Why Distributed Systems Feel So Weird
AWS explains why distributed systems break simple assumptions: every request crosses fault domains, and each step can fail independently.
Amazon had so few servers in 1999 that engineers named them things like “fishy” and “online-01.” That sounds quaint now, but the hard part was already there: distributed computing was messy then, and it is still messy today. In AWS’s Builders’ Library article, the core warning is simple: once a system spans machines, failures stop behaving like isolated bugs and start behaving like a daily operating condition.
The article makes a point that still catches teams off guard. A request that feels like one method call on a single machine turns into a chain of network sends, deliveries, validations, state updates, and replies. Each step can fail on its own. That is why distributed systems feel so strange compared with normal application code.
If you have ever debugged a service that worked perfectly in unit tests and then fell apart under real traffic, this is the reason. The network does not share fate with your process, and that changes everything.
Three kinds of distributed systems, three very different pain levels
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Amazon breaks distributed systems into three broad groups: offline systems, soft real-time systems, and hard real-time systems. The first group gets the easiest life. Batch jobs, rendering farms, and large analytics clusters can tolerate delays and retries because nobody is waiting on a live response.
Soft real-time systems sit in the middle. They need to keep producing results, but they have breathing room. A search index builder can be offline for minutes or hours in some cases, and EC2 credential propagation has a window measured in hours because old credentials do not expire instantly.
Hard real-time systems are where the pain concentrates. These are request/reply services where a user, payment flow, or API caller is waiting right now. That includes front-end web servers, order pipelines, credit card transactions, telephony, and most AWS APIs.
- Offline systems: batch processing, big data analysis, movie rendering, protein folding
- Soft real-time systems: search index builders, impaired-server detectors, EC2 credential updates
- Hard real-time systems: web requests, order processing, payment authorization, live APIs
The difference matters because the failure budget changes. Offline systems can retry quietly. Hard real-time systems need to answer fast, and they need to do it while the network, the remote machine, and the client all keep their own failure modes.
That is why distributed systems are not just “single-machine programs with more servers.” The operating assumptions change as soon as a request has to cross a fault boundary.
The network turns one call into eight steps
The article’s best mental model is the request/reply cycle. On a single machine, a function call looks simple. Across a network, one round trip breaks into eight steps: post the request, deliver it, validate it, update server state, post the reply, deliver the reply, validate it, and update client state.
That list is long for a reason. Each step can fail independently, and each failure creates a different recovery problem. A request may never leave the client. It may reach the server and then get lost before the reply comes back. The reply may arrive but fail validation because of a version mismatch or corrupted data.
To make the point concrete, the article imagines a networked Pac-Man game where the board lives on another server. A single line like board.find("pacman") becomes a remote operation with transport, serialization, validation, and timeout concerns layered underneath it.
“The network enables sending messages from one fault domain to another.” — Amazon Builders’ Library
That sentence is the heart of the piece. Once you send a message across a fault boundary, you stop living in the tidy world of in-process calls. You are now depending on two machines, the network between them, and the timing behavior of both sides.
It also explains why distributed bugs are so annoying to reproduce. The code may be correct, but the timing may be wrong. Or the timing may be fine, but the machine may fail after receiving a request and before replying. Or the reply may be valid but arrive too late to matter.
Failure is normal, and “unknown” failure is worse
