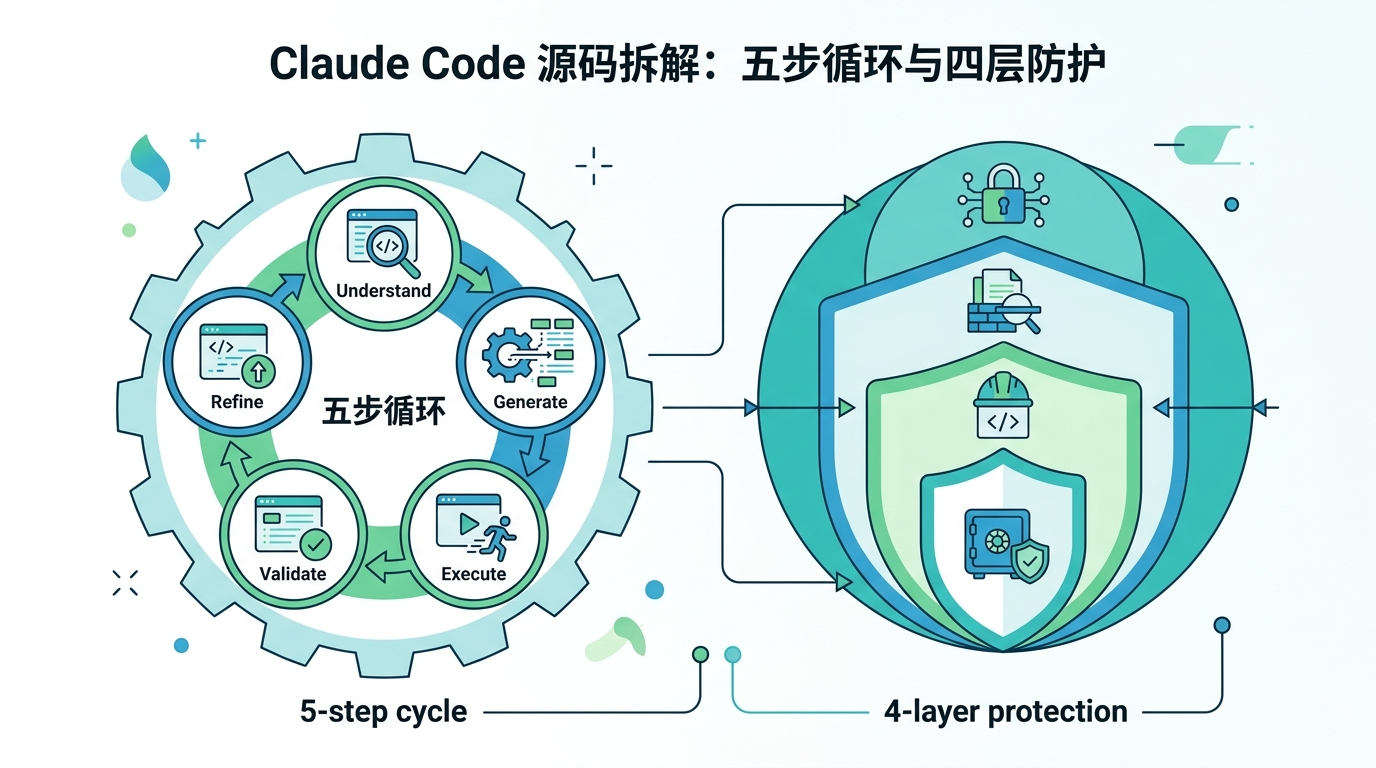
Claude Code 源码拆解:五步循环与四层防护
从源码看Claude Code:五步Agent循环、四层安全防线、三层Agent架构与记忆系统,连Capybara代号都藏不住。
Claude Code 的源码分析最近很火,因为它把一个看起来“会写代码的聊天工具”拆成了可观察、可推理的工程系统。文章里提到的几个数字很扎眼:五步 Agentic Loop、四层安全防御、三层 Agent 架构,再加上上下文压缩和记忆系统,这套设计明显不是简单把大模型接到终端上就完事。
如果你平时只把 Claude Code 当成一个命令行里的 AI 编程助手,那这次的源码视角会让人重新理解它。它更像一个围绕模型、工具、权限、记忆和反馈回路搭起来的工作流引擎,而模型只是其中最显眼的一层。对开发者来说,这种拆解价值很高,因为它能直接回答一个问题:为什么同样是“让 AI 改代码”,有的产品只能聊,有的产品却能持续执行任务。
先看整体:它不是单轮对话,而是循环系统
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
文章对 Claude Code 的第一层拆解,是把它从“聊天界面”拉回到工程结构。它的核心不是一次性回答,而是一个持续迭代的执行循环:读取任务、规划动作、调用工具、检查结果、再决定下一步。这个循环让它更接近一个自动化执行器,而不是传统的问答机器人。
这种设计的意义很直接。代码修改这件事本来就不是单轮问题,尤其当任务涉及多个文件、依赖关系、测试验证和回滚判断时,模型需要不断观察环境变化。Claude Code 的源码里暴露出的工作方式,说明 Anthropic 在产品定义上已经默认了“长任务”场景,而不是把 AI 当成一次性建议生成器。
