NVIDIA Rubin 把六顆晶片塞進 AI 機櫃
NVIDIA 在 CES 2026 端出 Rubin 平台,主打推論 Token 成本最高可比 Blackwell 低 10 倍,MoE 訓練可少用 4 倍 GPU。重點不只是一顆新 GPU,而是把 CPU、網路、DPU、交換器整包賣成機櫃級 AI 系統。
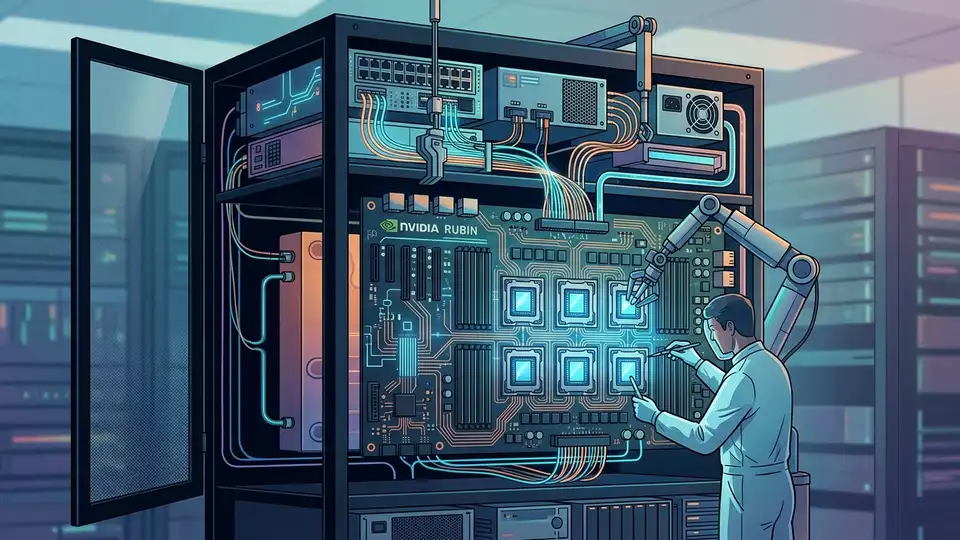
NVIDIA 在 CES 2026 端出 Rubin,先丟兩個很大的數字。官方說,推論每個 Token 的成本,最高可比 Blackwell 低 10 倍。訓練 mixture-of-experts,也就是 MoE 模型,GPU 用量可降到原本的 1/4。
講白了,這次重點不是單一晶片跑多快。NVIDIA 想賣的是整套 AI 基礎設施。從 CPU、GPU、網卡、DPU 到乙太網路交換器,全部綁在一起賣,直接變成機櫃級產品。
這個時間點也很現實。前兩年大家都在比誰能訓練更大的模型,現在麻煩的是推論成本。模型上下文越拉越長,推理步驟越來越多,電費和伺服器成本也跟著往上噴。Rubin 就是 NVIDIA 給這個問題的答案。
Rubin 不是一顆晶片,是整疊系統
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
先講清楚,Rubin 不是只有 GPU。它是一個六晶片平台,核心元件包含 Vera CPU、Rubin GPU、NVLink 6 switch、ConnectX-9 SuperNIC、BlueField-4 DPU、Spectrum-6 Ethernet switch。這六個東西一起上,才是 NVIDIA 定義的 Rubin。

這種做法反映一個現實。現在 AI 叢集的瓶頸,早就不是只有 GPU 算力。資料搬移、節點互連、記憶體重用、租戶隔離、維修時間,哪一個卡住都會拖垮整體吞吐。
所以 NVIDIA 這次的說法很直接。與其讓客戶自己拼裝零件,再慢慢找瓶頸,不如一開始就把運算、網路、安全和服務性一起設計。你可以不喜歡這種綁定,但說真的,這招對大客戶很有吸引力,因為省掉很多整合成本。
- Rubin 推論每個 Token 成本,官方稱最高比 Blackwell 低 10 倍。
- MoE 訓練可用比前代少 4 倍的 GPU。
- 每顆 Rubin GPU 具備 3.6 TB/s 的 NVLink 頻寬。
- Vera Rubin NVL72 機櫃總 NVLink 頻寬達 260 TB/s。
- Rubin GPU 在 AI 推論可達 50 petaflops 的 NVFP4 算力。
- 合作夥伴產品預計在 2026 下半年出貨。
包裝方式也很關鍵。NVIDIA 會提供 Vera Rubin NVL72 機櫃級系統,以及 HGX Rubin NVL8 系統。你看到 NVL72 這種命名,大概就知道 NVIDIA 押注在哪裡。它想賣的是整櫃,不只是加速卡。
這背後的商業邏輯很清楚。單賣 GPU,客戶還能拿別家的網路、CPU 或管理軟體來拼。整櫃賣出去後,NVIDIA 吃下的就不只是晶片毛利,還包括機櫃設計、互連、軟體堆疊和維運工具。對客戶來說,彈性變少,但交付速度通常會更快。
對台灣讀者來看,這也代表供應鏈重心繼續往系統整合移動。未來比的不是誰能做出一片板卡,而是誰能把散熱、電源、機櫃、交換器和伺服器模組一起交付。ODM、散熱、機殼、電源廠都會被捲進來。
為什麼 NVIDIA 現在一直講推論
過去兩年,硬體發表會很愛講訓練大模型。到了 Rubin,主軸明顯變了。NVIDIA 開始一直強調 reasoning、agentic workloads,還有長上下文。這些工作負載的共同點,就是模型會花更多時間吐 Token,而不是只做一次前向運算。
你可能會想問,這有差很多嗎。差非常多。當推論變成主要成本,硬體採購就不會只盯著峰值 FLOPS。大家更在意的是每個 Token 到底要多少錢、能耗多少、延遲多少,還有同時服務多少使用者。
Rubin 也順手帶出一個新東西,叫 Inference Context Memory Storage Platform,底層由 BlueField-4 驅動。名字很長,意思其實不難懂。它想更有效率地保存和共享 key-value cache,也就是模型在長上下文推論時很吃重的那塊記憶資料。
這件事很技術,但商業價值很直接。若 cache 能重用,模型就少做很多重複工作。延遲會降,吞吐會升,伺服器利用率也會比較好看。對提供 AI API 的公司來說,這不是小優化,是直接影響毛利的問題。
“Intelligence scales with compute. When we add more compute, models get more capable, solve harder problems and make a bigger impact for people. The NVIDIA Rubin platform helps us keep scaling this progress so advanced intelligence benefits everyone.”
