為什麼 AI-agent CLI 是新的供應鏈攻擊面
AI-agent CLI 已經成為新的供應鏈攻擊面,因為掃描器擅長找惡意檔案,卻抓不到會誤導代理行為的指令界面。

AI-agent CLI 已經成為新的供應鏈攻擊面,因為掃描器擅長找惡意檔案,卻抓不到會誤導代理行為的指令界面。
AI-agent CLI 不是單純的效率工具,而是新的供應鏈攻擊面;安全團隊若仍只盯著套件、二進位與雜湊,就會漏掉真正的風險。OpenClaw 的案例說明,一個指令就能把正常開源倉庫變成 AI coding agent 會「帶著信任」執行的控制面。這不是傳統惡意程式、不是 typo-squatting,也不是被植入的依賴,而是一種工作流程層級的後門,藏在工具鏈裡,剛好落在掃描器最不擅長看的地方。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
第一個問題是,這種攻擊是操作層的,不只是程式碼層的。傳統供應鏈防護假設風險存在於 artifact:惡意套件、被盜帳號、被竄改的 binary,或混入的腳本。但 CLI-Anything 這類工具把倉庫轉成 AI 可操作的 CLI,等於把「界面」本身變成 payload。當一個命令能讓代理直接執行工作流程,倉庫就不再只是待審查的程式碼,而是可被呼叫的控制面。
這不是邊緣現象。CLI-Anything 在短時間內拿到超過 30,000 顆 GitHub stars,代表這種模式已經從研究樣板走向日常工具。當團隊把 generated CLI 當成 agent 工作流的標配,就等於把一個可被操縱的機制常態化。掃描器看得懂 dependency graph,卻看不懂「這個介面會如何改變代理的決策」。攻擊面因此不是新增一個檔案,而是新增一個會影響執行意圖的層。
第二個論點
第二個問題是,掃描器看錯地方。現有供應鏈掃描擅長找已知壞東西:高風險版本、可疑安裝、異常網路行為、或有問題的依賴關係。但它們沒有成熟分類去處理「一個乾淨倉庫,卻刻意產生一個會被 AI agent 消費的命令介面」。如果倉庫本身沒有明顯惡意,真正的陷阱卻藏在生成後的介面,那麼靜態掃描就會直接失焦。
