Why AI apps should not hard-block every flagged moderation result
AI apps should treat moderation flags as signals, not automatic shutdowns, because hard-blocking every flag overblocks legitimate content.

AI apps should treat moderation flags as signals, not automatic shutdowns.
Hard-blocking every flagged moderation result is the wrong default for most AI apps. It turns a safety system into a blunt instrument, and blunt instruments break real products: a user asking about self-harm prevention, a classroom discussion of violence in literature, or a medical question that includes sensitive terms can all be flagged even when the intent is legitimate. If your app responds by refusing all of it, you do not get safer behavior, you get a worse product and a frustrated user base.
Moderation flags are not the same as policy violations
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The first mistake is treating a flag as a final verdict. Moderation models are designed to detect risk, not to understand full context the way a human reviewer would. That means the output is best read as a probability signal that something deserves review or a narrower response, not as proof that the content is disallowed. If you collapse that distinction, you will overcorrect and block content that should have been allowed with guardrails.

A better architecture separates detection from enforcement. For example, if a user asks how to write a fictional scene involving violence, the moderation layer may flag the prompt because of surface language, but the application can still route the request into a safer completion path, constrain the answer, or ask for clarification. That is the right pattern: use the flag to change handling, not to end the conversation by default.
Overblocking is a product failure, not a safety win
When moderation is too aggressive, users learn that the app is unreliable. They stop asking normal questions, they rephrase endlessly, or they leave. In practice, this creates a perverse incentive: the safest-looking system becomes the least useful one. A moderation stack that blocks legitimate educational, medical, or support-related content is not just inconvenient, it directly reduces trust in the application.
There is also a business cost. Every false positive creates support load, manual review overhead, and churn risk. If a customer cannot get an answer because a harmless phrase triggered a block, that is not an edge case, it is a broken user journey. Strong moderation should reduce harm while preserving as much legitimate use as possible, and that means designing for precision, not just maximum sensitivity.
Context-aware handling beats one-size-fits-all blocking
The correct response to a flag depends on the use case. A consumer chatbot, a teen safety product, and an enterprise knowledge assistant should not apply the same enforcement logic. In a high-risk setting, a hard block may be right. In a general-purpose assistant, the better move is usually tiered handling: allow, soften, redirect, or escalate based on category and confidence.
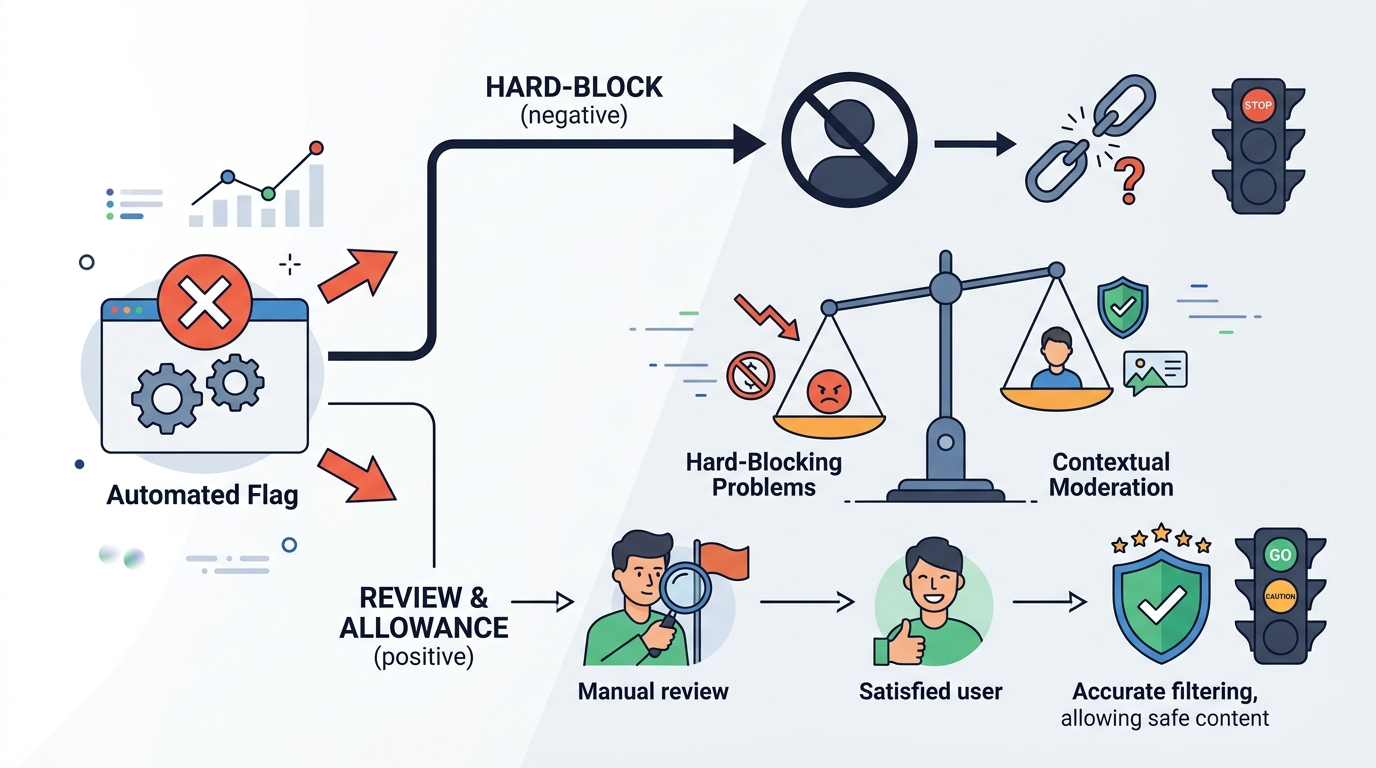
OpenAI’s own moderation tooling is most useful when it sits inside a policy layer that accounts for context, user intent, and downstream risk. For example, if content is flagged for self-harm but the intent is support-seeking, the app can provide crisis resources and a constrained response instead of a dead end. If content is flagged for sexual content in a general assistant, the app can refuse explicit details while still answering the benign part of the request. That is safer than a blanket block because it preserves help while limiting abuse.
The counter-argument
The strongest case for hard-blocking is operational simplicity. If every flag becomes a refusal, you minimize the chance that harmful content slips through, and you reduce the burden on engineering and moderation teams. For products that face severe abuse risk, that simplicity is valuable. It is also easy to explain to users and auditors: flagged means blocked, full stop.
That argument is real, and for some products it wins. If your app serves minors, handles high-stakes mental health content, or operates under strict compliance requirements, a conservative policy is the correct choice. But for most AI apps, hard-blocking every flag is too crude. The specific reason is that moderation output is not a final policy judgment, and using it that way guarantees avoidable false positives. The better answer is not to ignore the flag, but to attach a policy decision to it.
What to do with this
If you are an engineer or founder, build a moderation pipeline with tiers: unflagged content passes, low-confidence flags trigger safer completion patterns, and high-risk categories route to refusal or human review. Log the reason for every decision, test false positives against real user prompts, and tune per product surface instead of using one global rule. The goal is not to maximize blocks. The goal is to maximize safety without breaking legitimate use.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production