資料密集系統怎麼撐住流量
分割、一致性、可觀測性,決定資料密集系統能不能在高流量下維持速度與穩定。這篇用台灣開發者看得懂的方式,拆解《Designing Data-Intensive Applications》的核心觀念。
當系統資料量破百萬筆,問題就不是「能不能存」。
真正麻煩的是,資料放哪裡、怎麼流動、哪台機器先掛。
這就是 Designing Data-Intensive Applications 這本書在講的事。說真的,它幾乎是做後端的人必看清單。
很多團隊一開始都很天真。先上單一資料庫,先撐住流量再說。等到 QPS 上來、查詢變複雜、延遲開始飄,才發現架構早就埋雷。
什麼叫資料密集系統
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
資料密集系統,重點不是 CPU 多快。重點是資料怎麼存、怎麼讀、怎麼搬。推薦系統、金流平台、分析儀表板、電商後台,都算這一類。
這類系統常常要同時扛高吞吐和低延遲。你可能每秒要處理幾千筆請求,還要讓查詢維持在 100ms 內。這不是靠一台大機器就能解決。
真正的變化,通常從規模開始。資料量一大,單機資料庫就會開始喘。這時候就得切讀寫、拆分資料、加 cache、加 queue、加 replica。
Martin Kleppmann 在談分散式系統時說過一句很實在的話:
“There are no perfect solutions, only trade-offs.”這句話很適合拿來當資料系統的座右銘。因為你選的每個方案,都在換東西。
- 資料量常常會到 TB,甚至 PB。
- 讀寫吞吐都要顧,不是只看一邊。
- 低延遲要在高流量下也維持住。
- 故障不是例外,是日常。
分割資料,才知道系統會不會失衡
Partitioning 是第一個常見的擴充手段。簡單講,就是把資料切到多台機器上。切得好,負載平均。切不好,某幾個 shard 會熱到冒煙。
常見方法有三種。Range partitioning 適合時間序列或有順序的資料。Hash partitioning 適合想平均分散資料。Directory partitioning 則適合路由邏輯比較複雜的場景。
問題是,理論上平均,不代表實際上平均。某個大客戶如果流量特別兇,照樣能把單一 shard 打爆。時間區間切法也一樣,最近資料常常最熱,結果寫入全擠在同一區。
講白了,分割策略不是看哪個最漂亮。要看你的流量長什麼樣子。這才是工程,不是背名詞。
- Range partitioning:適合時間序列、日誌、事件資料。
- Hash partitioning:適合平均分散,減少單點壓力。
- Directory partitioning:適合需要額外中介資料的路由。
- Hotspot avoidance:分割設計成敗的核心。
一致性不是信仰,是產品決策
分散式系統最難的地方,常常不是速度,而是資料要多一致。強一致性讓人比較好理解。你看到的就是最新狀態。但它也可能在網路出問題時,拖低可用性。
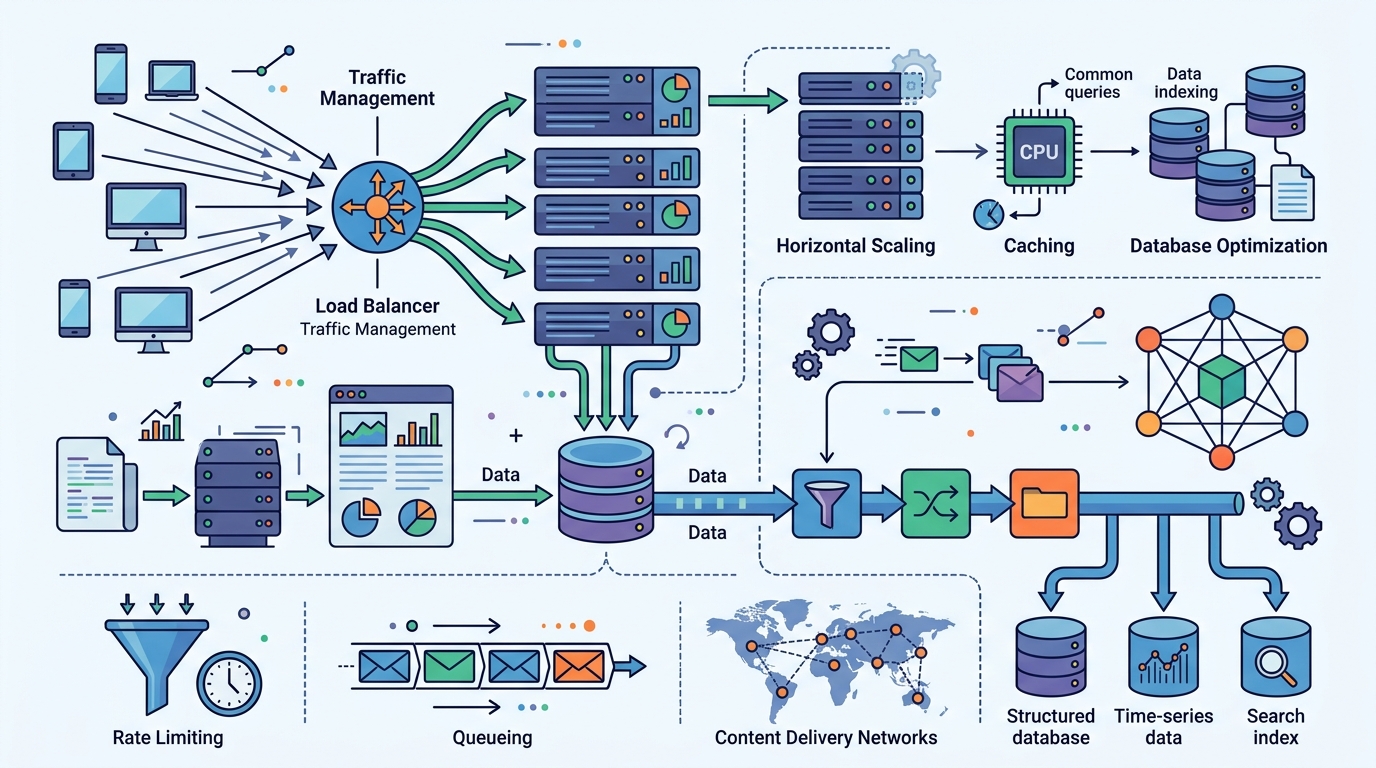
相反地,最終一致性接受短暫不一致。副本之間可以晚一點同步。這種設計常常讓系統在局部故障時還能繼續跑。
這裡就會碰到 CAP theorem。簡單說,當網路分割發生時,系統沒辦法同時把一致性和可用性都拉滿。你只能選一邊先保。
Eric Brewer 在談 CAP 時說得很直接:
“The CAP theorem says that, in the presence of a network partition, one has to choose between consistency and availability.”這句話很殘酷,但很真實。因為產品需求,最後一定會逼你選。
像銀行帳務,強一致性通常值得。像社群動態牆,按讚數晚幾秒更新,很多人根本不在意。重點是你要知道,哪種錯誤會讓使用者真的炸掉。
資料怎麼跑,數字最誠實
