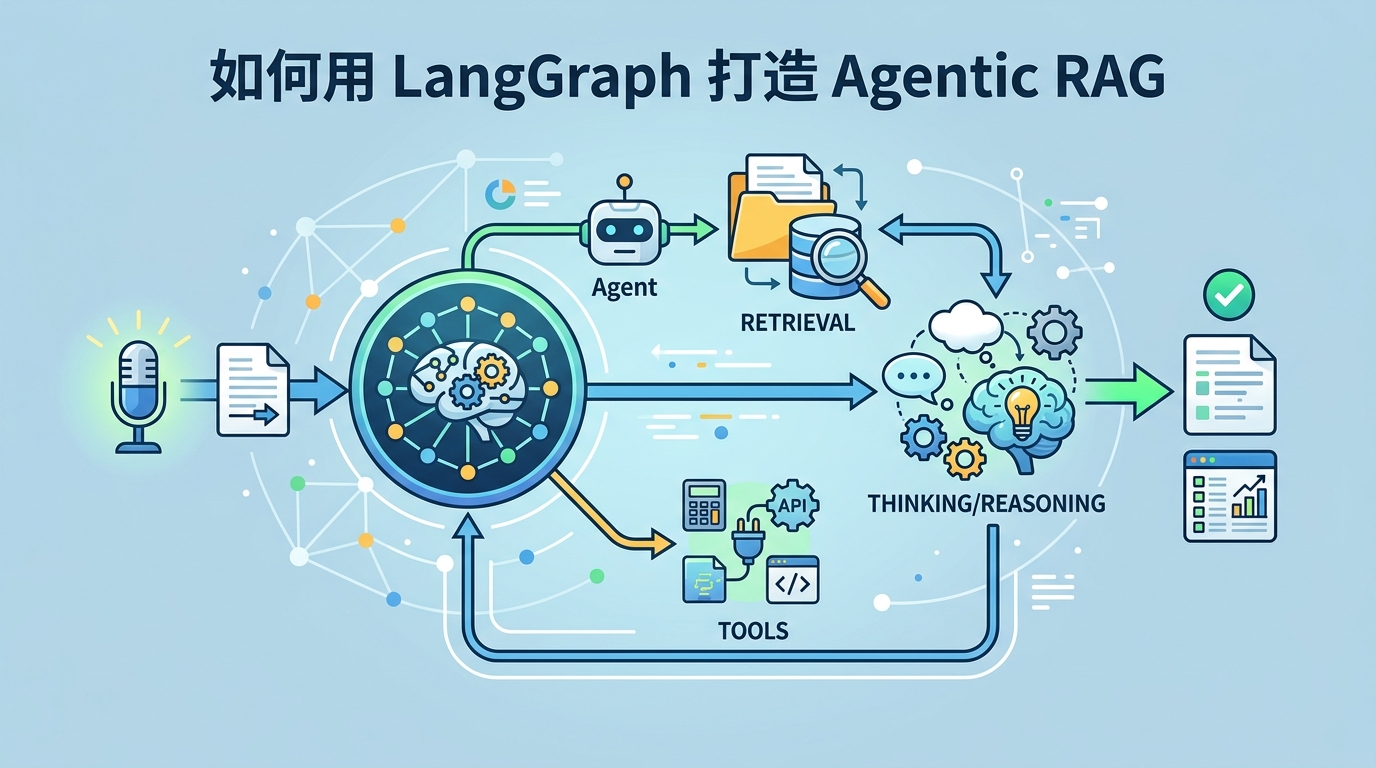
如何用 LangGraph 打造 Agentic RAG
這篇教你用 LangGraph 建立一個會路由、檢索、驗證並回答問題的 Agentic RAG 工作流。
這篇教你用 LangGraph 建立一個會路由、檢索、驗證並回答問題的 Agentic RAG 工作流。
這篇給想把傳統 RAG 升級成可決策系統的開發者。照著做完,你會得到一個可執行的 Agentic RAG 原型,具備查詢路由、工具呼叫、答案驗證與多來源檢索能力。
本文會用到 LangChain 官方文件、LangChain GitHub,以及 LangGraph 官方文件、LangGraph GitHub 來完成流程編排。
開始之前
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
- Node 20+,或 Python 3.11+
- OpenAI API key,或其他 LLM 供應商金鑰
- Chroma、FAISS,或其他向量資料庫帳號與本機環境
- 至少一個資料來源:文件、API、或網頁搜尋
- Git 已安裝,可用來複製起始專案
- 理解 embeddings、retrieval、prompt template 的基本概念
Step 1: 建立專案骨架
這一步的目的,是先做出一個本機專案骨架,讓你可以載入模型、呼叫工具,並保留檢索到的上下文。
建立新資料夾、安裝核心套件,並設定環境變數,讓模型金鑰與檢索後端都能被程式讀到。
mkdir agentic-rag-demo && cd agentic-rag-demo
npm init -y
npm install langchain @langchain/openai @langchain/community dotenv
# 若你偏好 Python,也可以改用 Python 3.11+驗收時,你應該看到專案資料夾、已安裝依賴,以及一個能成功讀取環境變數的測試結果,而不是驗證失敗。
Step 2: 建立文件索引
這一步的目的,是做出可搜尋的知識庫,讓 agent 不必只靠提示詞猜答案。
把文件載入後切成 chunks,產生 embeddings,再存進向量索引。若你使用 LlamaIndex,這裡就是把 PDF、網頁或檔案接到檢索層的地方。
// 具名產出:文件向量索引
loadDocuments();
splitIntoChunks();
embedChunks();
storeInVectorDB();驗收時,你應該看到對某個已知片段的相似度搜尋結果,且回傳的 chunk 帶有對應來源標記。
Step 3: 加入查詢路由
這一步的目的,是讓 agent 在檢索前先決定問題該走哪條路。
