為什麼 Distribution Fine Tuning 比 SFT 更適合 …
Distribution Fine Tuning 比 SFT 更適合 LLM 寫作,因為它更接近人類文本的分布,而不是只學會表面格式。
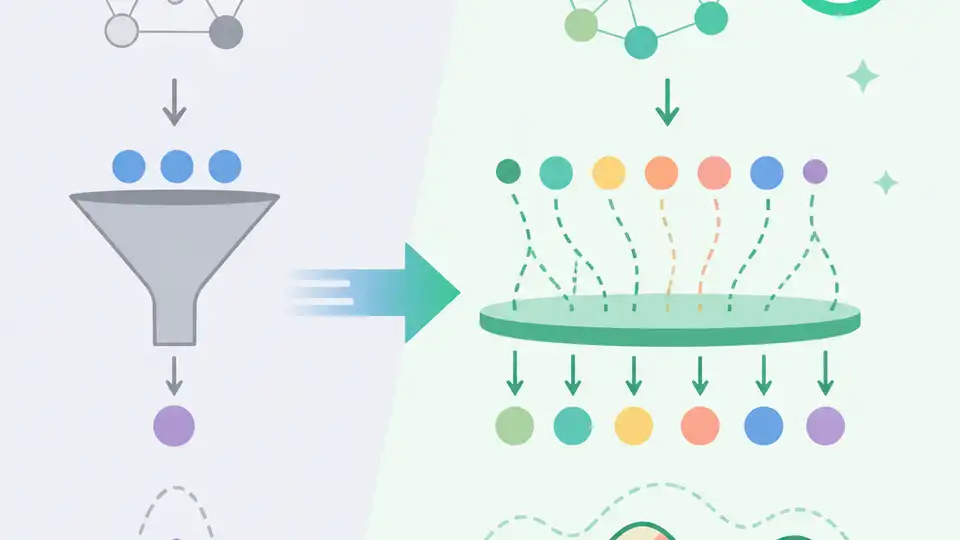
Distribution Fine Tuning 比 SFT 更適合 LLM 寫作,因為它更接近人類文本的分布,而不是只學會表面格式。
Distribution Fine Tuning 才是修正 LLM 寫作 slop 的正解,單靠 SFT 不夠把文字訓練成像人寫的。
Rosmine 的論點很直接:只做 supervised fine-tuning 的模型,雖然能照指令作答,卻仍會過度重複詞組、套用萬用結構,並且抓不到訓練集裡真正的語氣與節奏。文章用三種指標支撐這件事,包括 token distribution distance、embedding-level distance 與 judge model preference score。在報告的 benchmark 上,DFT 在寫作品質相關的指標上壓過 SFT「super baseline」,而且不是靠暴增算力或模型大小換來。這不是小修小補,而是證明現行 post-training 流程很可能優化錯了目標。
第一個論點:SFT 優化的是樣本,不是分布
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
SFT 教模型模仿單一答案,但寫作品質本質上是分布問題。模型就算學會正確格式,若沒有學到細節密度、句型變化、詞頻節奏,輸出仍會看起來工整卻很空。Rosmine 文中用 MMD 和 token L2 distance 量化這個落差,重點不是模型不會寫,而是它在統計上偏離了好文本的分布。寫作一旦統計上偏掉,就會表現成重複、過度順滑、以及老掉牙的轉折句。
