Altera FPGA AI Suite 加入空間編譯器
Altera 的 FPGA AI Suite 26.1.1 加入空間編譯器,讓 Agilex FPGA 更適合低延遲邊緣 AI,還提供 100,000 次免費推論。
Altera 的 FPGA AI Suite 26.1.1 加入空間編譯器,讓 Agilex FPGA 更適合低延遲邊緣 AI。
說真的,這次更新很像在補一個老問題。AI 模型早就會跑了,難的是怎麼在機器人、工廠設備,或小型邊緣盒子裡穩定跑。
Altera 這版主打 FPGA AI Suite 26.1.1。它把模型映射到 Agilex FPGA 上,還支援最多 100,000 次連續推論的免授權操作。對想先驗證再上線的團隊,這數字很實際。
這篇在講的重點很單純。Altera 想把 FPGA 從「硬體玩家的工具」拉近到 AI 開發流程裡。講白了,就是讓模型部署少一點手工調校,多一點可重複性。
| 項目 | 數值 | 意義 |
|---|---|---|
| 軟體版本 | 26.1.1 | 加入空間編譯器支援 |
| 免費推論上限 | 100,000 次連續推論 | 適合測試與早期部署 |
| 發布日期 | 2026/05/01 | 新版工具鏈 |
| 目標硬體 | Agilex FPGA | 把 AI 工作負載映射到可程式化晶片 |
26.1.1 到底改了什麼
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
這版最重要的東西,是空間編譯器。它不是把推論當成一般軟體的直線流程,而是把神經網路拆成適合 FPGA fabric 的資料流。這種做法很吃架構,但在低延遲場景很有用。
你可能會想問,這和 CPU 或 GPU 差在哪。差在可預測性。邊緣 AI 常常不是拼最高 Token 數,也不是拼跑分,而是拼幾毫秒內要回應。對機器手臂、影像辨識、感測器警報來說,時間抖一下就可能出事。
Altera 的說法很直白。只要模型能表達成空間工作負載,FPGA 就能把運算平行化。這比把所有東西丟給通用處理器,再靠排程硬撐,來得更貼近實務。
- 把訓練好的模型映射到 FPGA,而不是只當一般程式跑
- 用 streaming dataflow 來降低延遲波動
- 適合視覺、影片分析、感測器處理與部分 LLM 邊緣推論
- 硬體可重編程,模型更新後不用整套換機器
為什麼邊緣 AI 團隊會在意
邊緣 AI 的麻煩很現實。裝置附近通常空間小,散熱差,電力也有限。你不可能每台設備都塞一張高功耗 GPU,然後期待它安靜又穩定地工作。
這時候 FPGA 的價值就出來了。它可以針對特定工作負載調整,效率通常比通用晶片更好。代價也很明顯,就是開發複雜度高,工具鏈如果不好用,工程師會直接翻白眼。
Altera 這次想解的,就是那個「不好用」的問題。它把空間編譯器放進來,等於是想讓模型到硬體的路徑少一點客製化腳本,多一點標準流程。
“As AI moves closer to the edge, developers need easy-to-deploy solutions that combine performance, efficiency and flexibility,” said Venkat Yadavalli, head of Altera’s business management group.
