分散式系統怎麼解商業問題
分散式系統不只是基礎設施。它能降低當機風險、支援跨區擴張,還能把複雜流程拆開,讓公司更好管。
一家服務一旦跨區、跨國,架構就不是工程細節。它直接變成成本問題。AWS、Google Cloud 這類平台,早就把多區部署當基本題。說白了,這不是炫技,是在買營運韌性。
你可能會想問,分散式系統到底在解什麼商業問題?答案很直接:降低單點故障、滿足資料落地規範、縮短延遲、讓團隊能分工。這些都會反映到營收、客訴、和事故處理時間。
我覺得很多公司卡住,不是因為技術太差,而是把「單一應用、單一資料庫、單一機房」當成萬靈丹。等流量一放大,這套做法就很容易爆。真的,爆得還不小。
分散式架構改變公司能做的事
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
分散式系統的核心,就是把工作拆到多個服務、多個區域、甚至多個資料庫。技術上看起來很複雜。商業上看起來卻很簡單:公司能在更多地方活下來,也能在更多地方賺到錢。
像 AWS、Google Cloud、DataStax,一直在推多區、複寫、容錯。這些詞很工程味,但買單的人通常在想三件事:能不能撐住、能不能擴、會不會違規。
例如一個電商平台,如果美東機房掛了,還能切到美西。這不是漂亮簡報。這是少掉一整天的營收損失。再加上資料區域化,台灣、歐盟、東南亞的法規也比較好處理。
Sunil Thamatam 在 ITOps Times 的文章裡提到一個實例。某服務把資料分散到多個區域,AWS 某區出問題時,系統切到備援區域。這種設計平常看不出價值。等主機掛掉,你就知道差多少。
- 多區路由可降低單一區域故障風險。
- 資料落地可幫助符合在地法規。
- 區域隔離可縮小事故影響範圍。
- 水平擴充可支援流量成長,不必整套重寫。
這些好處最後都會回到財務面。少一小時事故,可能就是少一筆客服賠償。少一次全站停擺,可能就是少掉數十萬甚至更多的損失。講白了,這是風險管理,不是架構潔癖。
隔離不是炫技,是在控風險
分散式系統最值錢的地方之一,就是故障隔離。單體系統很常見的問題是,一個慢查詢、一個 lock、一個記憶體洩漏,就能拖垮整站。這種事在 production 真的很煩,尤其是半夜。
拆成多個服務後,事情不一定變簡單,但風險會更可控。你可以讓支付、通知、搜尋、報表各自獨立。就算報表延遲,結帳還是能跑。就算通知服務掛掉,核心交易也不必停。
這也是為什麼 Cockroach Labs 和 MongoDB 這類公司,會把可用性和容錯講得很重。因為客戶買的不是資料庫名詞。客戶買的是少停機、快復原、少掉 SLA 壓力。
“Any sufficiently advanced technology is indistinguishable from magic.” — Arthur C. Clarke
這句話放在分散式系統很貼切。只要設計得好,使用者根本不會想到 replication lag、failover、queue backlog。對他們來說,系統就是「一直能用」。
Thamatam 也提到實驗成本這件事。新功能如果能先放在獨立服務裡,就比較不會把核心流程一起拖下水。這對產品團隊很實際,因為試錯成本會低很多。
複雜組織,反而更需要拆開
很多人看到分散式系統,第一反應是「更複雜吧」。對,元件變多了,網路呼叫變多了,監控也變麻煩了。但在大型公司裡,這種複雜常常是必要的。
