Designing Data-Intensive Apps for Scale and Reliability
Partitioning, consistency, and observability decide whether data-heavy systems stay fast under load or fall over when traffic spikes.

When a system grows past a few million rows, the problem is no longer just “store the data.” It becomes about where that data lives, how it moves, and what happens when one node slows down. That is the core challenge behind Designing Data-Intensive Applications, the book that many engineers keep nearby when data volume, latency, and failure modes start to matter at the same time.
The practical lesson is simple: once you spread data across machines, every choice has a cost. Partitioning can smooth load or create hot spots. Strong consistency can simplify reasoning or cut availability during network trouble. The systems that age well are the ones designed with those trade-offs in mind from the start.
What “data-intensive” really means
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
A data-intensive application is a system where storage, retrieval, and movement of data matter more than raw CPU speed. Think recommendation engines, financial platforms, analytics dashboards, and large e-commerce back ends. These systems often need to serve thousands of requests per second while keeping response times low and data correct enough for users to trust.

The scale is usually what changes the design. A small app can keep everything in one database and still feel fine. Once traffic, data size, or query complexity grows, the architecture starts to strain. That is when engineers begin separating reads from writes, splitting datasets across nodes, and adding layers such as caches, queues, and replicas.
Martin Kleppmann, who wrote the book that shaped much of this discussion, captured the mindset well in a talk about distributed systems: “There are no perfect solutions, only trade-offs.” That line matters here because data systems are built from trade-offs, not ideals.
- Large datasets often reach terabytes or petabytes.
- High throughput matters for both reads and writes.
- Low latency is expected even when queries are complex.
- Failures are normal, so recovery has to be part of the design.
Partitioning decides whether a system stays balanced
Partitioning is one of the first scaling tools engineers reach for because it splits data across multiple machines. Done well, it spreads load evenly and avoids a single database becoming a bottleneck. Done badly, it creates hot partitions that get hammered while other nodes sit underused.
There are a few common strategies, and each one fits a different kind of workload. Range partitioning works well when data has a natural order, such as timestamps. Hash partitioning spreads records more evenly when you care about uniform distribution. Directory-based partitioning helps when the routing logic is more complex and cannot be reduced to a simple key.
The choice matters because partitioning affects performance, failover behavior, and operational complexity all at once. A hash partitioning scheme may look elegant on paper, but if one customer generates far more traffic than the others, that customer can still create a hot shard. Range partitioning can make time-based queries fast, yet it often concentrates recent writes into the same partition.
For teams building systems at scale, the question is not “Which partitioning method is best?” The real question is “Which one matches the shape of our traffic?”
- Range partitioning: good for ordered access patterns and time-series data.
- Hash partitioning: good for spreading records evenly across nodes.
- Directory partitioning: good when routing depends on richer metadata.
- Hotspot avoidance: the main reason partitioning succeeds or fails.
Consistency is a design choice, not a moral one
Distributed systems force a decision that small systems can ignore: how consistent does the data need to be, and how quickly? Strong consistency gives a clean mental model because users see the same state everywhere, but it can reduce availability when the network misbehaves. Eventual consistency accepts temporary divergence and lets replicas converge later, which often keeps the system usable during partial outages.
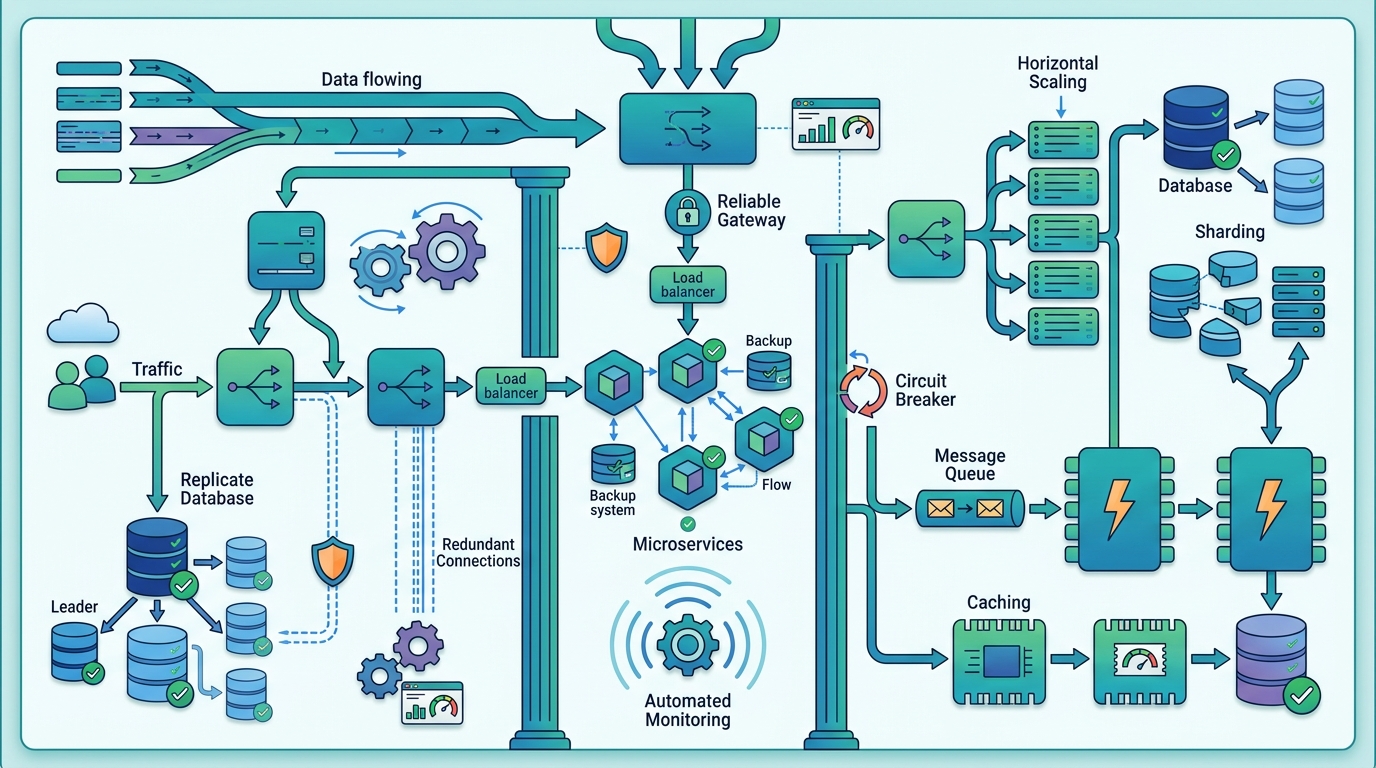
This is where the CAP theorem enters the conversation. In plain terms, when a distributed system faces a network partition, it cannot fully guarantee both consistency and availability at the same time. That does not mean one option is always better. It means the product requirements decide the trade-off.
