自動化 LLM Agent 的記憶怎麼設計
這篇綜述整理自主 LLM agent 的記憶怎麼設計、怎麼評估、怎麼用,重點放在機制選擇與仍未解決的問題。
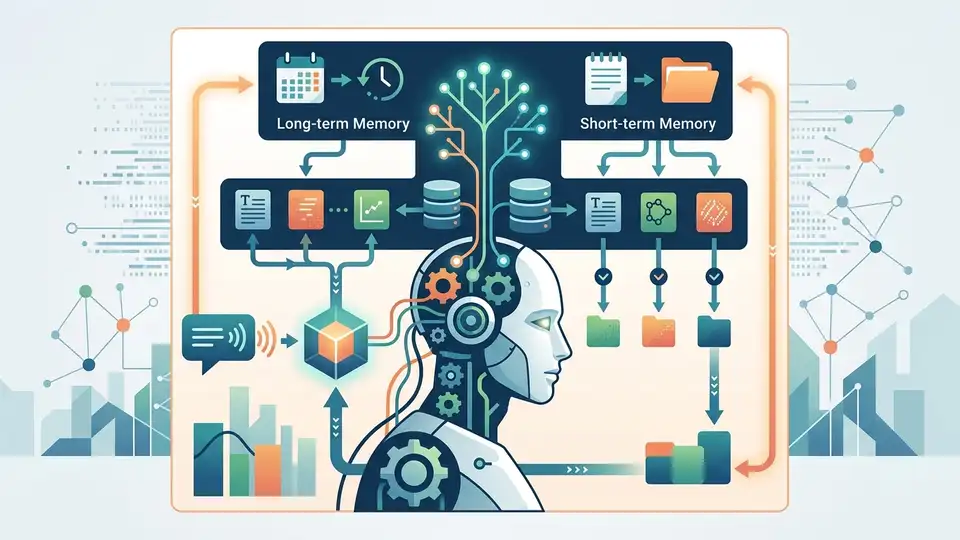
這篇綜述在整理自主 LLM agent 的記憶設計、實作與評估方式。
自主 LLM agent 要能長時間工作,記憶幾乎是必修課。這篇綜述 Memory for Autonomous LLM Agents: Mechanisms, Evaluation, and Emerging Frontiers,把 2022 到 2026 年初之間的相關研究串起來,整理記憶如何幫助 agent 在多次互動、跨任務、跨 session 的情境下保留資訊。
對開發者來說,問題其實很直接:怎麼讓 agent 不要每次都從零開始?這篇論文把記憶視為核心能力,而不是可有可無的附加功能。它要處理的不是單一技巧,而是一整個設計空間:怎麼存、怎麼取、怎麼用、又怎麼評估。
這篇在解什麼痛點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這份綜述先從大型語言模型本身的限制切入。LLM 單獨使用時,不會自然保留跨互動的有用狀態。對只回答一次性問題的聊天機器人來說,這不一定是問題;但對要長期執行任務的 agent 來說,這就是核心瓶頸。
一個真正的 autonomous agent,通常得記得使用者偏好、過去做過什麼、任務現在進行到哪一步,甚至還要知道哪些資訊已經過期。沒有記憶,模型就很容易像無狀態的 chatbot,每次都重新理解同一批背景,效率差,也容易出錯。
因此,這篇論文不是在問「要不要加記憶」,而是在問「記憶要怎麼被工程化」。它把記憶當成一個需要被設計、被量測、被推理的能力,而不是在 prompt 外面補一層暫存就算完成。
這個切法很重要,因為 agent 的問題從來不只是生成品質。當系統要跨多輪互動、跨多個工作階段持續運作時,記憶就會直接影響可用性、穩定性和可維護性。
記憶到底怎麼運作
這篇是綜述,不是新系統,所以 abstract 沒有給單一演算法,也沒有把某一個方法包裝成唯一答案。它做的是更像地圖的工作:把現有研究裡的記憶機制整理成一個可理解的框架。