建立路由器,把查詢分類成文件查詢、網頁查詢、API 查詢,或直接回答。這個設計能讓後續擴充成多 agent 流程時更容易維護。
if (needsRealtimeData(query)) routeTo("api-tool");
else if (isInDocs(query)) routeTo("vector-search");
else routeTo("web-search");驗收時,你應該看到三種不同問題被導向不同路徑,例如政策問題、產品問題、即時資訊問題各走不同分支。
Step 4: 編排工具與檢索流程
這一步的目的,是把查詢修正、來源選擇、檢索與追問串成一個多步驟工作流。
你可以用 agent loop,或用 LangGraph state machine 來管理狀態。核心概念是:系統先規劃,再執行,再檢查結果,必要時重新嘗試。
state = {
query,
refinedQuery,
source,
context,
draftAnswer,
validationResult
}驗收時,你應該看到一個複雜問題會觸發兩次以上的步驟,例如先查文件,再呼叫即時 API,而不是直接吐出第一段檢索片段。
Step 5: 驗證最終答案
這一步的目的,是在答案送出前先做品質檢查,避免弱證據或無根據的回覆。
加入驗證層,比對草稿答案、原始查詢與檢索上下文。如果證據不足,系統就應該再取更多 context、重寫答案,或回傳安全的 fallback。
if (!isSupported(draftAnswer, context)) {
draftAnswer = refineAndRetry(query, context);
}驗收時,你應該看到模糊問題會被要求補充資訊,而證據充足的問題則會輸出帶有依據的答案。
Step 6: 擴充多模態輸入
這一步的目的,是把文字、圖片與即時資料放進同一條 Agentic RAG 流程。
加入 OCR、影像描述或即時資料抓取工具,再把不同輸入型態導向對應的 agent。這會讓 Agentic RAG 比傳統 RAG 更有彈性,因為它能依來源類型改變檢索策略。
// 具名產出:多模態工具組
textRetriever();
imageCaptionTool();
realtimeApiTool();驗收時,你應該看到文字查詢、圖片查詢與時間敏感查詢各自走出不同檢索路徑,最後產生符合上下文的答案。
常見錯誤
- 把所有問題都送進向量庫。修法:先做來源分類,避免即時問題拿到過時文件。
- 跳過驗證步驟。修法:把最終答案和檢索證據比對,不足就重試或回退。
- 一開始就切太多 agent。修法:先做一個 router 和一個 retriever,流程穩定後再拆分角色。
接下來可以看什麼
下一步可以深入 memory、平行子 agent 與評測集,進一步比較 routing 準確率、答案品質與延遲,建立可持續迭代的 Agentic RAG 系統。