LoRA vs QLoRA vs 全量微調
這篇比較 LoRA、QLoRA 與全量微調,幫你用成本、顯存、速度與效果判斷哪一種大語言模型微調方式最適合你的團隊。
這篇比較 LoRA、QLoRA 與全量微調,幫你用成本、顯存、速度與效果判斷哪一種大語言模型微調方式最適合你的團隊。
在 LoRA、QLoRA 與 全量微調 之間做選擇,通常不是在比誰最強,而是在比預算、模型大小,以及你到底要把模型行為改多深。這篇是寫給要做模型客製化、但不想在顯存、成本與效果之間盲猜的人。
一張表看懂
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
| 維度 | LoRA | QLoRA | 全量微調 |
|---|---|---|---|
| 典型 GPU 需求 | 1 張 A100 40GB 或 80GB | 1 張 A100 80GB;7B 等級有時 24GB 也可跑 | 8B 以上常見需 4 張 A100 80GB 或 2 張 H100 80GB |
| 8B SFT 粗估成本 | 約 15 至 40 美元 | 約 12 至 20 美元 | 約 150 至 500 美元以上 |
| 適配器/檢查點大小 | 20 至 100 MB | 20 至 100 MB | 約 10 至 30 GB |
| 訓練速度 | 快 | 在顯存吃緊時最快 | 最慢 |
| 效果上限 | 窄任務下很高 | 多數 SFT 任務很高 | 深度行為改寫時最高 |
| 遺忘風險 | 低到中 | 低到中 | 最高,且最吃資料混合與評估 |
LoRA
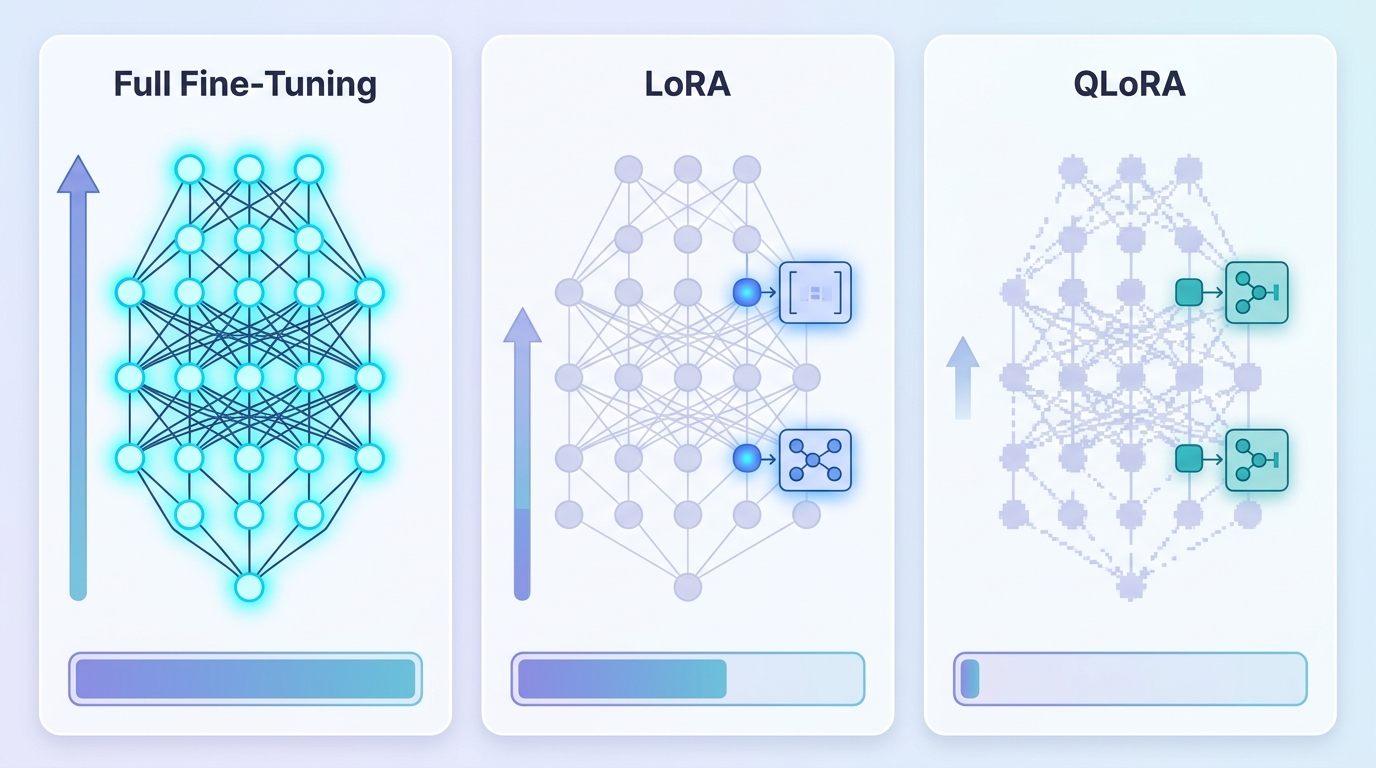
LoRA 的核心優勢,是把大模型本體凍結,只訓練少量低秩適配器。這代表你不必為了客製化任務,去承擔整個模型權重都更新的風險,也不需要把訓練管線做得太複雜。對很多團隊來說,這種「改得夠多,但不會亂改」的特性很實用。
它特別適合已經有足夠顯存可以載入基底模型,並且希望保留多個版本、方便切換的情境。因為適配器檔案通常只有數十 MB,部署與回滾都很輕鬆;如果你要同時維護客服、法務、銷售三種版本,LoRA 會比全量微調好管理很多。
QLoRA
