為什麼 AI 應用不該把每個 moderation 標記都直接封鎖
AI 應用應把 moderation 標記當成訊號,不是自動封鎖令;把每個標記都硬擋,通常只會放大誤殺與產品挫折。

AI 應用應把 moderation 標記當成訊號,不是自動封鎖令。
把每個被標記的內容都直接封鎖,是多數 AI 應用最差的預設。它把安全系統變成鈍器,而鈍器會打壞真實產品:使用者在問自傷預防、課堂討論暴力文學,或醫療問題裡帶有敏感詞,系統都可能誤判。你若一律拒絕,不會更安全,只會得到更差的產品與更高的流失。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
moderation 標記不是違規判決。它本質上是風險訊號,告訴你「這段內容值得更謹慎處理」,不是「這段內容必須立刻消失」。如果把訊號直接當裁決,誤殺就會變成常態。像是使用者問「小說裡如何寫一場打鬥」,模型可能因為暴力字眼而標記,但真正需要的不是封鎖,而是改走更安全的回應路徑。

這不是理論問題,而是實作問題。以一個教育產品為例,老師要求學生分析《麥田捕手》中的自傷意象,系統若因敏感詞直接擋下,等於把教材當成風險內容。更好的做法是把標記交給政策層,再決定是縮限回答、補充脈絡,還是請使用者澄清。標記是輸入,不是終局。
第二個論點
硬封鎖會把安全做成產品失敗。當使用者連正常問題都被拒絕,他們學會的不是更安全,而是這個產品不可靠。OpenAI 2024 年公布的 moderation 文件明確把分類器定位成政策流程的一部分,重點在於依情境處理,而不是把每次命中都當成終止條件。這個設計方向本身就說明了:分類與執行必須分開。
商業代價同樣直接。假設客服型 AI 每天有 1% 的請求因誤判被擋,若日請求量是 10 萬筆,就有 1,000 次失敗體驗要被客服、工單與重試機制吸收。這些不是小瑕疵,而是會累積成 churn 的摩擦。高敏感度不等於高安全,真正有用的是高精準度。
第二個論點
不同產品的風險承受度根本不同。青少年產品、醫療輔助工具、企業知識庫與通用聊天機器人,不該套同一條封鎖規則。美國 NIST 的 AI Risk Management Framework 強調情境化治理,因為風險不是抽象存在,而是跟使用場景綁在一起。在高風險場景,硬封鎖合理;在一般場景,硬封鎖往往過度。
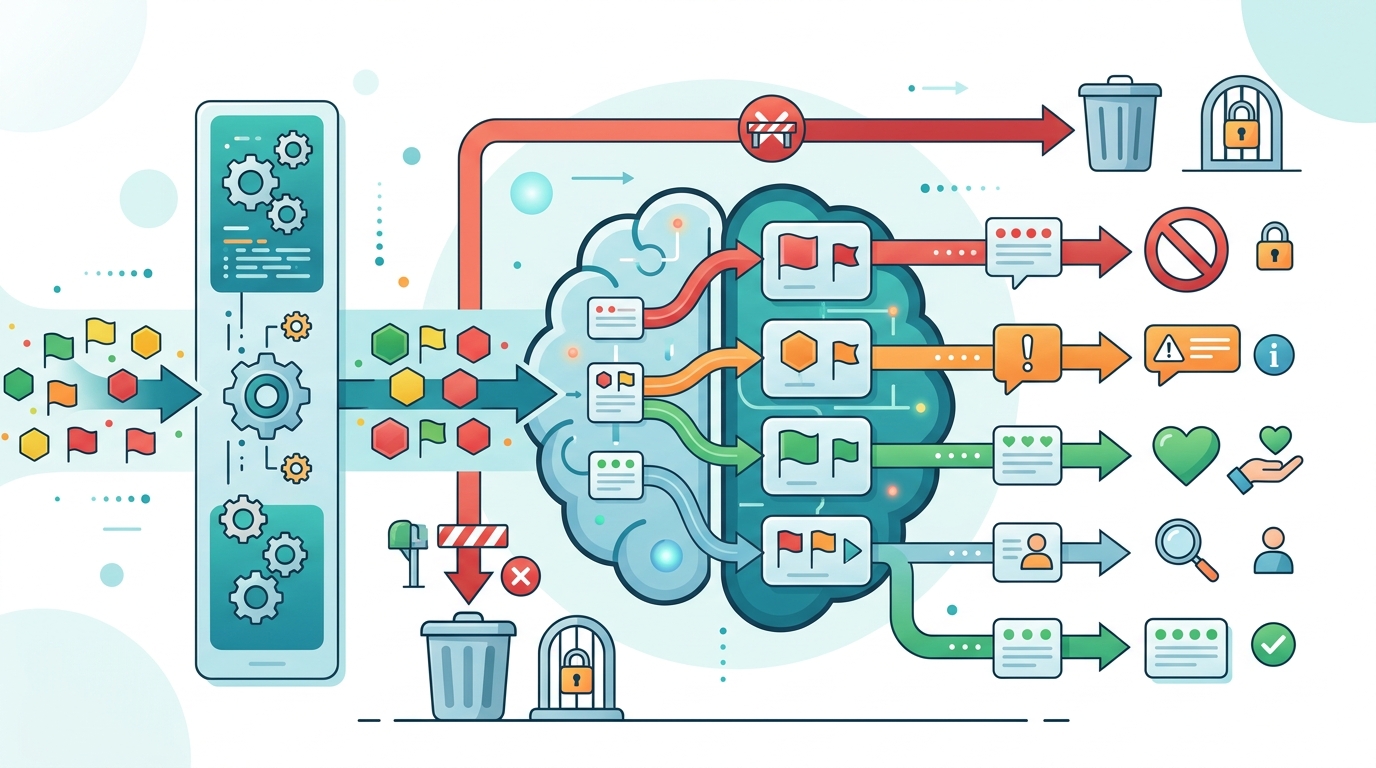
更好的架構是分級處理:未命中就放行,低信心命中走安全改寫,高風險命中才拒絕或轉人工。這樣做的好處很具體。若使用者問到自傷相關內容,但意圖是求助,系統可以先提供危機資源,再給出受限回應;若內容只是帶有性相關詞彙,系統可以拒絕細節,仍回答無害部分。這比一刀切更安全,因為它保留了幫助,同時限制濫用。
反方可能怎麼說
支持硬封鎖的人有一個很強的理由:操作簡單。只要所有標記都拒絕,你就把「漏掉有害內容」的機率壓到最低,也減少工程與審查團隊的決策負擔。對於高風險產品,這種簡化確實有價值,也更容易向法務、審計與監管解釋。
這個立場不是錯的。若你的產品面向未成年人、處理高風險心理健康議題,或受嚴格合規要求約束,保守政策反而是正解。問題在於,多數 AI 應用並不屬於這種情境。對一般產品來說,把每個標記都當成封鎖令,等於把一個概率訊號誤當成最終裁決,結果就是可避免的誤殺。
所以答案不是忽視標記,而是把標記接到政策層。該拒絕的拒絕,該縮限的縮限,該升級審查的升級審查。安全不是把門關死,而是依風險決定門要開多大。
你能做什麼
如果你是工程師、PM 或創辦人,請把 moderation 管線做成分級系統:低風險命中改寫回應,高風險命中拒絕或人工審查,並記錄每次決策理由。用真實使用者 prompt 測 false positive,按產品場景調整閾值,不要全站共用一條硬規則。你的目標不是把所有東西都擋掉,而是在不破壞合法使用的前提下,把真正的風險壓下來。