Sam Altman, CEO of OpenAI
Sam Altman 這段話很符合 NVIDIA 想傳達的訊息。模型公司嘴上會談效率,實際上還是持續追更多算力。因為成本降下來後,他們通常不會省起來,而是拿去換更長上下文、更多使用者、更多推理步驟。
這也是 Rubin 的核心賭注。不是單純讓你省錢,而是讓你把省下來的錢,再灌回模型服務裡。只要這個循環成立,NVIDIA 就有理由繼續賣更大的系統。
另外,NVIDIA 這次也比平常更用力講安全和穩定性。Rubin 支援第三代 confidential computing,範圍跨 CPU、GPU 和 NVLink。還有第二代 RAS 引擎,負責健康檢查和容錯。對共享 AI 基礎設施的雲端業者來說,這些不是附加功能,是基本門檻。
和 Blackwell 比,Rubin 紙面數字差在哪
NVIDIA 這次最想讓大家記住的比較,就是 Rubin 對 Blackwell。當然,這些數字目前多半還是官方口徑,真正上線後還要看實測。但方向已經很明顯。Rubin 主打的是大規模推論與 MoE 的經濟效益,不只是更高峰值性能。

先看最醒目的數字。推論每個 Token 成本,官方說最高可降到 Blackwell 的 1/10。若這個數字接近真實部署結果,很多 AI 服務商的定價策略都得重算。因為 Token 成本一下掉這麼多,API 價格、上下文長度、免費額度都可能跟著調整。
再來是 MoE 訓練。NVIDIA 說,同級模型可用 4 倍更少的 GPU。這點很重要,因為現在很多大模型都在用 MoE 架構。原因很簡單,參數可以做大,但每次只啟用部分專家,算力比較省。若 Rubin 真的能把訓練叢集縮小到這種程度,機房規劃會輕鬆很多。
- 推論 Token 成本:官方稱最高比 Blackwell 低 10 倍。
- MoE 訓練 GPU 數量:官方稱可比 Blackwell 少 4 倍。
- 組裝與維修速度:模組化無線纜托盤設計,官方稱最高快 18 倍。
- Spectrum-X Ethernet Photonics:官方稱電力效率與 uptime 可提升 5 倍。
這些數字放在一起看,你會發現買家評估方式也在變。以前大家很愛問單卡多少 TFLOPS,現在更常問整櫃能吐多少 Token、耗多少電、壞一台要修多久、管理軟體順不順。NVIDIA 很清楚這點,所以 Rubin 直接把網路、儲存、安全、管理全部包進來。
還有一個戰略層面的重點。Hyperscaler 自研晶片一直在進步,Google 有 TPU,AWS 有 Trainium 和 Inferentia,Microsoft 也有 Maia。這些產品都在分食市場。NVIDIA 的優勢,越來越不是單點晶片性能,而是整套系統整合能力。
我覺得這也是 Rubin 最狠的地方。當性能表現越來越依賴 CPU、GPU、交換器、NIC、DPU 和軟體怎麼配合,客戶就更難隨便混搭替代方案。你當然可以自己拼,但時間成本、驗證成本、效能損失都可能很痛。
誰會先買單,競爭對手又在哪
NVIDIA 公布了一長串合作夥伴名單。AWS、Google、Microsoft、Meta、OpenAI、Anthropic、Oracle、Dell、HPE、Lenovo、CoreWeave、xAI 都在上面。這份名單的意義,不是比人氣,而是告訴市場,大買家現在還是照著 NVIDIA 路線圖排產能。
Microsoft 這次給的訊息算具體。NVIDIA 表示,Microsoft 下一代 Fairwater AI superfactories 會採用 Vera Rubin NVL72,規模上看數十萬顆 Vera Rubin Superchips。若進度沒拖,Rubin 很快就會進入市場上最大的 AI 叢集之一。
CoreWeave 也說,會透過 Mission Control 平台提供 Rubin。這件事值得看。因為 neocloud 通常比傳統企業供應商更快導入新硬體。若有人想早點試 Rubin 跑推論,CoreWeave 這類業者很可能會是第一批真實戰場。
- NVIDIA:優勢在 CUDA、生態系、整櫃交付能力。
