Why Adala Is the Wrong Way to Think About Data Labeling
Adala is useful, but it is not a labeling revolution; it is a workflow layer for supervised data work.

Adala is a workflow layer for supervised data labeling, not a replacement for human judgment.
Adala looks impressive because it promises autonomous labeling, but the real story is narrower: it packages LLMs, ground truth, and iterative evaluation into a clean Python framework for supervised data work. That matters, because the hard part of labeling has never been clicking faster; it has been defining the taxonomy, preserving consistency, and keeping outputs tied to verified examples. Adala does not erase that work. It formalizes it.
First, Adala solves a real bottleneck, but only by admitting the bottleneck still exists
Get the latest AI news in your inbox
Weekly picks of model releases, tools, and deep dives — no spam, unsubscribe anytime.
No spam. Unsubscribe at any time.
The strongest case for Adala is operational. The article shows a typical workflow: install the package, point it at a dataset, set an API key, and train an agent against labeled examples. That is valuable because teams already spend huge amounts of time turning messy text into structured labels, and a framework that can automate the repetitive middle of that process saves real labor. The win is not magic autonomy. The win is that a Python-native interface lowers the cost of building a labeling pipeline.
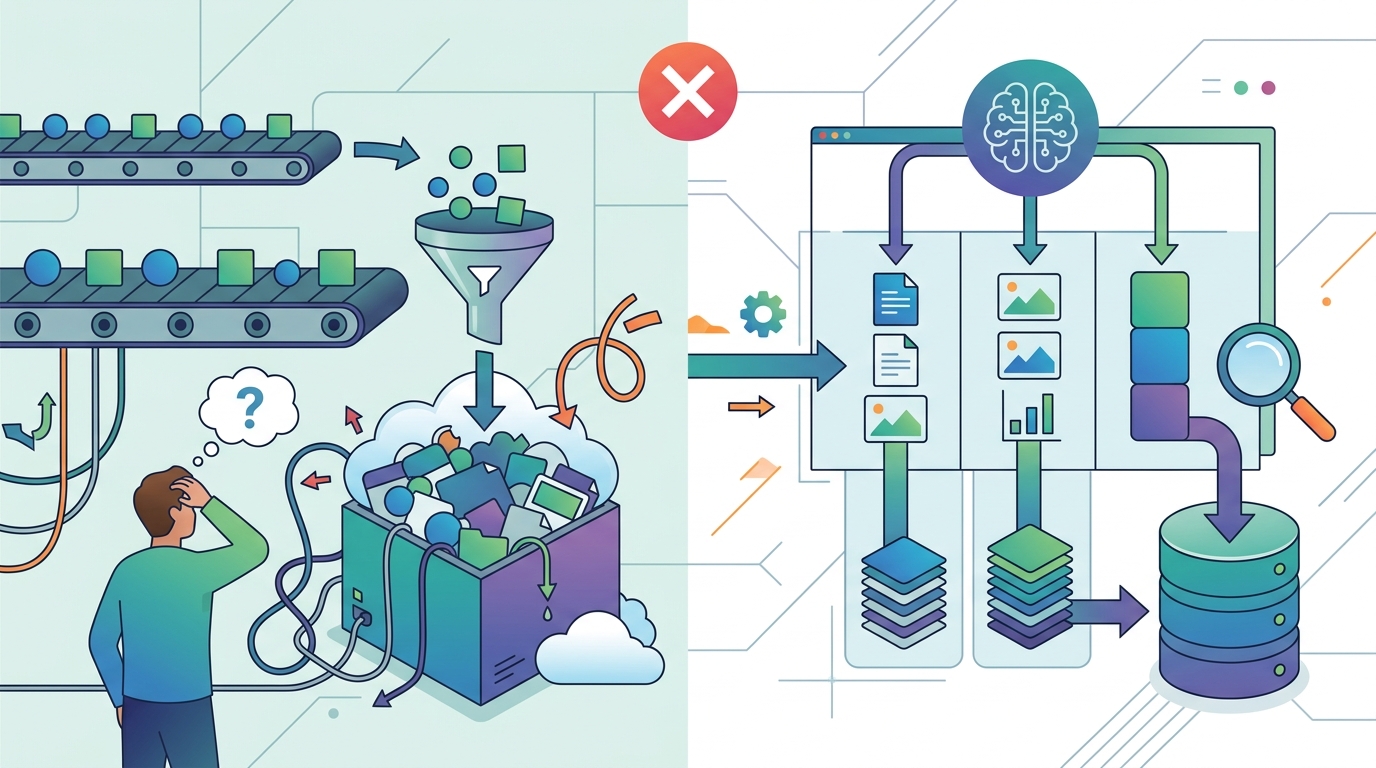
But the framework’s value depends on a thing that never goes away: ground truth. The article is explicit that Adala anchors behavior in validated examples and measures performance against them. That is not a side note, it is the entire foundation. If your labels are weak, biased, or incomplete, the agent learns those flaws at scale. In other words, Adala accelerates labeling work, but it does not remove the need for high-quality supervision.