QLoRA 可以把基底模型在訓練時壓到 4-bit,因此在顯存有限的情況下,往往是最容易落地的方案。對 7B 或 8B 級模型來說,它常常能把原本需要多卡的任務,縮到單卡可做,這也是許多團隊先選它的原因。
代價是量化會多一層技術複雜度,極端高要求任務的上限也可能略受影響。不過如果你的目標是指令微調、格式學習、文件問答或一般領域適配,QLoRA 通常給你最好的成本效益比,尤其適合想先做出可用版本,再慢慢迭代的人。
全量微調
全量微調會更新所有權重,所以它不是只學一點點,而是有機會真正重塑模型行為。這種自由度在某些場景很重要,例如資料量夠大、標註品質夠高,或你要模型學會非常特定的推理、語氣與決策邏輯,這時候適配器可能不夠力。
但它的代價也最直接:顯存需求高、訓練慢、調參成本大,而且一旦資料分佈不夠乾淨,災難性遺忘會比前兩者更明顯。換句話說,全量微調不是不能做,而是你要有足夠資料、足夠算力,還要有足夠嚴格的評估流程,才值得上。
差異不只在成本
很多人只看 GPU 與價格,但真正拉開體感差距的,其實是維運方式。LoRA 與 QLoRA 的檢查點小、迭代快,適合頻繁試錯;全量微調則更像一次大工程,前期準備、訓練監控、回歸測試都要更完整,否則很容易花了錢卻拿不到穩定收益。
另外,若你的產品需要多版本並存,LoRA 與 QLoRA 的適配器思維會比較友善。你可以保留同一個基底模型,針對不同客群掛不同 adapter;全量微調則通常是整包模型一起變,版本管理與回滾成本都更高。
怎麼選
如果你是新創、內部平台團隊,或只有一兩位工程師在推專案,先選 QLoRA。它最適合用有限預算做出第一版,讓你先驗證資料、任務定義與評估方式,再決定要不要升級到更重的方案。
如果你已經有穩定 GPU 預算,顯存不是瓶頸,而且希望訓練流程更直覺、少碰量化細節,那就選 LoRA。它很適合需要多版本管理、又想維持部署彈性的團隊,也常是從原型走向正式服務時的安全選擇。
如果你手上有大量高品質資料,且產品屬於高風險或高敏感場景,例如金融、醫療、法遵或需要深度行為改寫的任務,那就考慮全量微調。它適合願意投入更多算力與評估成本,只為換取最大控制力的團隊。
預設先選 QLoRA;只有在你同時具備充足資料、充足算力,而且確定需要深度改寫模型行為時,答案才會轉向全量微調。