更麻煩的是,這類風險不是單純的程式碼 provenance,而是 instruction provenance。生成式 CLI 可能內嵌假設、提示詞、命令路由與執行路徑,這些內容不一定像惡意套件那樣明顯,但足以影響代理如何判斷「什麼能執行」。當工具鏈把它當成 productivity feature,攻擊者只要改造這個 feature,就能讓 agent 在合法外觀下做出危險動作。這是治理問題,也是偵測模型落後於新介面的證據。
反方可能怎麼說
最強的反方論點很簡單:AI-agent CLI 只是自動化包裝器,自動化本來就有風險。人類早就信任 build script、install hook 與 CI pipeline;如果倉庫真的有惡意內容,掃描器理論上應該能在樹中某處抓到。從這個角度看,OpenClaw 不是新型威脅,只是舊有信任問題換了一個更順手的介面。
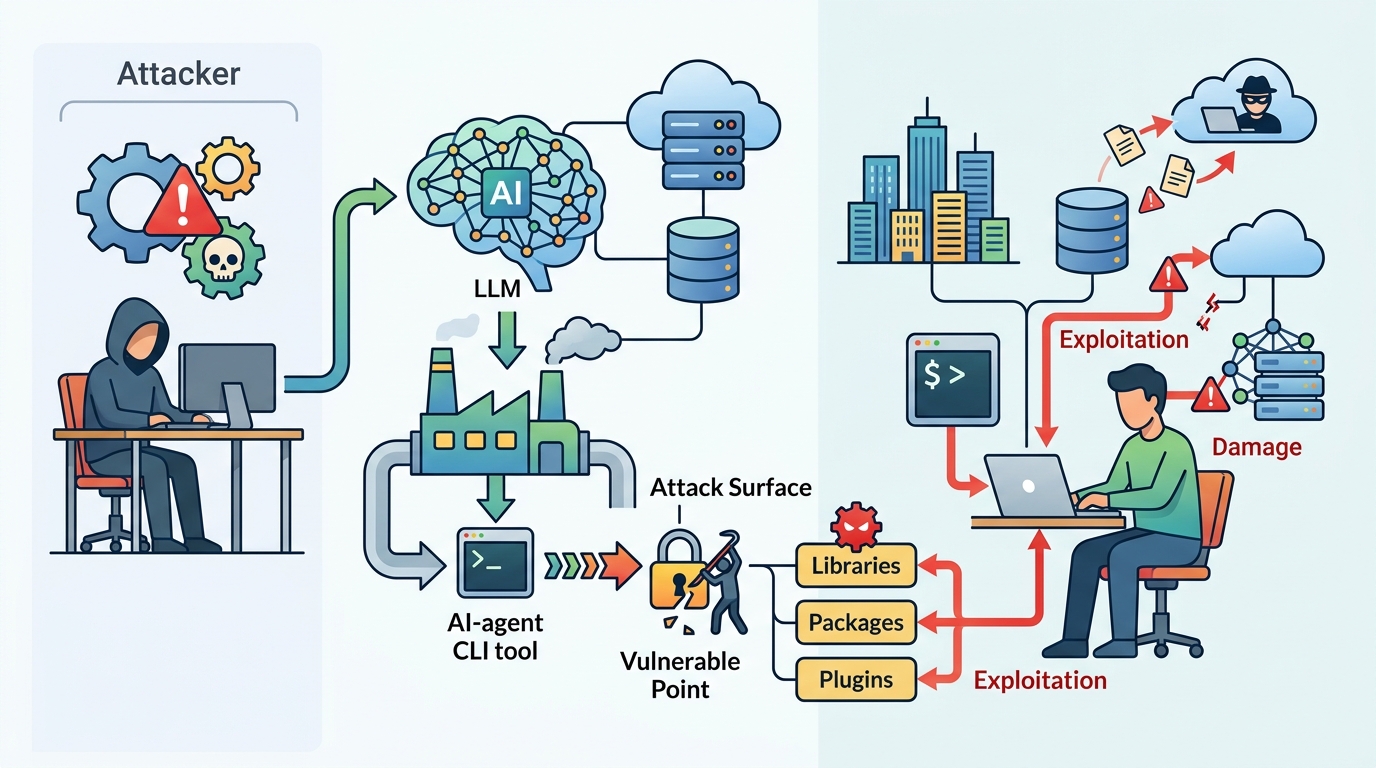
這個說法有力,因為它正確指出:沒有任何工具能把供應鏈中的信任完全消除。系統總得執行某些東西,風險不會憑空消失。
但它忽略了關鍵差異。這裡的危險物件不只是 script,而是會改變 AI agent「認為什麼安全」的生成式命令面。攻擊從檔案檢查轉成意圖操控,這是不同層級的失敗模式。掃描器可以抓到壞套件,卻不理解一個乾淨倉庫也能產生危險的 agent-facing control plane。若安全團隊不把它當成獨立類別處理,就會持續用錯工具。
你能做什麼
如果你是工程師或平台負責人,別再把 agent-facing CLI 當便利功能,應把它當成特權介面管理:對 AI agent 可呼叫的命令做 allowlist,將 generated CLI 納入和 deployment script 同等級的審查,並加上檢查 agent action plan 的政策層,而不只掃 repo 內容。若你是創辦人,把這件事寫進產品需求:每個 agent workflow 都要有 provenance、command boundary 與 audit log。OpenClaw 的教訓很直接,下一次供應鏈事件不一定從壞依賴開始,而是從一個「被信任的命令」開始。