為什麼 Adala 是看錯資料標註的方式
Adala 很有用,但它不是標註革命,而是把監督式資料工作做得更順的工作流層。
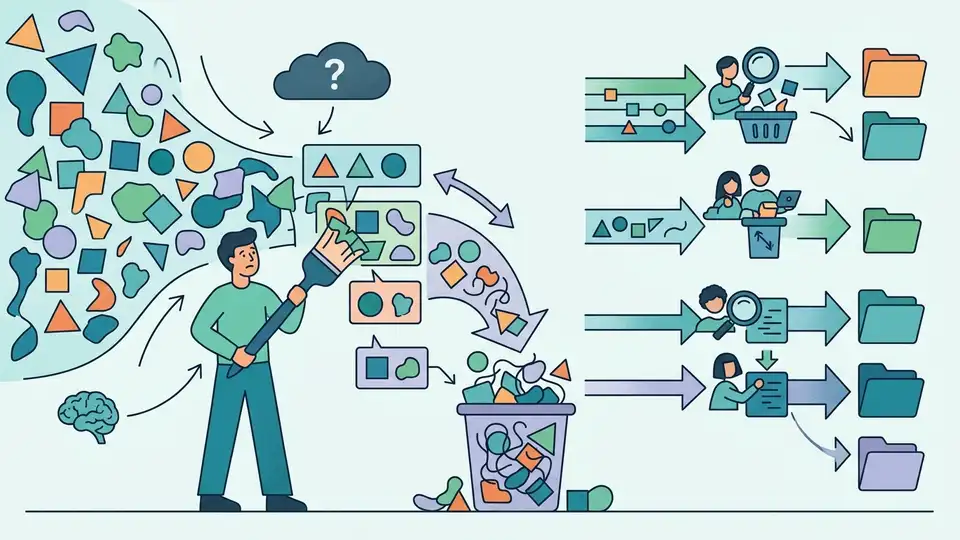
Adala 很有用,但它不是標註革命,而是把監督式資料工作做得更順的工作流層。
Adala 看起來像在做自動標註,實際上它做的是把 LLM、ground truth 與迭代評估包成一個乾淨的 Python 工作流。這件事重要,因為資料標註真正難的從來不是點得更快,而是定義標籤、維持一致性、把輸出綁回已驗證的樣本。Adala 沒有消滅這些工作,它只是把它們制度化。
第一個論點
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
Adala 解的是流程瓶頸,不是人類判斷瓶頸。文章裡的典型做法很直接:安裝套件、指定資料集、設定 API key,再用已標記樣本訓練 agent。這對團隊很有價值,因為大量時間本來就耗在把雜亂文字轉成結構化標籤。若一個 Python 原生介面能把中段流程自動化,省下的是真工時,不是想像中的自治智能。
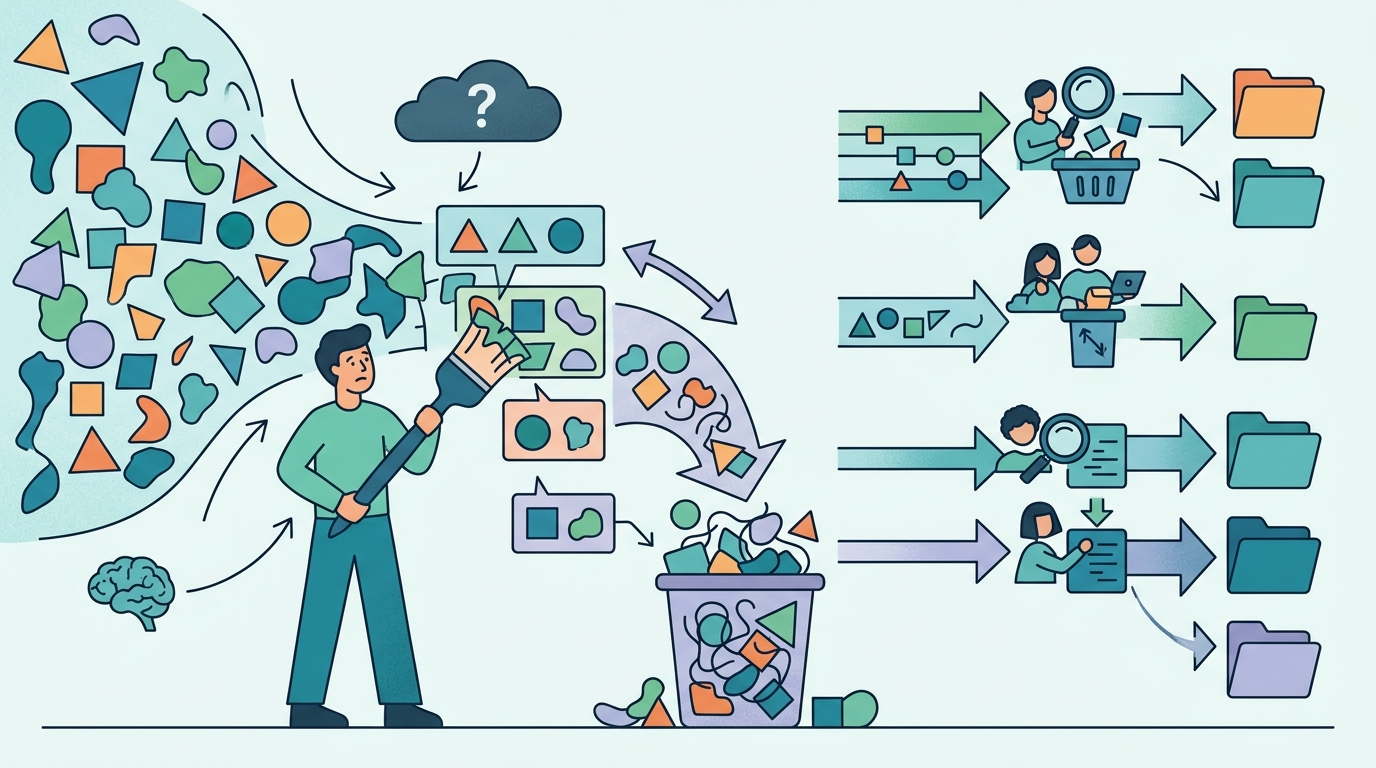
但這個價值建立在 ground truth 之上,而 ground truth 不會因為有了框架就消失。文章明確指出,Adala 會用已驗證的例子錨定行為,並拿表現去對照它們。這不是附註,而是核心。如果你的標籤本身有偏差、缺漏或定義不清,agent 只會把這些問題放大。換句話說,Adala 加速的是標註工作,不是取代高品質監督。
第二個論點
它最好的技術點,是 student/teacher 的設計,但這仍然是編排,不是新智能。teacher model 可以引導較便宜的 student model,而同一套技能又能跑在 OpenAI、VertexAI 或自建 endpoint 上。對於要在品質與成本間取捨的團隊,這是務實架構。像情緒分類、文件擷取這類重複任務,強模型先 bootstrapping 弱模型,確實能降低成本。
但這種做法本質上是 orchestration。文章列出的例子,仍然都是熟悉的監督式任務:評論分類、內容審核、醫療標註、財務欄位擷取、商品目錄補全。這些工作重要,卻不新鮮。Adala 的成功在於把它們包裝得更容易部署與重用,而不是改變工作的本質。把這稱為自主突破,會高估產品;更準確的說法是,它是一個更好的 LLM 輔助標註控制層。
第一個論點
