為什麼微軟的 agentic 安全模型贏過單一模型 AI
微軟這次站對邊了:真正能找出漏洞的,不是單一模型,而是多模型、可驗證、能證明結果的 agentic 安全系統。
真正有效的 AI 安全研究,靠的是多模型 agentic 流程,不是單一模型聊天式掃描。
微軟這次不是在秀 demo,而是在定義 AI 安全研究該怎麼做:先用多模型流水線做候選發現,再驗證、去重、交叉辯論,最後才把結果當成有效訊號。公司宣稱,MDASH 找到 16 個 Windows 網路與驗證漏洞,其中包含 4 個 Critical 等級的遠端程式碼執行漏洞;在 CyberGym 這個收錄 1,507 個真實漏洞的公開基準上,它拿下 88.45% 的成績。重點不只是分數高,而是它證明了安全研究的勝負手不是一顆更大的模型,而是一套能把懷疑變成證據的系統。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
安全工作需要系統,不需要一個會講話的提示詞。微軟描述 MDASH 時明確說,它運行超過 100 個專門 agent,分工涵蓋目標準備、候選路徑掃描、可達性驗證、等價結果去重,以及在可能時進一步證明可利用性。這種流程和真正的漏洞研究高度一致。資深研究員不會看完程式碼就直接宣告 exploit 成功,AI 也不該這樣做;從「懷疑」到「證明」之間,差的就是一條可追溯的工作鏈。
StorageDrive 的測試把這件事講得更清楚。微軟在一個私有 driver 裡預埋了 21 個漏洞,MDASH 宣稱全部找出,而且是 0 個 false positive。這不是漂亮而已,這是可用。因為在資安團隊裡,誤報不是小問題,它會吃掉 triage 時間、消耗信任,還會把真正高風險的問題埋進噪音裡。能在未見過的程式碼上維持精準度,才有資格進入工程流程。
第二個論點
單一模型不是問題的解法,模型編排才是。微軟的做法很直接:用 frontier model 當重推理引擎,用 distilled model 做高吞吐量掃描,再用另一個 frontier model 當獨立反方。這個架構才是突破點。資安裡,模型彼此不同意不是故障,而是訊號。如果一個模型指出一條攻擊路徑,另一個模型又無法有效反駁,那這個發現就更值得信任。這比起相信「哪個模型講得最像真的」要可靠得多。
