Why Evolution Strategies Are the Right Way to Fine-Tune LLMs
Evolution strategies are a better fine-tuning path than reinforcement learning for enterprise LLMs because they are simpler to run, easier to reproduce, cheaper to deploy, and more reliable in production.

Evolution strategies should replace reinforcement learning as the default way enterprises fine-tune LLMs.
Cognizant AI Lab’s new research points to the core reason: most businesses do not need a heroic training stack, they need a repeatable one. The company says its methods make fine-tuning simpler to run, easier to reproduce, and more reliable in real-world settings while also cutting compute needs. That matters because enterprise AI fails less from a lack of model capability than from the operational mess around it: unstable training runs, expensive iteration cycles, and brittle behavior when a workflow moves from a lab demo to a live process.
First, evolution strategies fit the enterprise reality better than RL
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
Reinforcement learning is powerful, but it is also finicky. In the enterprise setting, that finickiness becomes a tax on every deployment. Cognizant’s framing is important here: it describes RL as costly, difficult to scale, and prone to unintended behaviors. That is not a minor implementation detail. It is the difference between a model team that can ship improvements weekly and a team that spends months chasing unstable reward signals.

The strongest evidence is the practical target Cognizant highlights: vertical-specific fine-tuning, such as legal or other precision-heavy domains. In those settings, the goal is not open-ended creativity. It is consistent behavior on a narrow task. Evolution strategies are a better match because they optimize for task performance without requiring the same reward engineering burden. When the business requirement is “make this model reliably do one job,” gradient-free search is often the cleaner tool.
Second, fewer compute demands change the economics of adoption
Compute is not just a cloud bill. It determines who can iterate, how often they can retrain, and whether smaller teams can participate at all. Cognizant says its approach helps models run more efficiently with fewer computing resources, and that claim matters more than any benchmark headline. If a fine-tuning method lowers the cost of experimentation, it lowers the barrier to actually improving the model after deployment.
The paper set also calls out smaller, quantized models as a target. That is a smart move because it shifts the conversation away from giant frontier systems and toward systems that are cheaper to run in enterprise environments. A quantized model that can be tuned reliably on less infrastructure is more useful than a larger model that demands constant expensive retraining. For most companies, the winning architecture is the one they can afford to maintain, not the one with the flashiest training story.
Third, reliability is the real product, not raw benchmark theater