- Google TPU:自家服務整合強,但外部採購彈性有限。
- AWS Trainium / Inferentia:雲端成本控制有優勢,軟體遷移門檻較高。
- AMD Instinct:硬體追得快,但整體生態和部署規模仍在追趕。
Red Hat 和 NVIDIA 的合作也不能忽略。很多企業導入 AI,最後卡的不是晶片規格,而是 Linux 支援、容器編排、隔離機制、生命週期管理這些很無聊但很重要的細節。沒有這層軟體,Rubin 很難從超大模型實驗室,擴散到更廣的企業市場。
對競爭對手來說,Rubin 的麻煩點在於它把戰場往上拉。以前大家還能在加速卡這層對打,現在 NVIDIA 要比的是整個 rack-scale system。你若沒有完整網路、DPU、軟體、維運工具,就很難用單點產品跟它打。
不過這也不是說 Rubin 一定穩贏。NVIDIA 的平台越完整,客戶鎖定風險也越高。大型雲端業者不會喜歡把命脈全交給單一供應商。所以接下來幾年,市場很可能會出現一種矛盾狀態:一邊大量採購 NVIDIA,一邊拼命投資自研晶片和替代方案。
背後的產業脈絡:AI 基礎設施正在機櫃化
如果把時間拉長來看,Rubin 不是突然冒出來的產品。它延續了 NVIDIA 這幾年的一條主線:把 AI 基礎設施的銷售單位,從單卡變成伺服器,再從伺服器變成機櫃。接下來,甚至可能直接用資料中心 pod 當單位來賣。
這樣做的原因很現實。AI 叢集規模越大,系統層問題越多。你今天多塞幾十張卡,不代表吞吐就線性上升。散熱、供電、交換器拓撲、線材管理、故障隔離,每一項都可能拖慢部署。整櫃方案雖然比較綁,但能把很多工程麻煩前置處理。
對台灣供應鏈來說,這波變化很值得注意。過去伺服器代工是核心,現在散熱、液冷、機櫃、背板、電源、光通訊的角色都變重。因為當客戶買的是整櫃 AI 系統,零組件廠的價值就不再只看單價,而是看能不能穩定交付和維修。
另一個背景是推論工作負載真的在變。以前聊天機器人生成幾百個 Token 就算多,現在很多 agent 會做多輪推理、查工具、拉文件、再回頭整理答案。每次都在燒 Token,也在燒頻寬和快取。這種工作負載,剛好就是 Rubin 鎖定的場景。
還有電力問題。大型 AI 叢集現在最常見的抱怨,不是買不到 GPU,而是資料中心沒足夠電力和散熱餘裕。若 Rubin 的整體效率真能接近官方說法,那它的價值就不只是更快,而是讓同一座機房能塞進更多有效產出。這對雲端業者非常重要。
當然,官方數字永遠要保留一點懷疑。10 倍 Token 成本改善聽起來很猛,但實際結果會受模型大小、量化方式、batching、快取命中率、網路配置影響。不同客戶跑出來的數字,可能差很多。這也是為什麼第一批部署案例特別值得追。
我的看法:2027 容量規劃會先被改寫
我覺得 Rubin 第一波還是會先進 hyperscaler、模型公司,還有資金夠厚的雲端服務商。企業市場不會這麼快全面跟上,因為價格、供貨、軟體支援都要時間穩定。真正比較有機會碰到 Rubin 的一般開發者,可能還是先透過雲端 API 或租用平台。
但如果 NVIDIA 的 10 倍 Token 成本說法,最後能做到 5 倍左右,市場就已經會很有感。很多原本照 Blackwell 規劃的 2027 年容量模型,可能今年就要重算。因為推論成本一旦往下掉,大家第一反應通常不是省錢,而是把模型開得更大、上下文拉得更長、服務賣得更便宜。
如果你是開發者,我的建議很簡單。先別急著看 petaflops 這種漂亮數字。你更該盯的是 Token 成本、長上下文延遲、KV cache 管理、網路拓撲,還有供應商能不能穩定交付。接下來一年,AI 基礎設施的勝負,八成會在這些細節上分出來。
如果你是企業採購,問題也很直接。你要的是最強單卡,還是最省事的整櫃。你能接受多高的供應商綁定。你有沒有能力自己整合替代方案。這些問題,現在就該開始問,別等到 2026 下半年產品真的開賣才手忙腳亂。
Rubin 這次傳達的訊號很清楚。AI 硬體競爭,已經不只是晶片規格表大戰。接下來比的是誰能把整個系統做得更能賺錢、更好維修、更容易擴張。NVIDIA 現在押的,就是這一局。