數據也支持這個判斷。微軟聲稱,MDASH 對 clfs.sys 五年來已確認的 MSRC 案例達到 96% recall,對 tcpip.sys 則是 100%,而且在 CyberGym 上的分數比第二名高出約 5 分。這些不是展示用數字,而是說明多模型流程能跨越真實歷史漏洞,而不是只在玩具題或精心設計的測試裡表現好。對防守方來說,這代表它有機會真正嵌入工程工作流,隨著程式碼、模型與攻擊面變動持續產生價值。
反方可能怎麼說
最強的反對意見很簡單:這仍然是微軟替自己打分。它擁有程式碼、基準故事、驗證管線和發布敘事。私有 codebase 與預埋漏洞,終究不同於外部真實世界那種混亂、敵意、不可控的環境。供應商可以把系統調到最適合自己的場景,卻仍然錯過開源生態、第三方軟體或攻擊者自適應情境裡最重要的 bug。再加上成本問題,100 多個 agent、多模型、插件、證明階段與人工監督,聽起來都比單一模型掃描更貴也更複雜。
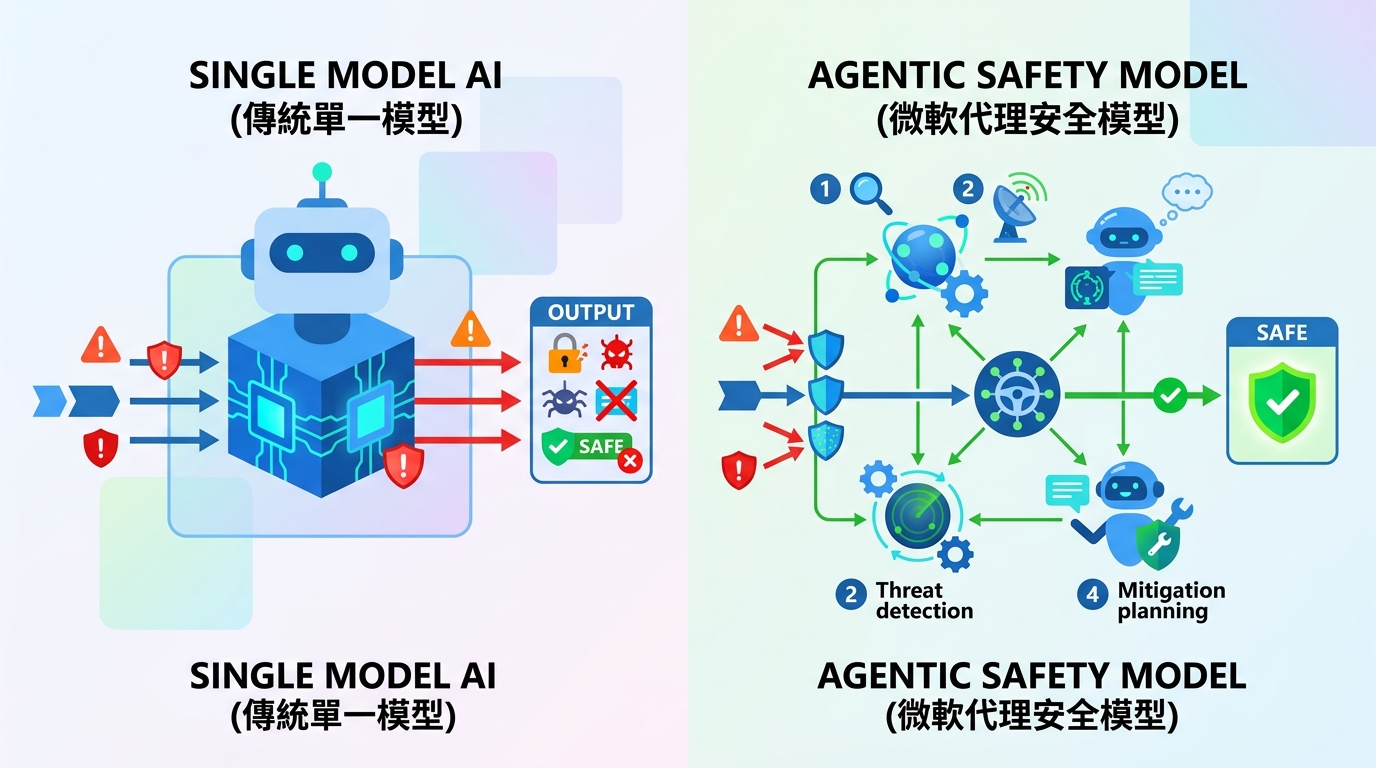
這個質疑成立,但不足以推翻結論。資安不是比誰最優雅,而是比誰能在不淹沒團隊的前提下找出可利用漏洞。微軟並沒有宣稱 MDASH 能取代人類或所有掃描器,它反而在證明:模型只是其中一部分,真正讓模型有用的是 harness。當系統能在植入漏洞上做到高 recall、0 false positive,還能在實際出貨到數十億用戶的生產 codebase 裡交出 proven findings,額外的複雜度就有其正當性。資安裡,能工作的複雜系統,勝過只會猜的簡單系統。
你能做什麼
如果你是工程師、PM 或創辦人,別再把 AI 資安工具當成「模型好不好」的問題。你該問的是:它怎麼驗證結果、怎麼去重、怎麼證明可利用性、用了哪些 agent、以及模型更新後管線怎麼維持穩定。若你在做這個領域的產品,請學的是操作邏輯,不是行銷話術:把系統做成多階段,把分歧變成訊號,把證明當成終點。MDASH 給出的教訓很直接,AI 資安要變成真實能力,靠的是一支紀律嚴明的研究團隊式系統,不是一個單獨的自動完成功能框。