為什麼 MLOps 比 DevOps 更重要:AI 系統的可靠性關鍵
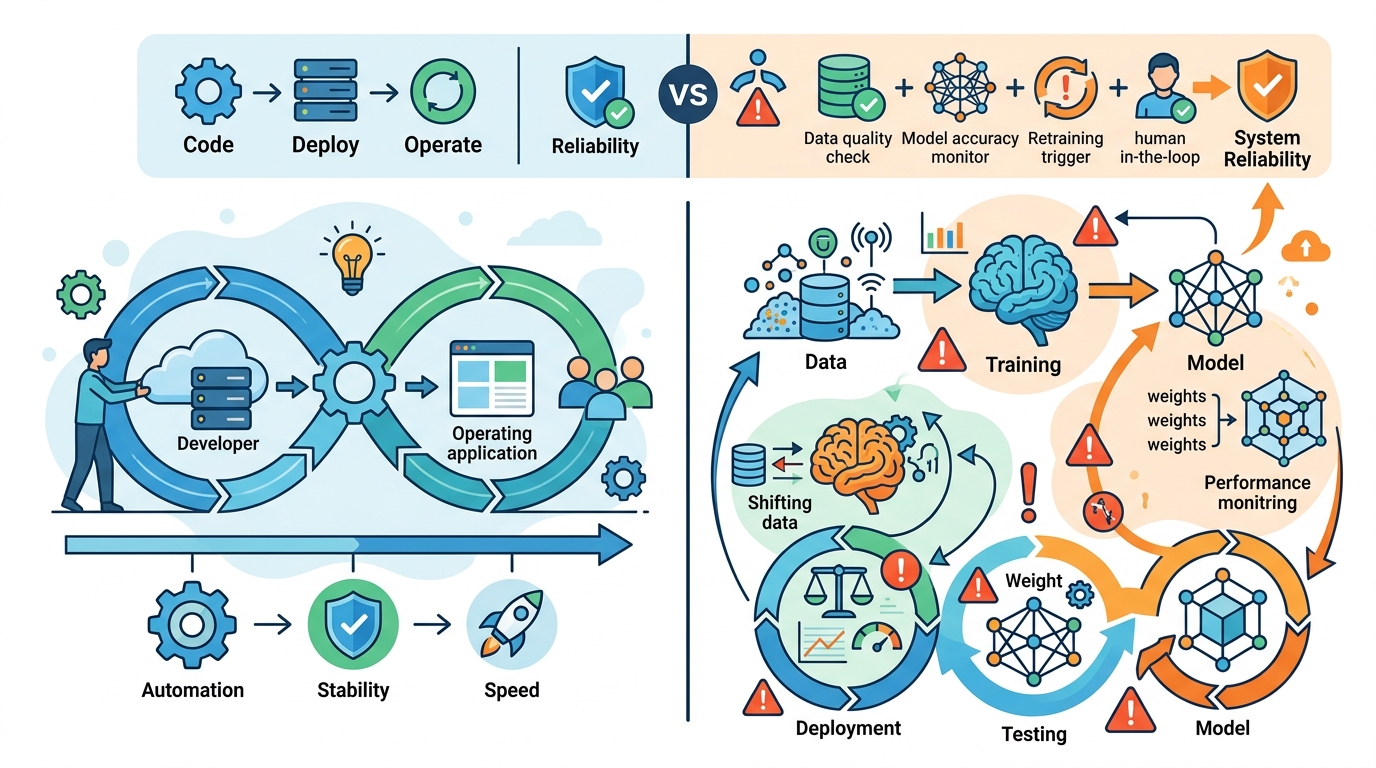
MLOps 不是 DevOps 的附屬品,而是 AI 系統在生產環境中保持可重現、可監控、可回滾的必要紀律。
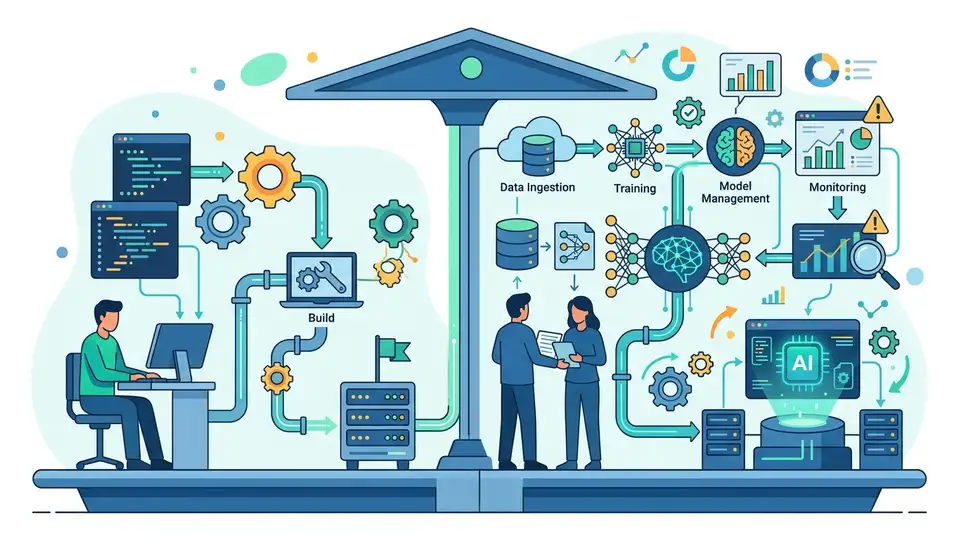
MLOps 讓訓練過的模型在生產環境中保持可重現、可監控、可回滾。
我支持的立場很直接:對 AI 系統來說,MLOps 比 DevOps 更重要,因為模型上線後的主要風險不是程式碼部署,而是資料漂移、訓練不一致與效能悄悄退化。
第一個論點:模型不是一般軟體
訂閱 AI 趨勢週報
每週精選模型發布、工具應用與深度分析,直送信箱。不定期,不騷擾。
不會寄垃圾信,隨時可取消。
一個 Web API 重新從原始碼建置,通常能得到相同輸出;但模型不是這樣。它的行為同時受訓練資料、特徵前處理、隨機種子、套件版本與線上輸入分布影響。只要其中一環變了,結果就可能不同。這也是為什麼把 MLOps 簡化成「AI 版 DevOps」是錯位的,DevOps 解的是交付問題,MLOps 解的是會學習的資產在全生命週期中的風險。
這種風險不是理論上的。很多團隊在開發環境裡看到漂亮的指標,部署後卻在 2 到 3 個月內因資料分布改變而持續掉點,直到客服、轉換率或風控指標先出事,工程團隊才回頭找原因。若只版本控制程式碼,卻不版本化資料與訓練流程,你保存的只是最不重要的部分。
第二個論點:手工 ML 維運會直接燒錢
成本不是抽象的。TechnoLynx 指出,人工部署一個模型平均要花 2 到 4 小時工程時間;若每週重訓一次,一個模型一年就會吃掉約 100 到 200 小時,還沒算除錯、監控與回滾。若公司有 10 個模型,這相當於 1 到 2 名全職工程師把時間花在搬運與協調,而不是改善產品。