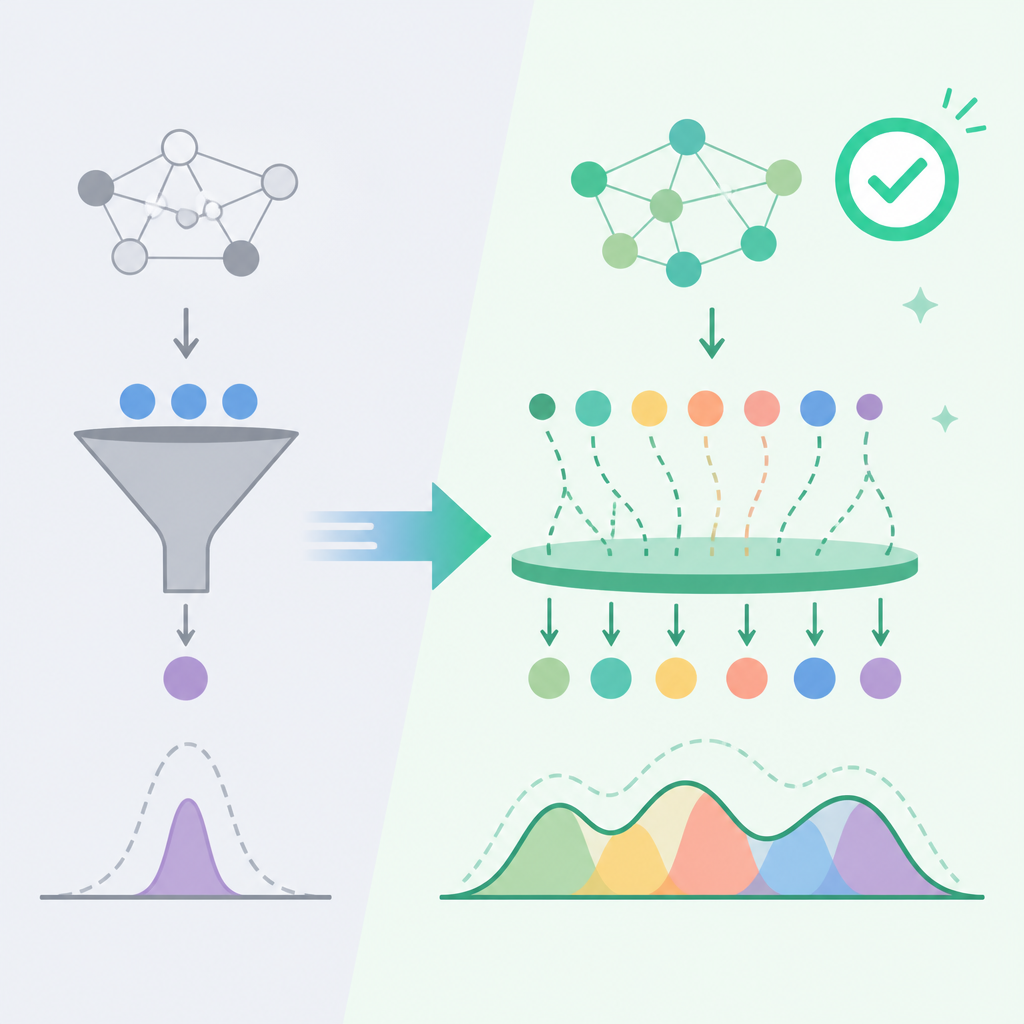
數字把差距拉得很清楚。文章表格裡,14B 的 DFT 模型做到 MMD 0.018、JMQ 0.80,而 14B 的 SFT super baseline 則是 MMD 0.037、JMQ 0.49。這代表 judge 偏好大幅上升,分布失配也明顯下降。作者還報告 DFT 相較 SFT baseline 在 creativity 提升 164%、coherence 提升 28%、clarity 提升 16%、meaningful detail 提升 146%。不論你怎麼看指標設計,方向都一致:對寫作來說,貼近訓練分布比單純學會服從指令更重要。
第二個論點:slop 不是風格問題,而是訓練問題
很多人把 slop 當成模型語氣不好,這種說法太輕了。它其實是訓練流程獎勵錯誤行為的結果。文章指出,像 em dash、"it’s not X, it’s Y"、以及空泛抽象語句這些過度使用的模式,常常是 post-training 特別是 RLHF reward hacking 的副作用。這個解釋有說服力,因為它把表面上的文風失真,直接連到最佳化機制。如果模型一直學到「安全、討好、容易被接受」的句子比較容易拿高分,它就會持續產出這類句子。光靠改 prompt,根本碰不到根因。
樣本輸出也支持這個判斷。文章展示的 SFT 模型在某些 temperature 下,會不斷重複同一個主詞;在另一些設定下,又會跳進不連貫的轉折,甚至冒出非英文字符。DFT 被當成修正方案,因為它把輸出往訓練分布拉回來,而不是往一種泛用但空洞的「有幫助」風格推去。這對做面向用戶產品的人尤其重要。技術上合規、實際上乾癟的 chatbot,仍然是失敗產品。使用者一眼就看得出每段都像模板,也看得出模型自信滿滿卻內容薄弱。