从开发体验看,这种结构也解释了为什么 Claude Code 在真实项目里会比纯聊天式助手更像“半自动同事”。它会试着保持目标不变,同时根据工具输出调整下一步动作。对前端、后端、脚本修复、测试补全这些任务来说,这种方式比单次生成更接近人类协作流程。
- 任务执行是循环式的,不是单轮生成
- 工具调用和结果检查是流程的一部分
- 适合多文件、多步骤、可验证的代码任务
- 产品目标更接近自动执行,而非纯问答
五步 Agentic Loop:它怎么把任务跑完
文章提到的“五步流水线”是理解 Claude Code 的关键。虽然具体实现会随着版本变化,但这个结构本身已经很能说明问题:输入任务后,系统先做意图整理,再制定行动计划,接着调用外部工具,然后读取反馈,最后决定继续、修正还是结束。这个顺序把模型的“思考”拆成了可控阶段。
这类设计的好处是可观测性更强。模型并不是在黑箱里直接吐出最终答案,而是通过中间状态逐步逼近结果。对工程团队来说,这意味着更容易定位失败点:是计划错了,工具没返回,还是结果验证没通过。相比纯文本生成,这种分层处理更适合真实开发环境。
文章还提到了一些源码里能看到的隐藏信息,比如 Claude 系列内部的模型代号线索,以及类似 Undercover 这样的内部模式名。虽然这些彩蛋不会直接改变功能,但它们说明 Claude Code 的内部工程并不“轻”,而是已经有了多个围绕任务执行、身份切换和安全控制的子系统。
“The most important thing you can do is to make sure you have the right problem and the right solution.” — Dario Amodei, Anthropic co-founder and CEO, in his 2023 TED talk.