更糟的是,沒有 MLOps 的團隊通常會雙重付費。第一次是模型品質滑落後的事故處理,第二次是被迫在壓力下補齊 pipeline、model registry、監控與權限控管。這不是「先做產品、之後再補流程」的聰明做法,而是把技術債延後到最昂貴的時點才一次清算。當第一個 production model 已經影響營收、風險或使用者體驗時,MLOps 就不是選配,而是必要基礎設施。
反方可能怎麼說
最強的反對意見是:MLOps 會變成過早的官僚主義。若團隊還在做概念驗證,沒有 production model、沒有重訓迴圈,也沒有值得追蹤的漂移指標,這時候上 registry、workflow engine 和監控儀表板,只會拖慢實驗速度,讓團隊把時間花在工具上,而不是驗證模型到底有沒有商業價值。
這個批評成立,但只成立在前期。當模型只是一次性實驗、團隊很小、業務影響也低時,重型 MLOps 確實是負擔。問題在於,很多公司把這個前期狀態誤判成長期狀態,等模型真的進入生產、開始影響收入後,才被迫補上可重現性、回滾與監控。那時候再補,不叫精實,叫補考。
所以我的反駁不是否認限制,而是把邊界講清楚:MLOps 不該一開始就做滿,但只要模型已經進入 production,而且失誤會造成實際成本,就必須把資料、訓練、部署與監控納入同一套工程紀律。對 AI 系統而言,忽略 MLOps 不是省事,而是把未來事故外包給自己。
你能做什麼
如果你是工程師,先做三件事:把訓練流程變成可重現、把模型與資料 lineage 存起來、把環境與依賴鎖定,然後在第一次事故前就加上監控與回滾機制;如果你是 PM 或創辦人,直接問兩個數字:一個壞模型每週會造成多少損失,維持它活著又要花多少人時。只要答案已經可觀,就該把 MLOps 當成產品基礎設施,而不是流程裝飾,並且從最小可觀測、可回復的控制開始,一次只成熟一個階段。