反方可能怎麼說
最強的反對意見是:DFT 可能只是把「像人寫」這件事做得更像,卻不一定更有用、更可信,也不一定更能跨任務泛化。若評估依賴特定 judge model、特定資料切片、以及特定的「human-like」定義,那麼這些提升未必能轉移到所有場景。對 code、法律文件、客服回覆、創作小說來說,正確分布本來就不同。
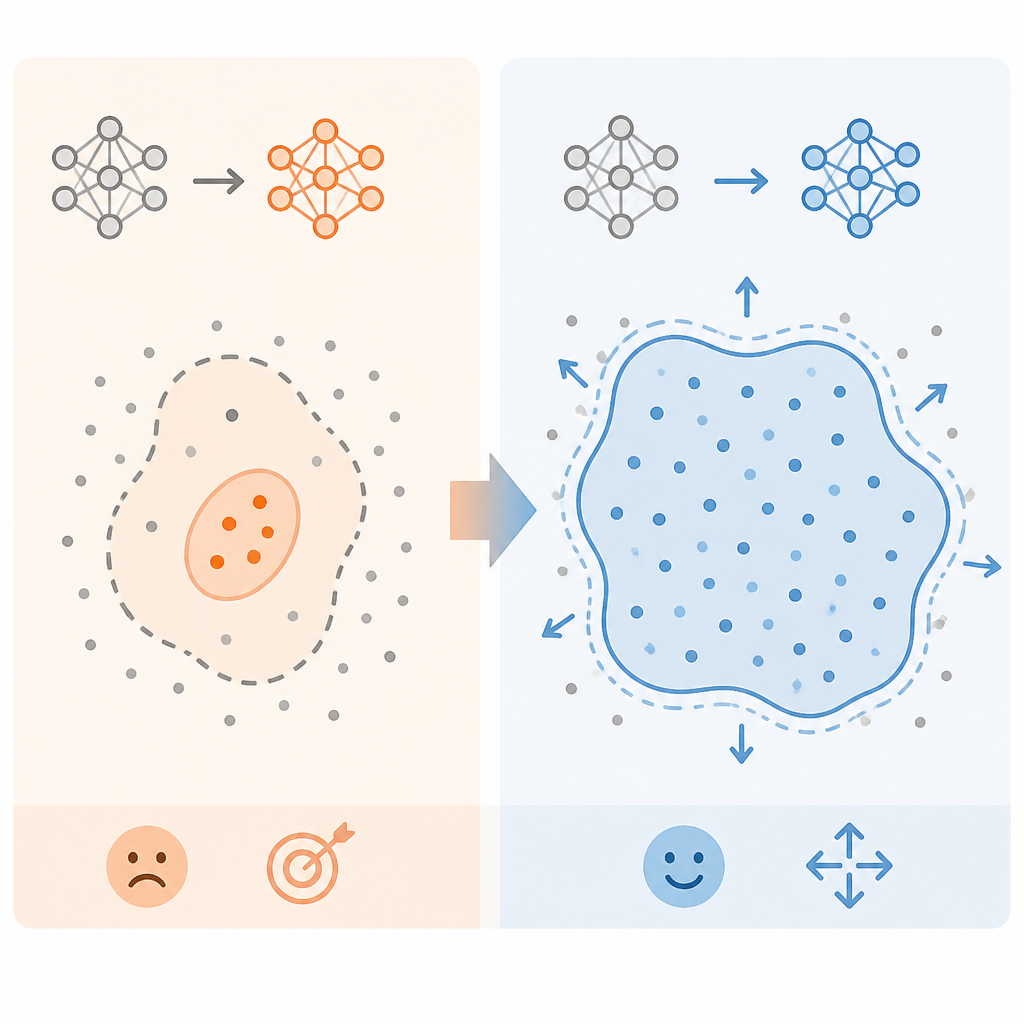
這個質疑成立,但它推翻不了 SFT,只是在劃定 DFT 的邊界。正確結論不是 DFT 能解決一切輸出問題,而是現有 post-training 堆疊確實漏掉了寫作品質這一層,因為它太偏重 helpfulness 與 preference,卻不夠重視真實好文本的分布。Rosmine 的結果已經足夠強,足以證明 distribution matching 是缺失的一環。即使 DFT 仍需要 domain-specific 調校與更廣泛驗證,舉證責任也已經轉移:現在輪到 SFT 擁護者說明,為什麼一個更接近人類文本分布的方法,不該優先用在寫作任務上。
你能做什麼
如果你是工程師,別再把寫作品質當成 prompt engineering 問題,改成把它當分布問題來量測。建立同時追蹤重複率、內容密度、以及人類偏好勝率的 eval,再用固定 baseline 比較不同 post-training 方法,不要靠 sampler 設定挑結果。若你是 PM 或創辦人,不要把「看起來很會寫」當成產品標準,要求輸出必須自然變化、保有細節,並且能在和真人文本並排時站得住。這件事的結論很直白:如果你的模型寫得像模板,修法在訓練,不在措辭。