这句话放到 Claude Code 身上很贴切。它不是在炫技式地展示模型会写多少代码,而是在回答一个更实际的问题:怎样把“写代码”这个问题定义对,才能让模型在真实工程里持续产出可用结果。
上下文压缩与记忆:长任务能跑多久,靠什么撑住
长上下文是很多 AI 编程工具的痛点。任务一旦拖长,历史消息会迅速膨胀,模型注意力被稀释,最后就会出现前后矛盾、忘记约束、重复改错等问题。文章里的源码分析指出,Claude Code 在上下文管理上用了压缩和记忆机制来缓解这个问题。
这类机制的价值不在于“记住更多”,而在于“保留更有用的部分”。系统会把早期信息中和当前任务关系不大的细节压缩掉,同时保留目标、约束、已完成动作和关键结果。对一个正在修改大型仓库的 Agent 来说,这比简单堆长上下文更实用,因为真正重要的是状态连续性。
文章还提到记忆系统有更深的层次,不只是临时缓存,而是会影响后续任务的执行偏好。这个方向很值得关注,因为它意味着 Claude Code 不只是会“读当前对话”,还会把过去的任务经验转成一种可复用的工作上下文。对于经常处理同类项目的人来说,这种能力会直接影响效率。
- 上下文压缩减少无关历史信息
- 保留任务目标、约束和关键结果
- 记忆系统影响后续任务偏好
- 更适合长时间、多轮代码修改
四层安全防线:它为什么敢直接碰代码库
Claude Code 之所以能进入真实开发流程,安全设计是绕不开的话题。文章提到它有四层纵深防御,这个说法很符合一个能执行工具操作的 Agent 的现实需求:模型能想,不等于模型能做;能做,也不等于每一步都能做。
第一层通常是任务边界,限制模型处理什么内容;第二层是工具权限,决定它能不能读写文件、执行命令或访问网络;第三层是行为检查,用来拦住明显危险的操作;第四层则更像事后审计和反馈闭环,确保异常行为能被记录和追踪。这样的分层并不花哨,但它决定了 Agent 能不能在企业环境里落地。
Anthropic 一直强调安全与可控性,这一点在 Anthropic Research 的公开材料里也能看到。Claude Code 的源码解读把这种理念具体化了:真正能跑进终端、读写仓库、执行测试的 AI,必须有多道闸门,而不是只靠模型自己“自觉”。
- 任务边界限制可处理内容
- 工具权限控制读写与执行能力
- 行为检查拦截高风险操作
- 审计反馈记录异常与回退路径
和其他编程助手比,它强在哪
把 Claude Code 和其他编程助手放在一起看,最明显的差别不是“会不会写代码”,而是“会不会稳定完成任务”。像 OpenAI Codex、GitHub Copilot 这类产品更常见的形态,是在编辑器里补全、建议、生成片段;而 Claude Code 更偏向直接驱动任务执行。
这种差异会体现在几个很现实的指标上。第一是任务粒度:Copilot 更擅长局部补全,Claude Code 更适合跨文件修改。第二是执行闭环:前者常常停在建议层,后者会追着结果往下走。第三是上下文组织:Claude Code 更强调长期状态维护,这让它在复杂仓库里更像一个持续工作的代理。
当然,这并不意味着 Claude Code 在所有场景里都更优。对于只想补一行代码、写一个函数签名、快速生成注释的人来说,轻量编辑器插件可能更顺手。但如果任务是“读懂项目、改完逻辑、跑测试、修到通过”,Claude Code 这种 Agent 化设计就更有优势。
- Copilot 更偏局部补全与提示
- Codex 更常见于生成与执行结合的工作流
- Claude Code 更强调跨文件任务完成
- 长任务场景里,闭环能力比单次生成更重要
最后看一个问题:它会把编程助手带到哪一步
这篇源码解析最有价值的地方,不是告诉你 Claude Code 有多少内部彩蛋,而是让人看到一个趋势:编程助手正在从“帮你写”转向“帮你做完”。五步循环、上下文压缩、记忆系统、四层安全防线,这些模块拼起来之后,AI 编程工具就不再只是 IDE 里的配角,而是开始承担更完整的任务执行责任。
我的判断很直接:接下来一段时间,真正拉开差距的不会是“谁生成的代码更像人”,而是谁能在更少人工干预下,把一个真实任务从需求推进到可验证结果。下一次评估 Claude Code 或类似产品时,别只看 demo 里写了多少行代码,先问三个问题:它能不能记住目标,能不能处理失败,能不能在权限内安全收尾?
如果这三个问题有两个以上答得漂亮,那它就不只是一个编程助手了,而是一个能进开发流程的执行系统。
// Related Articles
- [TOOLS]
Why Gemini API pricing is cheaper than it looks
- [TOOLS]
Why VidHub 会员互通不是“买一次全设备通用”
- [TOOLS]
Why Bun’s Zig-to-Rust experiment is the right move
- [TOOLS]
Why OpenAI API pricing is a product strategy, not a footnote
- [TOOLS]
Why Claude Code’s prompt design beats IDE copilots
- [TOOLS]
Why Databricks Model Serving is the right default for production infe…