IPT 讓 VLM 更會想像隱藏空間
IPT 用中介感知 token 讓多模態模型學會推理看不到的空間結構,特別是在遮擋、視角切換與路徑追蹤上更準。
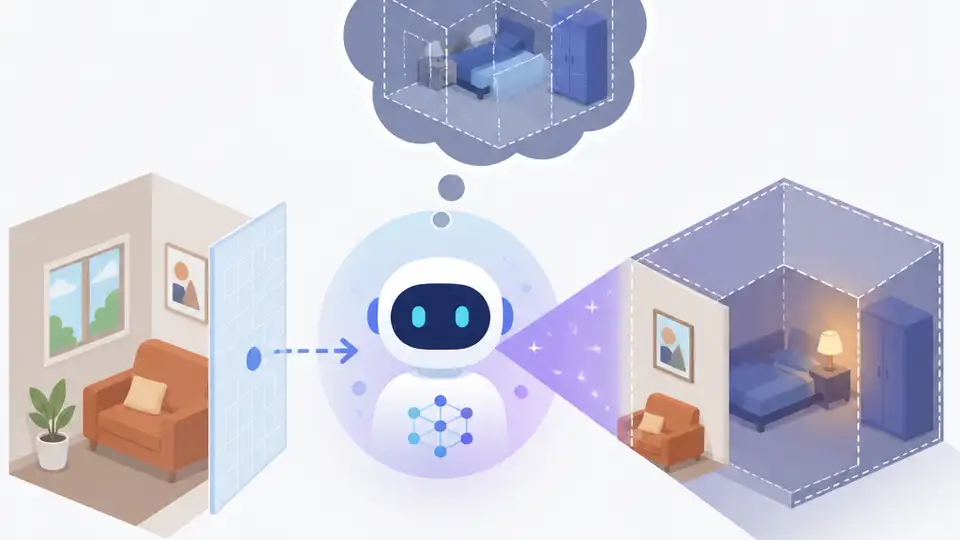
IPT 用中介感知 token 讓多模態模型學會推理看不到的空間結構,特別是在遮擋、視角切換與路徑追蹤上更準。
- 研究機構:arXiv 摘要未明確標註
- 核心數據:20K examples
- 突破點:中介空間 token
這篇論文在解的,不是一般看圖問答,而是更難的空間推理:當答案不在眼前、而是藏在遮擋後面、另一個視角裡,或需要先在腦中重建空間時,多模態模型到底能不能想對。作者把這種能力稱為 imaginative perception,也就是「想像式感知」。
對開發者來說,這不是小修小補。很多系統都能描述圖片裡看得到的東西,但一碰到地圖、房間、示意圖、機器人環境,或是需要推斷被擋住的路徑時,就開始亂掉。這篇研究就是在補這個洞。
這篇論文想補哪個洞
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
現有 vision-language model 很擅長辨識物件、回答一般視覺問題,但遇到「看不到」的資訊就容易卡住。摘要點出的痛點很明確:模型要推理的東西,可能是從另一個視角才看得到的內容,也可能是被遮住的空間結構,或是要把多個局部觀察拼成完整空間圖像。

這種問題的本質不是純語言。你不能只靠把圖片講成文字,再讓模型用文字一路猜下去。因為真正需要的是空間運算,不是敘事。作者認為,硬把這類任務塞進文字推理,會產生 modality mismatch,也就是輸入與推理形式不對位。
所以這篇論文的切入點很直接:與其逼模型用文字「講」出空間答案,不如訓練它先產生一個中介的感知表示,讓它先「想像」再回答。
IPT 到底怎麼做
核心方法叫 Imaginative Perception Tokens,簡稱 IPT。你可以把它理解成一組訓練時用的中介 token,專門用來表示模型在另一種空間配置下「應該看到什麼」。它不是最後答案,也不是自由發揮的解釋,而是一個要被監督的中間層。
重點在於,IPT 要保留和原始輸入的一致性。也就是說,模型不是隨便幻想,而是在觀測到的圖像基礎上,去外化它對隱藏空間的推理。這讓它和一般 chain-of-thought 不太一樣。後者偏向語言式推理;前者則是把空間想像變成可學習的中介表徵。
論文用三個任務來測這件事:Perspective Taking、Path Tracing、Multiview Counting。這三個任務分別對應換視角、追蹤被遮擋路徑,以及從多視角一致地計數。簡單說,就是在測模型能不能補出看不到的空間資訊。
- Perspective Taking:推斷另一視角會看到什麼。
- Path Tracing:在部分遮擋的空間裡找路徑。
- Multiview Counting:整合多視角,做一致計數。
為了支援這些任務,作者建立了大約 20K 筆例子,裡面包含 ground truth imaginations、答案,以及評估用的 benchmark。摘要沒有公開完整資料建構細節,所以我們只能確定它是任務導向、且有明確監督的資料集,而不是泛用的 caption 或 QA 混合資料。
這點很重要。因為 IPT 不是拿一堆通用資料硬灌,而是直接把「空間想像」變成訓練目標。從工程角度看,這代表它想修的是模型的中介表示,而不是單純修輸出格式。
它實際證明了什麼