從 abstract 透露的內容來看,作者關心的是記憶的幾個基本環節:什麼資訊會被存下來、什麼時候寫入、之後怎麼檢索、以及 agent 如何在後續推理或行動時使用這些內容。換句話說,記憶不是一個靜態資料夾,而是一條跨時間運作的流程。
這種整理方式對工程師很有幫助,因為「memory」在不同系統裡可能完全不是同一件事。有些設計偏向短期上下文管理,有些是長期 agent state,有些則是把資訊帶到下一個任務的更廣義機制。若沒有先把概念拆開,討論很容易變成各說各話。
這篇綜述的價值,就在於把這些不同層次的做法放到同一張圖裡,讓讀者知道自己到底在處理哪一種記憶問題。
- 記憶重點是跨互動持續保存資訊,不只是把 prompt 變長。
- agent 的記憶要靠系統設計實作,不能直接預設模型會有。
- 評估記憶不是附屬題目,而是研究核心之一。
- 這份整理涵蓋 2022 到 2026 年初的相關工作。
論文實際整理了什麼
就 abstract 來看,這篇沒有提供新的 benchmark 數字,也沒有公開完整的實驗細節。它不是一篇主打單一模型表現的論文,所以摘要裡也沒有可直接引用的性能數值。
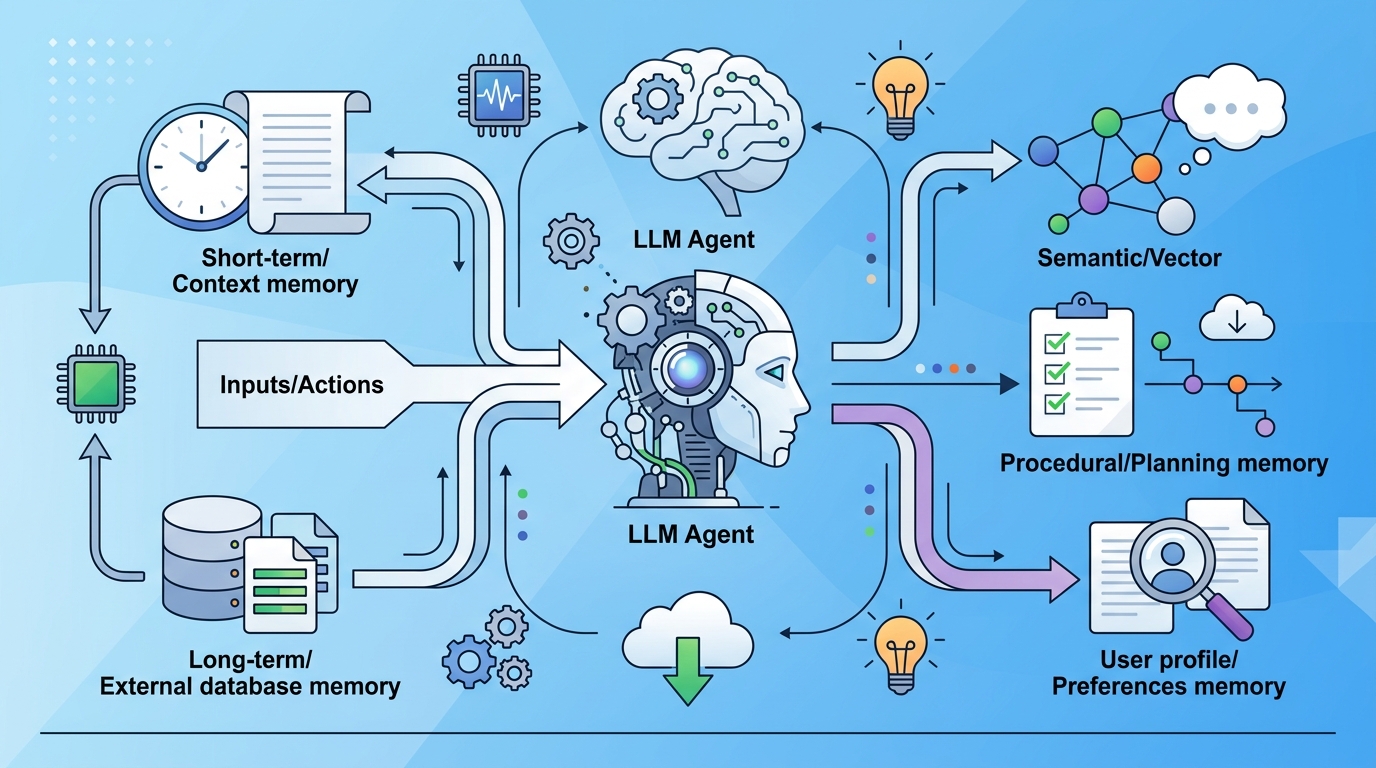
但它有明確說明自己整理的範圍:涵蓋 2022 到 2026 年初的研究,並且把這個領域分成三個主軸來看,分別是 mechanisms、evaluation、emerging frontiers。這代表作者不只想描述「有哪些方法」,還想回答「怎麼比」以及「接下來往哪走」。
其中,evaluation 特別值得注意。記憶系統很容易在概念上說得漂亮,但實際上常常難以比較。不同系統可能存的東西不同、觸發條件不同、檢索策略不同,最後就算都叫 memory,也未必能放在同一把尺上衡量。這篇綜述把評估獨立拉出來,等於承認這是整個領域的關鍵難題。
abstract 也提到 emerging frontiers,表示作者不只在回顧過去,還在看新方向。只是來源沒有列出這些前沿的具體內容,所以能安全下的結論只有一個:這個領域仍在快速演進中,還沒有收斂成單一標準做法。