真正適合 Adala 的,是高量、規則重、標籤空間明確的標註工作。看它自己舉的案例就知道:情緒分析、內容審核、醫療註記、財務抽取、商品目錄補全。這些任務都有清楚的 business schema,也需要一致性。若團隊面對的是數千或數百萬筆樣本,Adala 可以標準化輸出、減少重複人工複核,並把模型行為拉回政策或領域規則。

這也清楚畫出它的邊界。一旦任務變得模糊、充滿政策判斷或高度依賴上下文,自動標註的承諾就會變脆弱。模型可以從例子學模式,卻不能替你發明邊界案例的業務定義。如果審核政策不清、醫療 ontology 不穩、或財務團隊對「重大變動」沒有一致標準,任何 agent 框架都無法解決,只會更快複製分歧。Adala 是清晰度的放大器,不是清晰度的替代品。
第二個論點
支持者會說,這正是 Adala 的意義所在。多數企業 AI 專案失敗,不是因為模型太弱,而是因為資料準備太慢、太貴、太不一致。從這個角度看,把已標記樣本轉成可重用技能的框架,就是一個真正的生產力躍升。文章也把這點說得很清楚:同一個 skill 能跨 runtime 部署、agent 能迭代學習、輸出又能被約束在 taxonomy 內。對於被標註 backlog 壓垮的團隊,這確實是實質改善。
但這個論點對痛點的描述是對的,對解法的描述卻過頭了。Adala 並沒有消除瓶頸,而是把瓶頸往上游推到資料設計、評估與治理。這依然是好事,因為人力本來就應該集中在這些地方;只是這代表它是給紀律型團隊用的基礎設施,不是繞過專業的捷徑。把它當成自動勞動,你會得到脆弱的標籤;把它當成一套有主見的監督式資料系統,它就很有用。
反方可能怎麼說
反方會主張,Adala 之所以重要,正是因為它把標註工作從手工流程變成可重用的技能。對很多企業來說,真正卡住專案的不是模型能力,而是資料準備。從這個角度看,一個能把標記例子變成可部署流程的框架,確實是生產力工具,而不是單純的包裝層。尤其當一個 skill 可以跨模型執行、還能迭代改善時,它看起來就不只是工作流,而是新的資料基礎設施。
這個說法有一半是對的。Adala 的確值得重視,因為它把人力應該投入的地方,重新集中到 taxonomy、評估與治理上。真正需要反駁的是「自動化就等於取代判斷」這件事。標註工作最貴的部分,從來不是執行,而是定義與校準;如果你把這些問題外包給 agent,只會把錯誤規模化。它不是在消滅專業,而是在要求你更早、更嚴格地使用專業。
你能做什麼
如果你是工程師或資料科學家,只有在任務重複、schema 明確、而且已有可信標籤時才用 Adala。先縮小 taxonomy,固定模型版本,用保留測試集衡量效果,再看失敗案例後才擴大規模。如果你是 PM 或創辦人,不要把它包裝成取代標註團隊的 AI。把它說成降低標註成本、標準化輸出、把人工審核轉成例外處理的工具,才是誠實也更能落地的說法。