Cognizant says the lab is improving how models assess the reliability of their outputs, with clearer guardrails and more confident use. That is the right obsession. Enterprises do not buy an LLM because it occasionally posts an impressive score on a benchmark. They buy it because it can support a workflow without creating hidden failure modes. A fine-tuning method that improves consistency is more valuable than one that only raises the ceiling on a leaderboard.
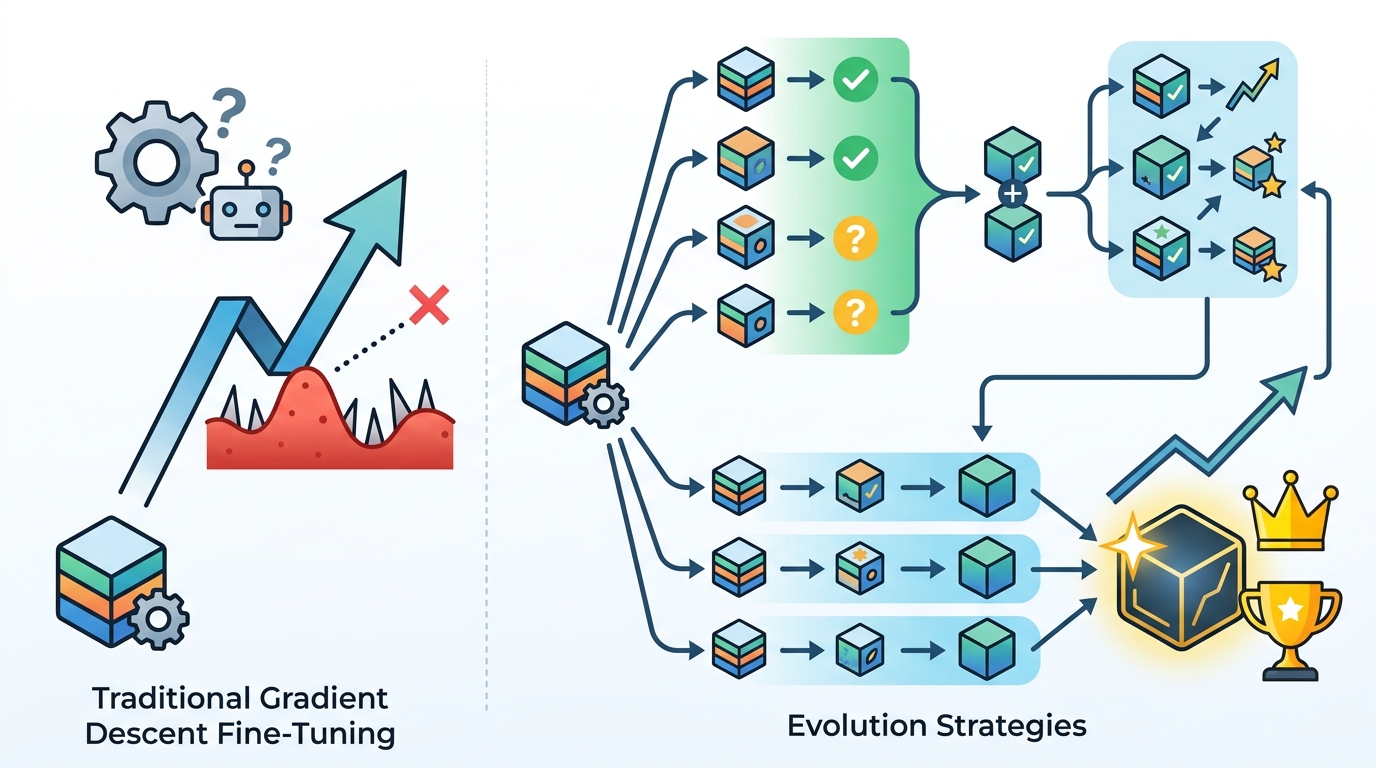
This is where evolution strategies have a structural advantage. Traditional RL often rewards the model for maximizing a signal that is only loosely connected to business value. That can produce odd behaviors, especially when the reward is imperfect. Evolution strategies are blunt, but blunt is not a flaw when the task is constrained and the success criteria are clear. The more important question is whether the model behaves predictably across repeated runs, and Cognizant’s pitch is that this approach does exactly that.
The counter-argument
The best case for reinforcement learning is that it remains the more expressive tool. RL can directly optimize for complex objectives, and in research settings it has helped models learn behaviors that are hard to encode any other way. If the task is highly nuanced, involves long-horizon tradeoffs, or requires learning from rich feedback, RL can outperform simpler methods. That is why some teams will resist replacing it entirely.
There is also a legitimate concern that gradient-free methods may not scale as cleanly to the largest, most capable systems. Cognizant itself acknowledges the need to strengthen the theoretical foundation for scaling evolution strategies to larger models. That admission matters. It means the case for evolution strategies is strongest today in the enterprise zone, not as a universal law for every model class and every objective.
Still, that limitation does not weaken the central argument. Enterprises are not optimizing for the most elegant general-purpose training paradigm. They are optimizing for deployable systems that are cheaper, more reproducible, and less likely to misbehave. On those terms, evolution strategies beat RL where it counts. If a method is easier to operationalize and delivers stronger consistency on complex reasoning tasks, it is the better default even if RL remains useful for a narrower set of problems.
What to do with this
If you are an engineer, stop treating RL as the automatic next step in every fine-tuning project and test evolution strategies first when the task is narrow, the data is limited, and reproducibility matters. If you are a PM or founder, judge the training method by total operating cost, deployment reliability, and how quickly it gets you to a system your team can trust in production. The right question is not which method sounds more advanced. It is which one turns AI spending into repeatable business value.
// Related Articles
- [IND]
WebX 2026 turns speaker hype into a conference brief
- [IND]
AI Weekly: 2026-07-06 ~ 2026-07-13
- [IND]
The AI Act should be treated as Europe’s operating system for AI
- [IND]
Booz Allen’s OpenAI Deal Is Real Advantage, Not Hype
- [IND]
OpenSearch’s vector search benchmark in 5 parts
- [IND]
Vector Databases That Work in Production