換句話說,這篇論文的產出不是一個新模型,而是一個能幫讀者定位研究版圖的整理工具。對想進入這個題目的開發者與研究者來說,這種整理本身就很有價值。
對開發者有什麼影響
如果你在做 agent,記憶會直接影響產品體感。沒有記憶,系統每次都像重新啟動;有記憶,才有機會讓 agent 在長流程裡保持一致,少問重複問題,也比較能延續任務進度。
這篇綜述對實作最有幫助的地方,不是給你一個現成方案,而是提醒你:記憶架構本身就是設計題。你必須先想清楚哪些資訊值得存、多久失效、什麼時候該取回、取回後怎麼影響推理,否則記憶很容易變成另一個不穩定來源。
對團隊來說,這也意味著 memory 不能只交給模型能力本身。它牽涉到資料結構、存取策略、上下文管理、以及系統整體的行為一致性。只要其中一環定義不清,agent 就可能出現前後矛盾、依賴過期資訊,或是一直帶著不必要的歷史內容。
這篇文章把記憶視為核心能力,等於在提醒開發者:如果你想做的是「會持續工作」的 agent,就不能把 memory 當成最後才補的功能。它應該跟任務規劃、工具使用一樣,從架構階段就一起考慮。
限制與還沒解完的問題
這篇綜述的限制也很明確。首先,abstract 很高層次,沒有列出 benchmark 數字,也沒有提供具體實驗設定,所以如果你期待從摘要直接看到量化結果,這份來源沒有給。
其次,它是 survey,不是提出新方法的系統論文。這代表它的強項在於整理與框架化,不在於直接證明某個新記憶模組一定優於其他做法。對工程落地來說,它能幫你建立判斷標準,但不能替你完成實作驗證。
不過,這也正是這篇論文的意義。自主 agent 的記憶研究正在快速擴張,若沒有一篇能把機制、評估與新方向收斂起來的綜述,開發者很容易只看到零散技巧,看不到整體設計空間。
目前 abstract 留下的最大問題也很直接:什麼樣的記憶系統,才真的能在真實 agent 工作負載裡穩定運作?這篇綜述沒有宣稱終極答案,但它把問題講清楚了。對還在摸索 agent 架構的人來說,這種清楚本身就很有用。
更白話地說,這篇論文不是告訴你「記憶已經解決了」,而是告訴你「記憶是 agent 能不能長期可用的關鍵,而且現在還在研究中」。如果你正在做長流程、自主決策或跨 session 的 LLM 系統,這份整理值得先看。