Amazon’s article spends a lot of time on failure because distributed systems force you to assume it. On one machine, if the CPU fries or the kernel panics, the whole box is probably gone. That is fate sharing: one failure takes the whole unit with it, which actually simplifies reasoning.
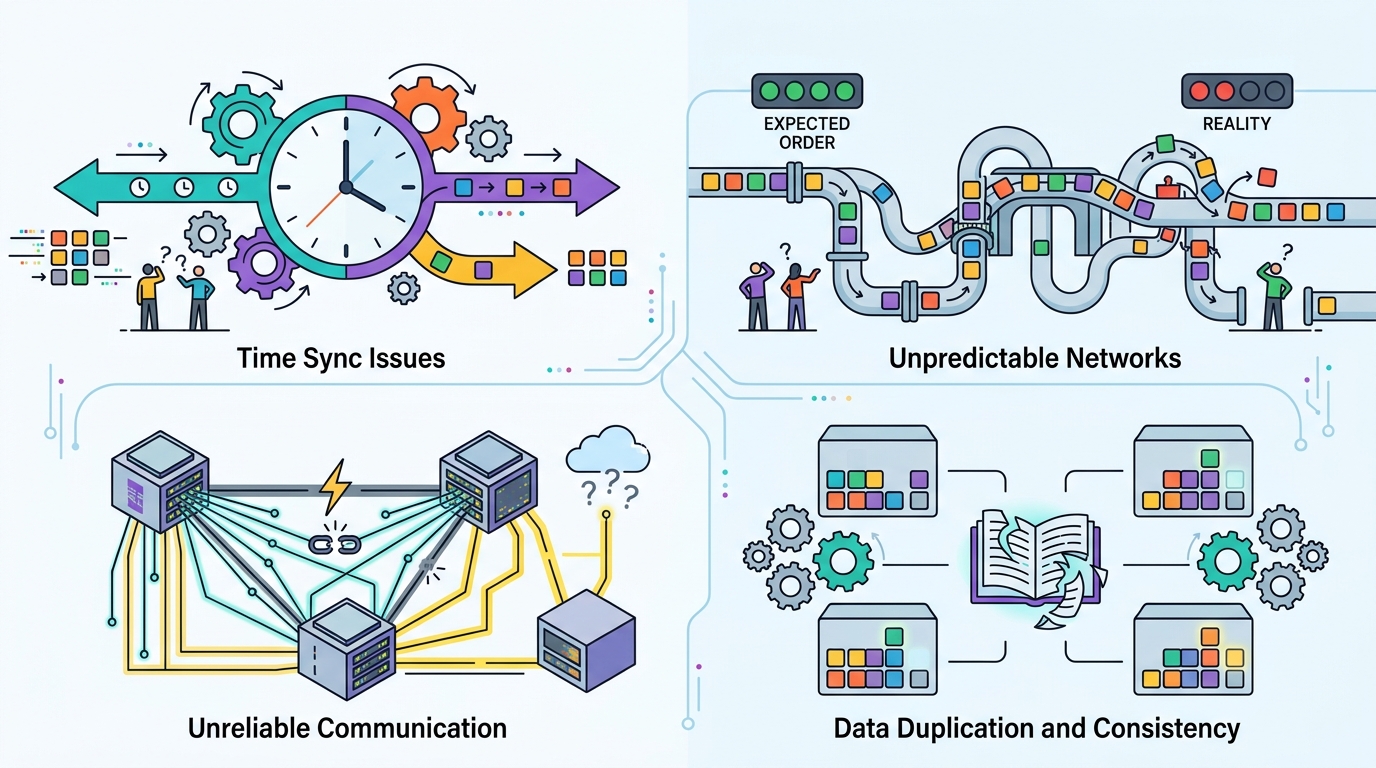
Across machines, fate sharing disappears. The client can keep running while the server is dead. The server can receive a request and crash before replying. The network can drop packets while both endpoints look healthy. That means code has to treat every step as a possible failure point.
Here is the failure checklist the article walks through:
- Request posting can fail if the network is down or the server rejects the connection
- Request delivery can fail if the server crashes after receiving the message
- Request validation can fail because of bad data, incompatible versions, or corrupted packets
- Server state updates can fail because storage or memory operations break
- Reply posting can fail even after the server has processed the request
- Reply delivery can fail after the response leaves the server
- Reply validation can fail on the client because the data is invalid or unexpected
- Client state updates can fail after the reply is received
This is why distributed systems teams obsess over timeouts, retries, idempotency, and versioning. Those are not optional extras. They are the tools that keep an API from turning into a pile of ambiguous partial failures.
It also explains why “unknown unknowns” matter so much. You can write tests for a dropped packet or a refused connection. It is much harder to test the timing edge case where a server processed a request, died before replying, and then got retried by the client a second later.
How AWS compares the hard cases to the easy ones
The article’s comparison between single-machine code and networked code is useful because it shows how quickly complexity grows. A local call like board.find("pacman") has a small set of failure modes. A remote call has to account for transport, serialization, validation, state mutation, and timeout behavior on both sides.
That is why distributed systems engineering often feels less like application programming and more like designing for adversarial conditions. You are planning for partial success, duplicate delivery, stale state, and delayed responses all at once.
- Single-machine call: one fault domain, one process, one memory space
- Network call: at least two fault domains, plus the network in between
- Single-machine failure: usually ends the whole process
- Network failure: one side may keep running while the other side fails or stalls
- Offline workloads: can absorb long delays and retries
- Hard real-time workloads: need quick answers even when parts of the system misbehave
That comparison is also why a lot of teams underestimate distributed systems at first. The code looks familiar. The deployment model looks familiar. The runtime behavior is anything but familiar once packets, timeouts, retries, and retries of retries enter the picture.
One useful way to read this article is as a warning against local thinking. A method call on your laptop and a request between two AWS services may look similar in code, but they live in very different failure environments.
What this means for teams building real services
The strongest takeaway from AWS’s write-up is that distributed systems are defined by their failure modes, not by their diagrams. If your service crosses machines, you should assume the network will lie to you sometimes, the remote side will disappear sometimes, and your own process will sometimes get an answer too late to use it.
That is why production systems need explicit handling for retries, deduplication, timeouts, and state reconciliation. It is also why teams that build APIs, payment systems, or control planes spend so much time on boring-looking infrastructure details. The boring parts are where correctness lives.
For readers who want the next layer of detail, OraCore’s related coverage on timeouts and retries in distributed services pairs well with this piece. The same goes for idempotency in API design, because once a request can fail halfway through, duplicate work becomes a real design problem.
My prediction is simple: as systems get more distributed, the teams that win will be the ones that treat failure as a normal input, not an exception. If you are designing a service today, ask one question before anything else: what exactly happens when the request reaches the server, but the reply never makes it back?
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production