實驗是以 unified VLM BAGEL 為 backbone。摘要說明,加入 IPT supervision 後,模型在空間推理任務上穩定進步,而且常常比純文字 chain-of-thought 訓練更好。更值得注意的是,這種好處不是靠推理時生成圖片來達成的。
也就是說,IPT 的訓練收益可以留在模型內部表示裡,到了 inference 時還能用。這讓它比「部署時還要額外生成視覺內容」更實際,因為推理成本和系統複雜度都比較可控。
摘要裡有幾個具體數字。首先,在 Multiview Counting 上,IPT 讓準確率提升 3.4%。其次,在 Path Tracing 上,它達到和強閉源模型相當的表現。除此之外,摘要沒有公開完整 benchmark 細節,所以我們不能從這份 raw 資料再延伸更多數字。
作者也提到,把 IPT 和 label-only supervision 結合,還能再拿到額外增益。這代表 IPT 不是取代答案監督,而是和既有標註互補。對訓練流程來說,這是好消息,因為它比較像加一層有效的中介學習,而不是整套重做。
另一個值得工程師注意的結果,是 textual chain-of-thought 在這類任務上可能明顯拖累表現。這句話很關鍵。很多時候大家會直覺以為「多想一點、多講一點」就會更準,但在空間任務裡,模型也許更需要的是對應的感知表徵,而不是更多文字。
對開發者有什麼實際意義
如果你在做多模態 agent、機器人助手、圖表閱讀器,或任何需要理解隱藏幾何關係的系統,這篇論文提供的是一個很明確的訓練方向:不要只逼模型把空間問題講成文字,而是讓它學會一個更貼近任務本質的中介表示。
這對實作很有啟發。因為很多模型在 prompt 上看起來會推理,但一旦問題涉及遮擋、路徑、視角切換,就開始失真。IPT 的觀點是,這不是單純語言不夠多,而是模型缺了一個能承載空間想像的層次。
從產品角度看,這種方法也可能比純文字推理更容易控管。摘要沒有宣稱完整可解釋性,但至少它把中介感知表示顯式化了。對需要除錯的系統來說,這通常比一段長長的自然語言理由更有抓手。
不過,這裡也要提醒限制。摘要只提到 BAGEL 這個 backbone,沒有說這套方法已經跨架構驗證到什麼程度。所以目前還不能直接下結論說 IPT 對所有 VLM 都一樣有效。
這篇研究還沒回答什麼
第一,這不是一個泛化到所有多模態推理的總解。它聚焦的是「看不到的空間結構」這一類問題。換句話說,IPT 強的是特定型態的空間推理,不是所有視覺理解。
第二,資料集雖然有約 20K examples,但仍然是任務型資料,不是大規模真實部署場景。這表示它很適合研究和訓練,但還不能直接等同於線上產品的全部情境。
第三,摘要只給了少量數字。雖然我們知道 MVC 提升 3.4%,也知道 PT 能打到強閉源模型,但沒有更完整的 benchmark 表格,所以這份 raw 資料能支持的結論也只能到這裡。
所以比較穩妥的讀法是:IPT 是一個有方向感的訓練訊號,證明「空間推理不一定要走文字路線」。它不是終局方案,但已經足夠提醒大家,multimodal model 的瓶頸,可能在中介表徵,而不只是模型大小。
總結
這篇論文最重要的訊息很清楚:當任務需要推理看不見的空間時,讓模型先學會中介感知,比硬逼它用文字繞路更有效。IPT 把「想像」變成可監督的 token,結果在多視角計數、路徑追蹤等任務上都看到改善。
對台灣開發者來說,這代表一個實用方向。若你的應用碰到遮擋、視角或隱藏結構問題,下一步不一定是加更長 prompt,而可能是重新設計模型學到的中間表示。這篇研究就是在提醒大家:有些空間題,真的不是靠嘴巴解的。
最終,IPT 證明的不是「模型會講故事了」,而是模型開始能把看不見的空間關係學成一種內部能力。這正是多模態系統往前走時,最值得注意的地方。