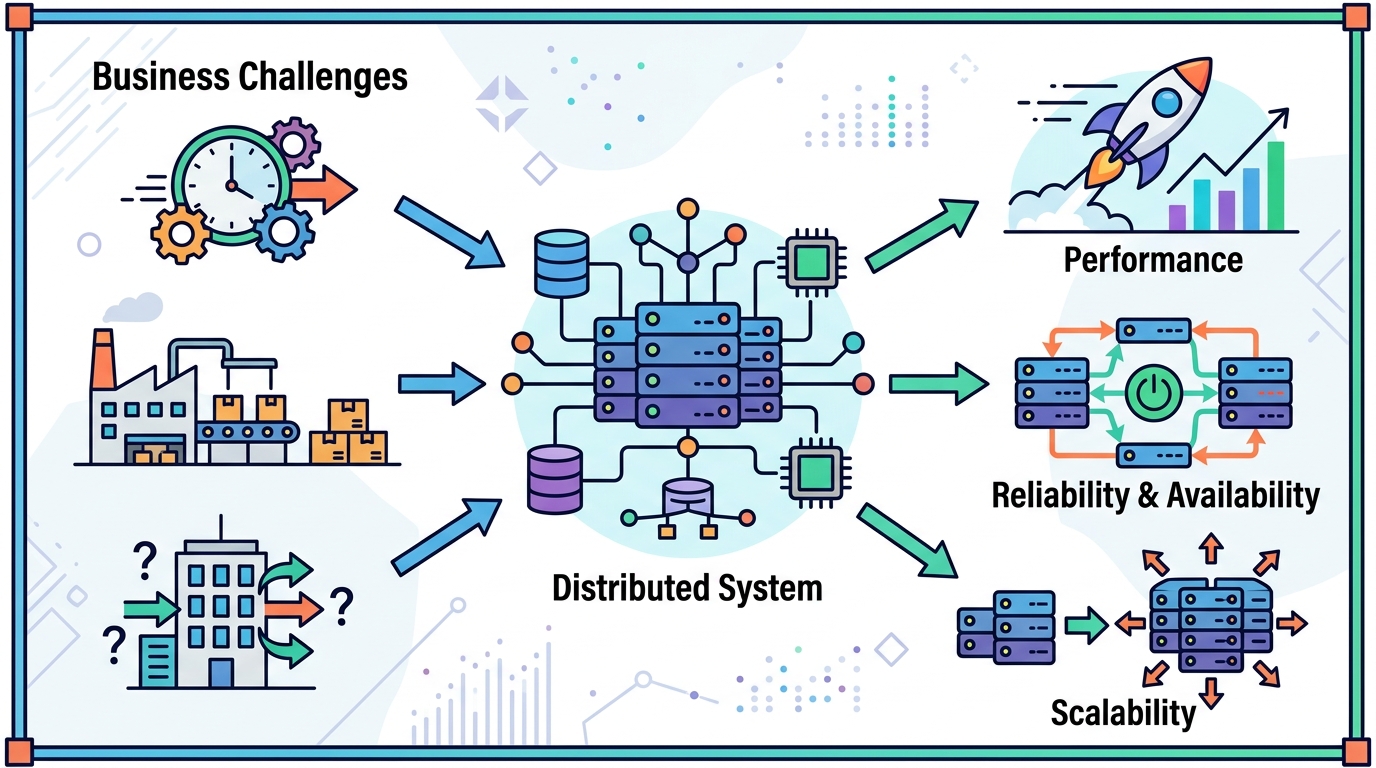
原因很簡單。身份驗證、金流、分析、搜尋、通知,這些模組變動速度本來就不一樣。如果全塞在同一個 codebase,每次改版都像在移動整棟房子。拆開之後,團隊可以各管各的,交付速度也比較穩。
這裡可以順便提 Conway’s Law。軟體常常長得像組織結構。團隊怎麼切,系統就怎麼切。與其硬把所有東西綁成一團,不如把邊界設好,讓架構跟組織一起工作。
- 身份服務可獨立演進,不必等金流改版。
- 搜尋服務可依流量單獨擴充。
- 分析服務可延遲,不影響前台下單。
- 通知服務故障時,核心交易還能繼續。
這種切法對 SaaS、金融、物流特別有用。因為這些產業的流程很長,牽涉的人也多。你如果沒有清楚邊界,事故時就會出現一堆「這到底誰負責」的鬼故事。
代價也很真實,數字要算清楚
分散式系統不是免費午餐。它會增加 latency,也會增加維運成本。你要管更多服務、更多 log、更多 alert。說真的,團隊如果沒有觀測能力,這套東西很快就會變成災難。
所以重點不是「要不要分散式」。重點是「值不值得」。如果一個平台每次當機都損失 20 萬台幣,能把停機時間從 45 分鐘壓到 5 分鐘,這就很有感。如果一個 API 能讓不同團隊各自發版,少掉 30% 的協調時間,也很有感。
你也可以看競品怎麼做。Kubernetes 很常拿來管理分散式工作負載,但它本身也增加操作難度。Confluent 主打事件流,換來更好的解耦,但也要接受資料流設計更複雜。這些工具沒有誰絕對最好,只有誰比較適合你的 SLA。
像 Uber 和 Netflix 這類公司,都是靠分散式架構處理大量請求。它們的共同點不是「系統很酷」,而是「不能停」。
- 分散式資料庫通常主打 99.9% 以上可用性。
- 事件驅動架構可降低服務耦合,但除錯更難。
- 多區部署可縮小故障半徑,但跨區同步成本更高。
- CAP 取捨不是理論題,是產品設計題。
這裡最重要的,是把一致性需求講清楚。有些場景可以接受 2 到 5 秒的資料延遲。有些不行,像付款、庫存、身份驗證。你不先講清楚,後面就會一路補洞,補到很累。
這其實是產業成熟度問題
分散式系統不是新名詞。只是現在雲端、API、容器、事件流都成熟了,大家才真的有能力把它落地。以前很多公司不是不想做,是做不起來。機房、網路、監控、備援,哪一項都很燒錢。
現在情況不一樣了。CNCF 把容器、service mesh、observability 這些工具慢慢整理成一套生態。OpenStack 也曾經推動私有雲的標準化。這些東西讓公司比較容易把分散式架構做成日常,而不是少數大廠專利。
台灣很多團隊現在也在走這條路。不是因為愛折騰,而是因為客戶要跨境、法規要分區、產品要 24 小時在線。當業務一變大,架構就不能只看「能不能跑」。還要看「出事時會不會整個倒」。
我覺得接下來 1 到 2 年,更多公司會把多區備援、事件驅動、服務拆分當成預設選項。不是每個系統都要拆到很碎,但只要是客戶面、金流面、資料敏感面,這件事就很難再裝沒看到。
最後,先問一個很現實的問題
如果你現在的主系統掛掉 30 分鐘,業務會損失多少?如果答案你算不出來,那就代表架構決策還沒跟商業風險對齊。這件事不酷,但很重要。
下一次做架構評估時,我會先看三件事:單點故障在哪裡、資料能不能分區、團隊能不能獨立交付。只要這三題答不出來,分散式系統就不是選配,而是遲早要補的功課。