In-Place TTT 讓 LLM 推理時自適應
這篇論文把 test-time training 做成可直接嵌入 LLM 的推理更新機制,讓模型在長上下文下用 fast weights 即時適應,不必整個重訓。

大型語言模型通常是先訓練、再部署,之後就幾乎固定不動。這種流程在世界變化慢的情境還行,但一旦資料一直進來、上下文越拉越長,模型就會開始顯得不夠靈活。In-Place Test-Time Training 想解的,就是這個「模型太靜態」的問題。
這篇論文的方向很直接:不要整個模型重訓,也不要把推理變成一套很重的額外流程,而是只在推理時更新一小部分參數。換句話說,它不是要把 LLM 變成另一種模型,而是想把 test-time training 變成一種能塞進現有 LLM 堆疊的工程做法。
它在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
作者先點出今天 LLM 的基本限制:模型訓練完之後就固定了。這在任務分佈穩定時沒什麼問題,但如果模型要持續吸收新資訊,或是要處理超長上下文,固定權重就很難跟上輸入流裡的變化。

Test-Time Training,簡稱 TTT,原本就是想補這個洞。做法是讓模型在推理時更新一部分參數,讓它邊用邊調整。不過論文認為,現有 LLM 生態要把這件事做起來,會卡在三個地方:架構不相容、計算效率不夠、以及 fast-weight 的目標函數跟語言模型真正的任務不太對齊。
最後這點很關鍵。語言模型的核心工作是預測下一個 token,不是做一個抽象的重建任務。如果你用的自適應目標只是泛用 reconstruction,模型可能學到一些對原任務不夠直接的東西。這篇論文的主張是:如果要讓推理時更新真的對 LLM 有效,訓練訊號就要貼近 next-token prediction。
In-Place TTT 到底怎麼做
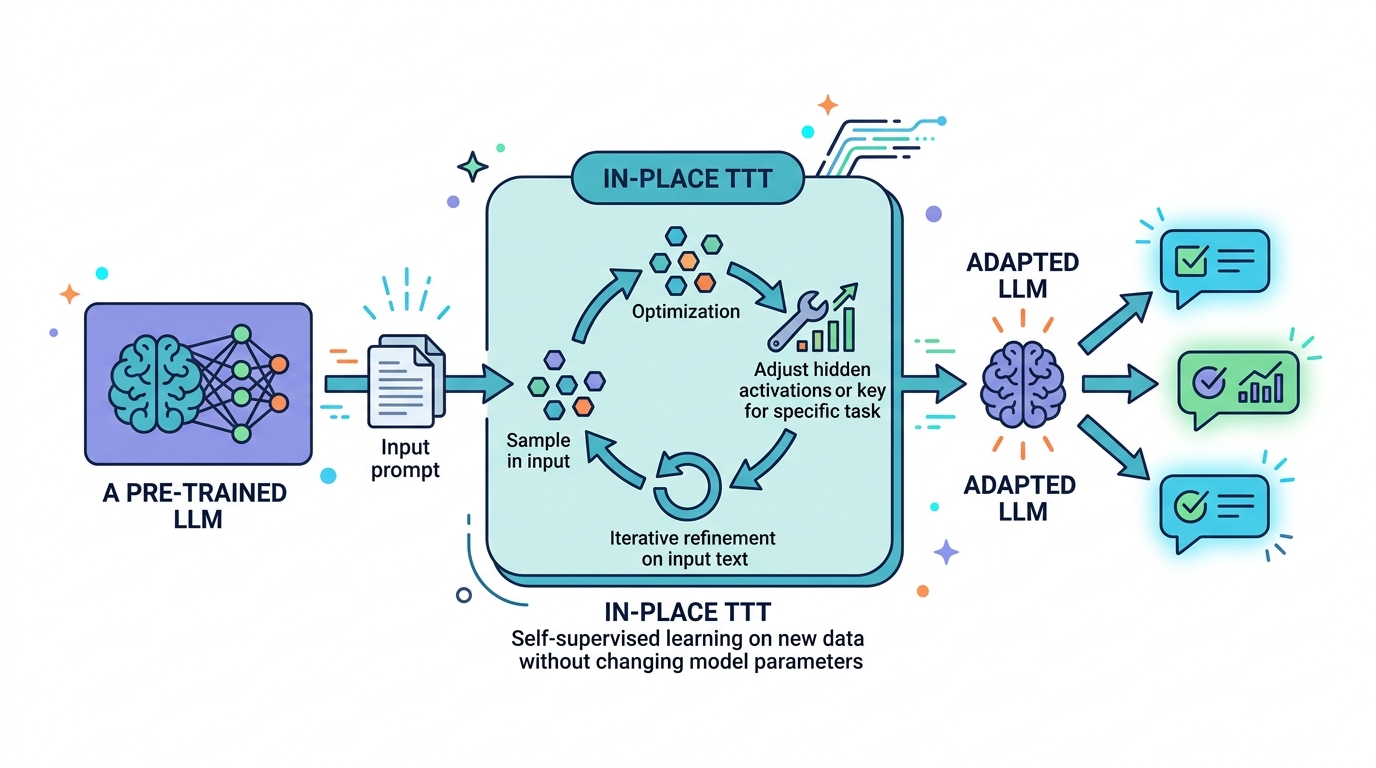
In-Place TTT 把標準 MLP block 裡的最後投影矩陣,當成推理時可以改動的部分。論文把這些可調整的參數稱為 fast weights。模型其他部分維持不變,所以它不是要你重建整個架構,而是把更新範圍縮到一個既有元件上。
這種設計的目的很實際。test-time training 最大的落地障礙之一,就是只要方法需要特殊架構,採用成本就會飆高。作者選擇一個常見 LLM block 裡本來就有的部件,等於是在說:這不是只適合研究 prototype 的技巧,而是希望能直接接上現有模型。
第二個重點是目標函數。論文沒有用泛用的重建損失,而是改成跟 next-token prediction 對齊的目標。意思很簡單:模型在推理時不是學著「把輸入重做一次」,而是學著用跟語言建模一致的方式去調整自己。這讓 fast weights 的更新方向更貼近真正的生成任務。
第三個重點是更新方式。摘要提到它用了 chunk-wise update,目的在於讓方法更有效率,也能和 context parallelism 相容。對工程端來說,這通常就是能不能把方法放進長上下文推理管線的分水嶺。理論上可行不夠,還要能在實際吞吐和記憶體配置下跑得動。
- 可更新部位:MLP block 的最後投影矩陣
- 更新參數:fast weights
- 訓練訊號:對齊 next-token prediction
- 更新方式:chunk-wise,強調可擴展性
- 設計目標:盡量做成可直接套用的增強,而不是重做架構
論文實際證明了什麼