架構定下來後,下一個問題就是資料怎麼流。這通常會牽涉到關聯式資料庫、文件型資料庫、key-value 系統、串流平台。很多團隊也會同時混用,不會只靠一種工具。
例如,交易資料可能放在 PostgreSQL。熱資料可能丟給 Redis。事件管線則常用 Apache Kafka。如果你要的是長時間保留訊息和多租戶串流,Apache Pulsar 也是常見選項。
這些工具沒有誰一定最好。MongoDB 很適合文件型資料。Apache Cassandra 則偏向高寫入、可水平擴充的場景。選錯工具,後面就是一堆補洞工。
真正該盯的數字也很實際。p95 latency、error rate、replication lag、throughput,這些才是系統健康度。你如果看到 p95 從 80ms 飆到 400ms,使用者一定有感。replication lag 如果掉進幾秒,dashboard 就會開始騙人。
- p95 latency:看大多數使用者體感。
- Replication lag:看副本有沒有跟上。
- Throughput:看高峰期能不能扛住。
- Backpressure:看下游慢時會不會整串塞住。
可觀測性,才是架構的照妖鏡
很多系統設計圖看起來都很美。真的上線後,才知道哪個 shard 熱、哪個 queue 卡、哪個服務在偷吃資源。這時候沒有可觀測性,等於你在摸黑救火。
所以 logging、metrics、tracing 不是附加功能。它們是資料系統的基本裝備。沒有這些,你連問題在哪都不知道,更別說修。
安全性也要一起看。資料系統通常握著最敏感的東西。傳輸加密、靜態加密、權限控管、稽核紀錄,這些都不能省。如果碰到個資、金流、醫療資料,法規壓力會直接進設計圖。
我覺得很多團隊犯的錯,是把觀測和安全分開看。其實兩者是同一件事。你如果說不出資料去哪了,也很難說自己保得住。
為什麼這本書現在還有用
現在的資料系統,比十年前更雜。Serverless 會吃事件流。AI pipeline 會直接接 operational data。各團隊還想要更高的自治權。聽起來花俏,但底層問題其實還是那幾個。
你還是得面對分割、複寫、延遲、故障、回復。這些東西沒有因為雲端或 LLM 就消失。只是換了更多工具包裝。
這也是為什麼 Martin Kleppmann 的個人網站 到現在還常被工程師拿來當參考。因為他講的不是某個框架,而是系統背後的物理限制。
講白了,硬體可以加,架構債還是會算利息。你如果不先想 failure mode,後面就只能靠值班人員撐。
競品怎麼看,差異其實很現實
如果把資料系統工具放在一起看,差異會很直接。不是誰最潮,而是誰最適合你的流量型態。這也是很多團隊踩坑的地方,因為他們先選工具,再找問題。
以資料庫來說,PostgreSQL 適合交易和複雜查詢。MongoDB 適合文件結構變動快的資料。Cassandra 比較偏高寫入和跨機房場景。
以串流來說,Kafka 生態成熟,很多公司都在用。Pulsar 的架構在多租戶和訊息保留上也有自己的強項。差別不是紙上規格,而是你的團隊要不要自己養運維複雜度。
- PostgreSQL:交易穩,查詢能力強。
- MongoDB:文件模型彈性高。
- Cassandra:適合高寫入與水平擴充。
- Kafka:事件流生態完整,社群大。
這些原則,跟台灣團隊很有關
台灣很多新創和企業團隊,都會先碰到一個現實問題。人少,系統卻要撐成長。這時候最容易發生的事,就是先把功能做出來,架構之後再補。
問題是,資料系統的坑常常不能後補。你今天把資料模型設錯,明天就會在 migration、replica、cache invalidation 上還債。這些帳,最後都會回到工程時間。
所以我會建議,先問三件事。流量長什麼樣?資料錯多久可以接受?哪個故障最不能發生?這三題答完,很多架構選擇就會清楚很多。
如果你現在正在做新平台,我的預測很直接:接下來一年,懂 partitioning、consistency、observability 的團隊,會比只會加機器的團隊少踩很多雷。你不一定要一開始就做得很大,但你一定要先想清楚,哪裡會先壞。