In a banking ledger, strong consistency is often worth the extra cost. In a social feed, a brief delay in updating like counts or follower graphs may be acceptable if the service stays online. The right answer depends on user expectations, regulatory pressure, and how bad stale data would be in practice.
“The CAP theorem says that, in the presence of a network partition, one has to choose between consistency and availability.” — Eric Brewer
That quote is useful because it strips the problem down to its actual shape. Engineers do not get to avoid the trade-off. They get to decide where to place it.
Storage, streaming, and the numbers that matter
Once a system is partitioned and the consistency model is set, the next question is how data moves through the stack. That usually means choosing between relational databases, document stores, key-value systems, and distributed analytics engines. It also means deciding how much work happens in real time and how much can wait for batch jobs.
For many teams, the best architecture mixes several tools. A transactional database may handle writes, a cache may absorb repeated reads, and a stream processor may update aggregates as events arrive. Apache Kafka is a common choice for event pipelines, while Apache Pulsar is another option for streaming systems that need durable message handling. On the storage side, MongoDB and Apache Cassandra solve different problems, which is exactly the point.
The performance numbers that matter are usually boring but decisive: p95 latency, error rate, replication lag, and throughput under peak load. If p95 jumps from 80 ms to 400 ms during traffic spikes, users feel it immediately. If replication lag climbs into seconds, read replicas start serving stale data. If backpressure is missing, one slow downstream service can trigger a pileup across the pipeline.
- Redis is often used to cut database load for hot reads.
- PostgreSQL remains a strong fit for transactional data and complex joins.
- Replication lag above a few seconds can break user trust in dashboards and feeds.
- Backpressure prevents one overloaded service from dragging down the rest of the system.
Observability is what keeps the architecture honest
Even a well-designed system will fail if nobody can see what it is doing. That is why logging, metrics, and tracing matter so much in data-heavy applications. They show where latency is rising, which partitions are overloaded, and whether a recent deploy changed the shape of traffic.
In practice, observability is what turns architecture from theory into something you can operate. A clean diagram does not help when one shard is hot and another is idle. Metrics do. Traces do. Alerts do, if they are tuned to catch real problems instead of noise.
Security also belongs in this layer, because data systems usually hold the most sensitive parts of a product. Encryption in transit and at rest, access controls, and audit trails are basic requirements, not optional extras. If the system handles personal, financial, or health data, compliance rules such as GDPR, HIPAA, or CCPA shape the design from day one.
The strongest teams treat observability and security as part of the same operating discipline. If you cannot explain where the data went, you probably cannot protect it either.
Why this matters for the next wave of systems
The next generation of data-heavy software will keep pushing the same fundamentals in new directions. Serverless functions will process more events, machine learning pipelines will sit closer to operational data, and domain teams will want more ownership over their own datasets. The ideas behind Designing Data-Intensive Applications still apply because the physics of distributed systems have not changed.
My prediction is straightforward: teams that understand partitioning, consistency, and observability will ship faster than teams that keep adding hardware and hoping for the best. The next hard question is not whether your stack can store more data. It is whether it can survive a bad shard, a noisy neighbor, or a network split without turning into a support fire drill.
If you are designing a new data platform this year, start with the traffic pattern, then the failure modes, then the consistency model. That order will save you from a lot of expensive rewrites later.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production