摘要有給結果方向,但沒有公開完整 benchmark 細節。它只說,作為一種 in-place enhancement,這個方法能讓一個 4B 參數模型在最長可達 128k tokens 的上下文任務上取得更好的表現。這代表它主打的場景很明確:長上下文。
摘要也說,如果用這個框架從零開始 pretrain,模型會持續優於競爭性的 TTT 相關方法。這句話的訊號很強,表示作者不只想把它當成後訓練補丁,也想把它變成一種可用於預訓練的設計。
但要注意,摘要沒有列出任務名稱、分數、比較表,也沒有把「competitive TTT-related approaches」具體點名。所以就目前可見資訊來看,我們只能保守地說:這個方法在長上下文情境下看起來有效,而且相較相關 TTT 方法有優勢,但還不能單靠摘要量化它到底贏多少。
摘要還提到 ablation studies。這通常表示作者有拆解不同設計選項,觀察它們對結果的影響。雖然摘要沒有把 ablation 數字展開,但至少可以確認,這篇不是只丟一個方法名,而是有試著證明:為什麼要選這個 fast-weight 部位、為什麼要用這個目標、為什麼要做 chunk-wise update。
對開發者有什麼意義
如果你在做 LLM 系統,這篇最實際的吸引力是四個字:推理時適應。很多產品情境都不是靜態的。文件會更新、上下文會變長、使用者輸入會越來越依賴前文。若模型只能用訓練時的固定權重去面對這些變化,效果很容易卡住。
In-Place TTT 想提供的是一種折衷:不用全模型重訓,只更新少量參數;不用改整個架構,只動既有 MLP 裡的一小塊;不用把 adaptation objective 做成跟語言任務無關的東西,而是直接對齊 next-token prediction。這種思路很符合實務:改動小,才比較有機會被放進既有推理流程。
它也碰到一個很現實的系統問題:怎麼讓模型不只是「固定推理」,而是能在推理流程中持續吸收訊號,但又不要把 inference 變成一個完整 training job。論文強調與 context parallelism 相容,顯示作者有把長上下文吞吐和部署可行性放進考量。
不過,摘要也留下不少工程上很重要的空白。它沒有說更新步驟的額外計算成本是多少,沒有說 fast weights 在長時間推理下是否穩定,也沒有說哪些任務最適合這種自適應方式。摘要也沒交代是否會有 drift、忘記前文,或是更新太頻繁導致推理品質波動。
所以,這篇論文比較像是在提出一個「可落地的方向」,而不是已經把所有部署問題都解完。它的價值在於把 test-time training 從一個偏研究的概念,往 LLM 實作現場推了一步。
這篇文章可以怎麼看
如果把這篇論文濃縮成一句話,就是:讓 LLM 在推理時只改一小部分,而且改得要跟語言模型的任務一致。這聽起來不複雜,但對長上下文和持續變動的場景來說,可能很有用。
它提供了兩個重要訊號。第一,test-time training 不一定要靠大改架構才能做。第二,若要讓 inference-time adaptation 真正適合 LLM,目標函數不能亂選,必須跟 next-token prediction 對齊。這兩點都很工程導向。
但同時也要保持保守。摘要沒有公開完整 benchmark 細節,沒有給出明確數字對照,也沒有談到完整成本。對開發者來說,這表示它值得關注,但還不能只看摘要就判定它一定適合自己的系統。
總結來說,In-Place TTT 是一個很明確的嘗試:把 LLM 的適應能力往推理端搬,並且盡量不破壞既有架構。它的方向很符合長上下文時代的需求,也很符合想把模型放進真實產品流程的工程思維。