這句話講得很務實。真正難的不是模型能不能跑,而是能不能穩定出貨、能不能後續更新、能不能在不同環境維持一致表現。
如果你做的是工業自動化、智慧機器人,或感測器很多的設備,這類工具就不是玩具。它是在幫你把 AI 變成可交付的系統元件。
跟其他 AI 部署路線比起來
Altera 沒有叫你把現有流程整個砍掉重練。它支援 PyTorch、TensorFlow,也能接 OpenVINO。這點很重要,因為大多數團隊手上早就有訓練好的模型,不會想為了硬體重寫一輪。
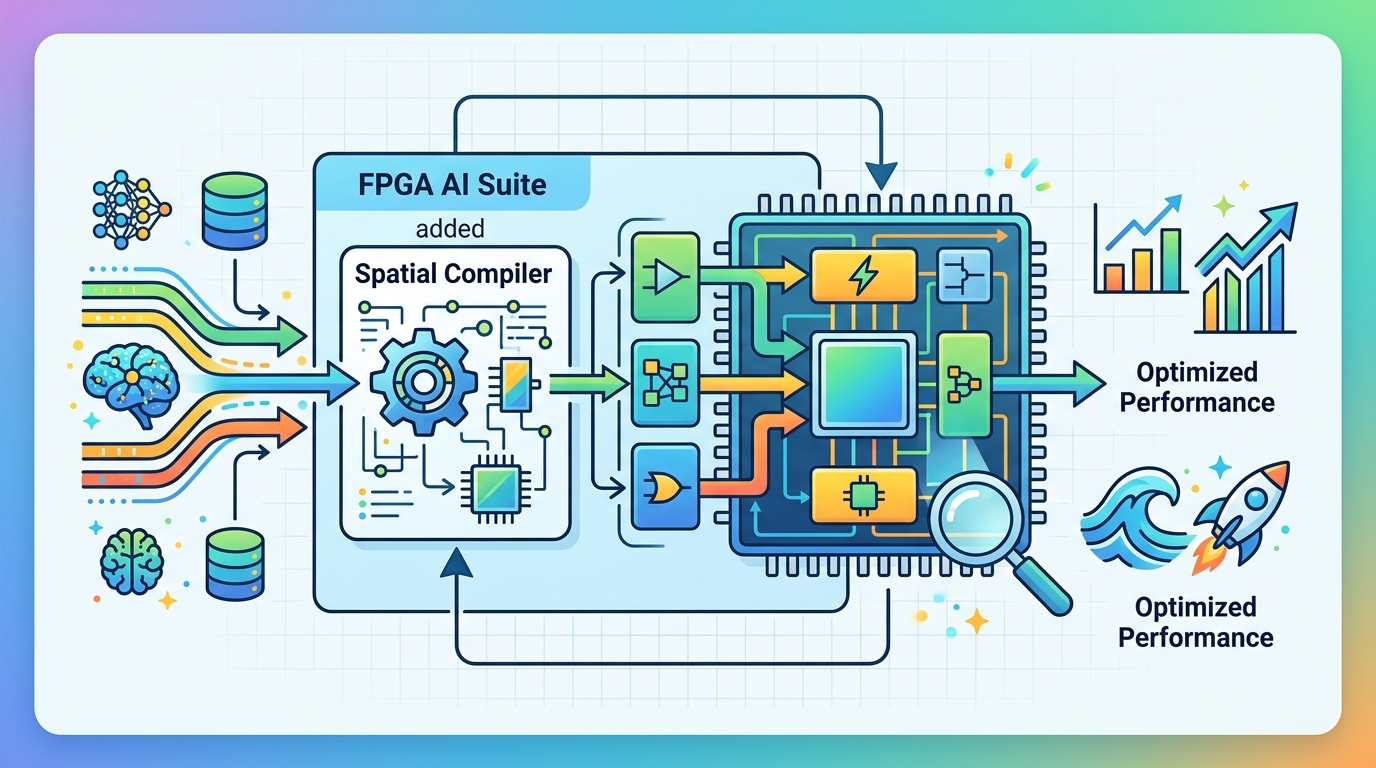
工具鏈這件事,常常比晶片規格更影響採用率。你硬體再漂亮,如果部署流程要靠一堆手動轉檔、手工調參、還要工程師熬夜 debug,最後還是會被 CPU 或 GPU 方案打回去。
Altera 也把 Quartus Prime Pro Edition 26.1 拉進來。這代表它不是單點工具,而是整套設計環境一起推。對熟 FPGA 的人,這很合理;對 AI 團隊,這就是門檻。
- 免授權推論上限是 100,000 次連續推論
- 支援 Agilex 系列,不是單一晶片方案
- 可接主流訓練框架,降低導入摩擦
- 適合看重延遲、功耗、確定性,而不是只看吞吐量的場景
再看市場位置,Altera 不是新玩家。它有大約 14,000 名客戶,員工約 3,000 人。這表示它有既有客戶群,也有把工具塞進真實專案的能力,不是只會發新聞稿。
這對產業代表什麼
我覺得這波很像 FPGA 廠商在補 AI 時代的門面。以前大家想到 FPGA,先想到邏輯設計、低延遲、客製化硬體。現在大家會先問,能不能直接跑模型,能不能接現成框架,能不能少一點痛苦。
這個方向有道理。因為邊緣 AI 的需求不是單一答案。工廠、車載、零售攝影機、醫療設備,每個場景都不一樣。GPU 很強,但不是每個地方都適合。CPU 很方便,但在某些延遲與功耗條件下會卡住。
所以真正的競爭,不是誰的模型名稱比較帥,而是誰能把部署成本壓低。誰能讓工程師少花 2 週在轉換流程上,誰就比較有機會進入量產。
背景脈絡:FPGA 為什麼又回來了
FPGA 這幾年又被拉回 AI 討論裡,不是因為它突然變新潮,而是因為場景變了。資料中心追求的是規模,邊緣裝置追求的是即時、低耗電、可控風險。
這也解釋了為什麼很多廠商開始把「編譯器」放到前面講。硬體本身不會自己變簡單,真正能縮短距離的,是把模型轉成硬體排程的工具做得更順。
如果你把這件事放到整個 AI 工具鏈來看,Altera 其實是在搶一個很實際的位置:把已經訓練好的模型,變成能在現場設備上穩定跑的版本。這比做一個漂亮 demo 難多了。
接下來該看什麼
下一步很簡單。不要只看官方說法,要看實測。特別是延遲、功耗、模型轉換時間,還有工程師要花多少時間把模型搬上去。
如果 Altera 的空間編譯器真的能把流程縮短,那它就不只是多一個功能。它會變成邊緣 AI 團隊評估 FPGA 時,會認真打開的工具之一。反過來說,如果部署還是很卡,那 100,000 次免費推論也只是試用門檻而已。
我會建議做邊緣 AI 的團隊,把它放進 POC 清單。先拿一個小模型試,量 latency,再看開發成本。這比空談硬體規格,實際多了。