Second, the student/teacher design is practical, not revolutionary
Adala’s runtime abstraction is the best technical idea in the piece. A teacher model can guide a cheaper student model, and the same skill can run across OpenAI, VertexAI, or custom endpoints. That is a sensible architecture for teams balancing quality and cost. It is especially useful when a strong model can bootstrap a weaker one for repetitive tasks like sentiment classification or document extraction. The framework earns credit here because it treats model choice as an execution detail rather than a product constraint.
Still, this is orchestration, not new intelligence. The article’s examples are all variations on supervised task automation: classify reviews, moderate content, annotate medical reports, extract financial fields, enrich catalogs. Those are important tasks, but they are familiar ones. Adala succeeds by making them easier to package and reuse, not by changing the fundamental nature of the work. Calling that an autonomous breakthrough oversells the product. It is a better control plane for LLM-assisted labeling.
The best use case is high-volume, rules-heavy annotation, not open-ended reasoning
Look at the examples the article itself chooses. Sentiment analysis, moderation, medical annotation, financial extraction, catalog enrichment. Each one has a bounded label space, a clear business schema, and a practical need for consistency. That is where Adala fits. A team with thousands or millions of examples can use it to standardize output, reduce repetitive manual review, and keep model behavior aligned with policy or domain rules. The framework is strongest when the job is to map inputs into a known structure.

That also defines its limit. Once the task becomes ambiguous, policy-driven, or deeply contextual, the promise of autonomous labeling gets brittle. A model can learn patterns from examples, but it cannot invent the business definition of edge cases. If your moderation policy is unclear, your medical ontology is unstable, or your finance team disagrees on what counts as a material change, no agent framework solves that. It only reproduces the disagreement faster. Adala is a force multiplier for clarity, not a substitute for it.
The counter-argument
Supporters will argue that this is exactly why Adala matters. Most enterprise AI projects fail not because the models are weak, but because data preparation is slow, expensive, and inconsistent. From that angle, a framework that turns labeled examples into reusable skills is a genuine productivity leap. The article makes that case well: one skill can be deployed across runtimes, the agent can learn iteratively, and teams can keep output constrained to a taxonomy. For organizations drowning in annotation backlog, that is a serious improvement.
That argument is right about the pain, but wrong about the cure. Adala does not eliminate the bottleneck; it shifts it upstream into dataset design, evaluation, and governance. That is still a win, because those are the right places to concentrate human effort. But it means the product is infrastructure for disciplined teams, not a shortcut around expertise. If you treat it as autonomous labor, you will get brittle labels at scale. If you treat it as an opinionated supervised learning system for data pipelines, it is useful.
What to do with this
If you are an engineer or data scientist, use Adala when the task is repetitive, schema-bound, and already backed by trusted labels. Start with a narrow taxonomy, pin your model version, measure against a held-out set, and inspect failure cases before you scale. If you are a PM or founder, do not sell it internally as an AI replacement for labeling teams. Sell it as a way to reduce annotation cost, standardize output, and turn manual review into higher-value exception handling. That framing is honest, and it is the one that will survive production.
// Related Articles
- [TOOLS]
OpenClaw with Ollama turns Telegram into a bot
- [TOOLS]
Aliyun Bailian Token Plan turns credits into agents
- [TOOLS]
One API gateway turns six AI APIs into one
- [TOOLS]
OpenAI FDEs turn broken agents into shipped systems
- [TOOLS]
Anthropic’s daily brief turns news into a workflow
- [TOOLS]
Claude Reflect turns usage into retention