合。這種產品設計,比單純堆參數更像工程。
“The most important thing you can do is to make sure you have the right problem and the right solution.” — Dario Amodei, Anthropic co-founder and CEO
這句話放在 Claude Code 很貼。它不是在秀模型有多會寫,而是在處理一個更難的問題:怎麼把任務定義對,讓 AI 真能往下做。
上下文壓縮與記憶,才是長任務的核心
長任務最怕什麼?不是模型不夠聰明,是它忘東忘西。對話一長,歷史資料就會爆掉。模型會開始忘記約束,甚至前後打架。這是很多 AI 編程工具的老問題。
Claude Code 的解法,是做上下文壓縮和記憶管理。它不是死記所有內容,而是保留真正有用的部分。像任務目標、已完成動作、限制條件,這些會留下來。沒那麼重要的細節就壓掉。
這個方向很務實。因為真實開發不是背誦聊天紀錄。真實開發要的是狀態連續性。系統知道現在做到哪,下一步該接哪,這才有用。
文章也提到記憶系統不只是暫存。它會影響後續任務的偏好。這代表 Claude Code 不是只看當下對話,而是把過去經驗變成可重用上下文。這點很像一個會記得你專案習慣的同事。
- 壓縮無關歷史資料
- 保留目標、限制與結果
- 記憶會影響後續任務
- 更適合長時間修改大型 repo
四層安全防護,才敢碰真實代碼庫
能進終端機,不代表能亂來。Claude Code 之所以能接進開發流程,安全設計一定要夠細。文章提到四層防護,這很合理。因為 Agent 一旦能讀寫檔案、執行命令,就不能只靠模型自覺。
第一層是任務邊界。系統先決定它能處理什麼。第二層是工具權限。它能不能寫檔、跑指令、碰網路,都要管。第三層是行為檢查。危險操作要擋下來。第四層是審計與回饋。出事要能追。
這種設計很像企業裡的權限控管。不是因為 AI 很壞,而是因為 AI 會犯錯。講白了,LLM 再強,也不能直接放飛。
Anthropic Research 一直強調安全與可控。Claude Code 的源碼拆解,把這件事講得很清楚。能執行的 AI,一定要有多道閘門。
- 任務邊界限制可做內容
- 工具權限控制讀寫能力
- 行為檢查攔高風險操作
- 審計機制保留追蹤路徑
和其他編程助手比,差在哪裡
把 Claude Code 跟其他工具放一起看,差別很明顯。GitHub Copilot 很強,但它多半偏向補全和建議。OpenAI Codex 也很能生成,但常見形態還是圍繞輸出內容。
Claude Code 更像任務執行器。它不是只幫你寫一段,而是追著任務往下做。這個差異很現實。前者適合局部補碼,後者適合跨檔案修改、跑測試、修錯誤。
數字上也能看出差異。局部補全通常是 1 個檔案、1 段函式、1 次建議。Agent 化流程則常碰到 5 到 20 個檔案,還要經過多輪驗證。這兩種工作型態,根本不是同一件事。
- Copilot 偏補全與提示
- Codex 偏生成與工作流
- Claude Code 偏跨檔案任務完成
- 長任務裡,閉環比單次輸出重要
這其實是整個 AI 編程的方向
我覺得 Claude Code 的重點,不是某個神奇技巧,而是它把 AI 編程的方向講得很直白。未來的工具,不會只比誰寫得快。會比誰能理解任務、維持狀態、處理失敗,還能安全收尾。
這也解釋了為什麼很多純聊天式產品,到了真實專案就卡住。因為真實專案不是一次問答。它是連續任務。你要改設定、補測試、修 CI、看 log、再改一次。沒有循環和記憶,根本撐不住。
從產業角度看,這類 Agent 系統會越來越像開發流程的一部分。它們不只是 IDE 外掛,也不是單純對話框。它們會吃進 repo、吃進權限、吃進測試結果,然後自己往下跑。
如果你問我,下一步該看什麼,我會看兩件事。第一,這類系統能不能在 10 分鐘內處理完整任務。第二,它在失敗時能不能自己回頭修。這比秀一段漂亮 code 重要多了。
結尾:別只看它會不會寫,先看它能不能做完
Claude Code 的源碼拆解,最有價值的地方,是把 AI 編程工具從「會講」拉到「會做」。五步循環、記憶壓縮、四層防護,這些東西拼起來,才像一個真的能進開發流程的系統。
我的判斷很直接。接下來評估這類工具時,別先看 demo。先問三個問題:它能不能記住目標?能不能處理失敗?能不能在權限內安全收尾?如果答案都不差,那它就不只是助手了。
你如果是工程師,現在就可以拿一個真實 repo 測。別拿玩具專案。拿一個有測試、有 lint、有 CI 的專案,看看它能不能真的把任務跑完。這才是最誠實的檢驗方式。